[논문 리뷰] Why think step by step? Reasoning emerges from the locality of experience
논문은 local 구조가 있는 학습 데이터일 때 체인-오브-생각(chain-of-thought) 추론이 언어 모델에 도움이 되며, 로컬 의존성을 연결함으로써 효율적 추론을 가능하게 한다고 보여준다; 완전히 관찰된 데이터나 비-로컬 데이터의 경우 추론은 거의 이점이 없거나 전혀 없다.
Humans have a powerful and mysterious capacity to reason. Working through a set of mental steps enables us to make inferences we would not be capable of making directly even though we get no additional data from the world. Similarly, when large language models generate intermediate steps (a chain of thought) before answering a question, they often produce better answers than they would directly. We investigate why and how chain-of-thought reasoning is useful in language models, testing the hypothesis that reasoning is effective when training data consists of overlapping local clusters of variables that influence each other strongly. These training conditions enable the chaining of accurate local inferences to estimate relationships between variables that were not seen together in training. We prove that there will exist a "reasoning gap", where reasoning through intermediate variables reduces bias, for the simple case of an autoregressive density estimator trained on local samples from a chain-structured probabilistic model. We then test our hypothesis experimentally in more complex models, training an autoregressive language model on samples from Bayes nets but only including a subset of variables in each sample. We test language models' ability to match conditional probabilities with and without intermediate reasoning steps, finding that intermediate steps are only helpful when the training data is locally structured with respect to dependencies between variables. The combination of locally structured observations and reasoning is much more data-efficient than training on all variables. Our results illustrate how the effectiveness of reasoning step by step is rooted in the local statistical structure of the training data.
연구 동기 및 목표
- 중간 변수를 통한 추론이 언어 모델의 추론 성능을 개선할 수 있는 이유를 동기로 제시하고 형식화한다.
- 로컬 구조화된 관찰을 가진 조건부 추론을 위한 Bayes-net 기반 프레임워크를 형식화한다.
- 연쇄 구조 모델에서 추론이 편향 감소를 가져오는 이론적 차이를 증명한다.
- 합성 Bayes-net으로 학습된 자기회귀 트랜스포머를 사용하여 중간 추론이 언제 도움이 되는지 실험적으로 검증한다.
제안 방법
- 변수의 로컬 이웃을 생성하는 관찰 분포를 형식화한다.
- 조건부 확률에 대해 직접 예측, scaffolded generation, 자유 생성의 세 가지 추정기를 도출한다.
- 연쇄 구조에서 중간 변수를 이용한 추론이 비인접한 변수 쌍의 편향을 감소시킨다는 '추론 격차(reasoning gap)'를 증명한다.
- 로컬 구조를 가진 합성 Bayes-net 데이터로 autoregressive transformers를 학습하고 보류된 쌍에 대한 조건부 확률을 평가한다.
- 로컬 구조가 있는, 완전히 관찰된, 잘못 지정된 로컬성 설정에서 추정기를 MSE(Mean Squared Error)로 비교한다.
- 데이터 효율성 및 추론이 불필요하거나 해로운 때를 분석한다.
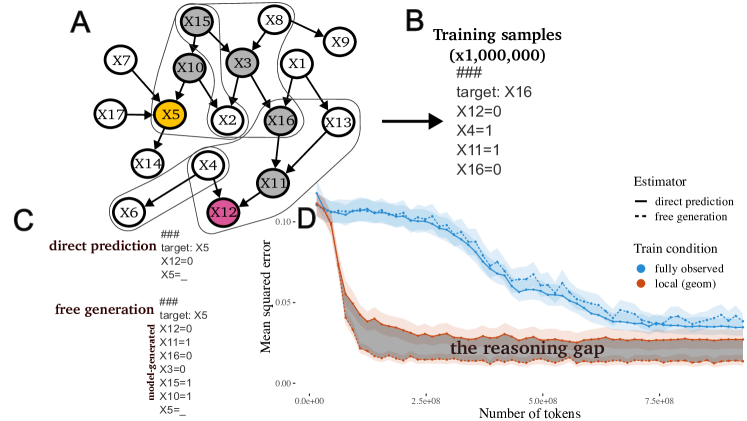
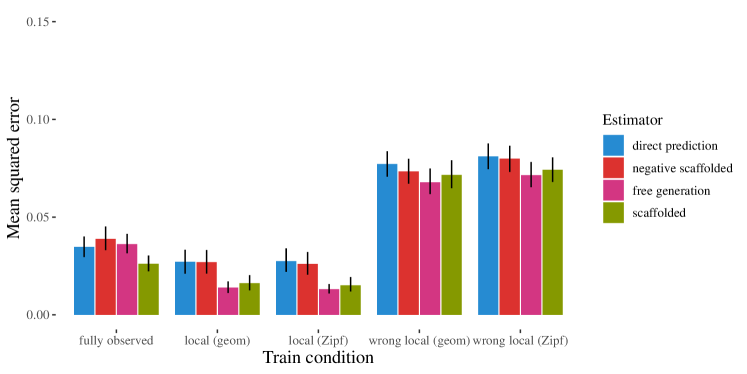
실험 결과
연구 질문
- RQ1학습 데이터의 로컬성 조건이 어떤 때 중간 추론 단계가 조건부 추론의 편향을 줄이는가?
- RQ2로컬 구조에서 자기 생성된 중간 추론이 직접 예측보다 자기회귀 모델이 실제 조건부 확률에 더 잘 일치하도록 돕는가?
- RQ3완전하게 관찰된 데이터로 학습하는 것과 비교했을 때 추론 기반 추론은 데이터 효율성이 얼마나 높은가?
- RQ4언제 추론이 도움이 되지 않거나 성능을 해치는가?
- RQ5어떤 요인들(예: 로컬성 강도, 변수 간 거리)이 chain-of-thought 추론의 유용성을 조절하는가?
주요 결과
- 중간 변수들을 통한 추론은 학습 데이터에 강한 로컬 구조가 있을 때 비인접한 변수 쌍의 편향을 감소시킨다.
- 로컬 구조 학습 데이터에서 자유 생성(free generation)과 scaffolded generation이 직접 예측보다 우수하다.
- 데이터가 완전히 관찰되거나 로컬 구조가 잘못된 경우 추론은 거의 이점이 없다.
- 로컬 구조 데이터와 chain-of-thought 추론이 결합되면 데이터 효율성이 높아져 적은 학습으로 거의 실제 조건부 확률에 근접한다.
- 관찰된 변수가 자주 함께 발생하는 경우 직접 예측이 이미 실제 확률과 일치할 수 있어 이러한 경우 추론의 필요성이 줄어든다.
- 추론 체인을 재샘플링하는 것(multiple Monte Carlo 샘플)은 추정 분산을 줄이는 데 도움이 된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.