[논문 리뷰] Why Linguistics Will Thrive in the 21st Century: A Reply to Piantadosi (2023)
본 논문은 Piantadosi의 주장을 비판한다. 언어 모델이 촘스키를 반박한다고 주장하는데, 이는 (1) 핵심 학습 이론적 한계 하에서 작은 데이터로의 무제한 학습이 불가능하고, (2) LLM은 언어의 과학적 이론이 아니며, (3) 다중 실현성은 AI의 모방이 인간 인지와 같지 않음을 의미한다. 생성적 언어학은 여전히 필수적이다.
We present a critical assessment of Piantadosi's (2023) claim that "Modern language models refute Chomsky's approach to language," focusing on four main points. First, despite the impressive performance and utility of large language models (LLMs), humans achieve their capacity for language after exposure to several orders of magnitude less data. The fact that young children become competent, fluent speakers of their native languages with relatively little exposure to them is the central mystery of language learning to which Chomsky initially drew attention, and LLMs currently show little promise of solving this mystery. Second, what can the artificial reveal about the natural? Put simply, the implications of LLMs for our understanding of the cognitive structures and mechanisms underlying language and its acquisition are like the implications of airplanes for understanding how birds fly. Third, LLMs cannot constitute scientific theories of language for several reasons, not least of which is that scientific theories must provide interpretable explanations, not just predictions. This leads to our final point: to even determine whether the linguistic and cognitive capabilities of LLMs rival those of humans requires explicating what humans' capacities actually are. In other words, it requires a separate theory of language and cognition; generative linguistics provides precisely such a theory. As such, we conclude that generative linguistics as a scientific discipline will remain indispensable throughout the 21st century and beyond.
연구 동기 및 목표
- 현대의 언어 모델이 원어 학습 제약과 촘스키의 견해를 반박하는지 평가한다.
- 계산적 학습 이론 결과를 고려할 때 작은 데이터로의 무제한 학습이 불가능하다고 주장한다.
- LLMs가 언어와 인지의 과학적 이론이 될 수 있다는 주장 평가.
- 인간의 언어적 능력이 언어와 인지에 대한 별도의 이론을 필요로 하는 이유를 강조한다.
- 21세기에도 생성적 언어학의 지속적인 필수성을 주장한다.
제안 방법
- Piantadosi(2023)의 LLM과 언어 학습에 관한 주장을 비판적으로 분석한다.
- 계산적 학습 이론(CLT)을 활용하여 개념 계열, 데이터 프레젠테이션, 계산 자원 간의 균형(trade-offs)을 설명한다.
- LLM의 실증적 결과가 편향과 평가 데이터의 잠재적 지름길(shortcuts)에 의해 어떻게 영향을 받는지 설명한다.
- 테스트 세트의 예시(예: BLiMP)를 사용하여 성능이 실제 문법 지식이 아닌 지름길을 반영할 수 있음을 설명한다.
- 피상적 행태적 유사성과 기저 인지 메커니즘을 구분하기 위해 다중 실현성에 대해 논의한다.]
- 리스트 항목의 형식에 맞춰 한글로 작성되었으므로 원문과의 일관성을 유지합니다.
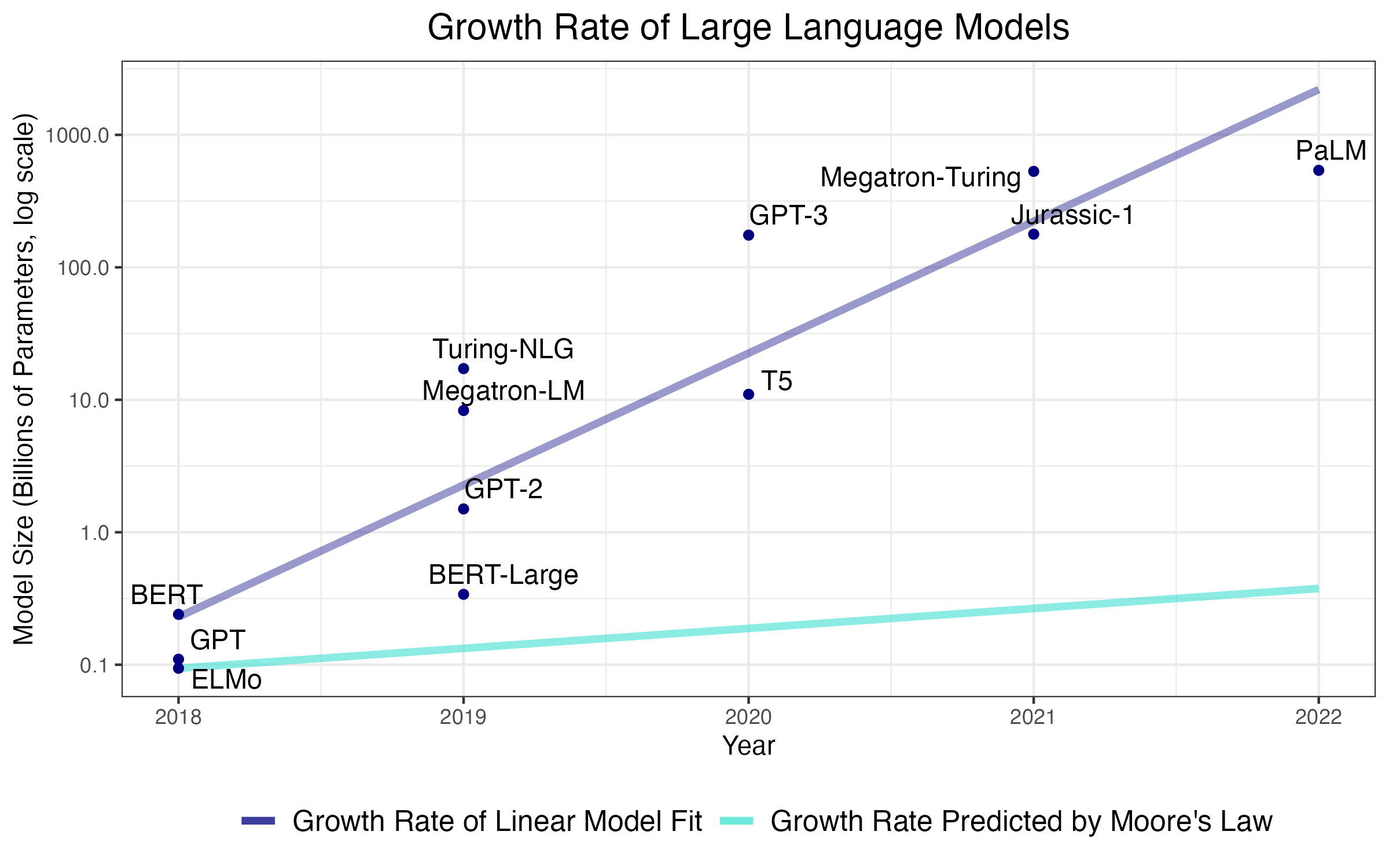
실험 결과
연구 질문
- RQ1LLMs가 인간 노출과 비교할 수 있는 데이터 규모에서의 무제한 학습을 보여주는가?
- RQ2LLMs가 언어와 인지의 신뢰할 수 있는 과학적 이론인가, 아니면 단지 출력을 예측하는가?
- RQ3예측을 넘어 해석 가능한 설명을 제공하는 언어와 인지의 별도 이론(예: 생성적 언어학)이 가능할까?
- RQ4LLMs가 지름길을 이용하는 것이 아니라 인간과 유사한 언어 지식을 인코딩한다는 것을 주장하려면 어떤 증거가 필요한가?
- RQ5계산적 학습 이론의 시각에서 ‘작은 데이터’ 학습 주장을 어떻게 해석해야 하는가?
주요 결과
- 그럴듯한 인간 유사 데이터 크기에서의 무제한 학습은 학습의 기본 계산 법칙 하에서 가능성이 낮다.
- 대형 언어 모델은 중요한 수준의 구조적 편향과 거대한 데이터에 의존하며, 작은 데이터에서 인간과 같이 학습한다는 아이디어에 도전한다.
- 구문에 대한 평가 벤치마크는 종종 진정한 문법 지식을 드러내지 않는 지름길을 허용하여 LLM에서의 인간과 유사한 언어학에 대한 결론에 의문을 제기한다.
- 다중 실현성은 동일한 성능이 AI와 인간 인지 사이에 동일한 기제를 의미하지 않음을 보여준다.
- AI 능력을 해석하려면 언어와 인지의 별도 이론이 필요함을 보여주며, 생성적 언어학의 지속적 역할을 뒷받침한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.