[논문 리뷰] Why Warmup the Learning Rate? Underlying Mechanisms and Improvements
이 논문은 학습률 워밍업의 주요 이점이 최적화기가 더 잘 조건화된 영역으로 밀어넣어 더 큰 목표 학습률을 가능하게 한다는 점을 보여주고; SGD와 Adam을 분석하고, 모드(레짐)를 식별하며, 워밍업을 줄이거나 제거하기 위한 초기화 전략을 제안한다.
It is common in deep learning to warm up the learning rate $η$, often by a linear schedule between $η_{ ext{init}} = 0$ and a predetermined target $η_{ ext{trgt}}$. In this paper, we show through systematic experiments using SGD and Adam that the overwhelming benefit of warmup arises from allowing the network to tolerate larger $η_{ ext{trgt}}$ {by forcing the network to more well-conditioned areas of the loss landscape}. The ability to handle larger $η_{ ext{trgt}}$ makes hyperparameter tuning more robust while improving the final performance. We uncover different regimes of operation during the warmup period, depending on whether training starts off in a progressive sharpening or sharpness reduction phase, which in turn depends on the initialization and parameterization. Using these insights, we show how $η_{ ext{init}}$ can be properly chosen by utilizing the loss catapult mechanism, which saves on the number of warmup steps, in some cases completely eliminating the need for warmup. We also suggest an initialization for the variance in Adam which provides benefits similar to warmup.
연구 동기 및 목표
- 학습률 워밍업이 다양한 네트워크 아키텍처, 초기화, 최적화 도구에서 왜 훈련에 도움이 되는지 조사한다.
- 워밍업 다이나믹스와 손실 평면의 샤프니스 간의 상호 작용을 특징지운다.
- 워밍업이 더 큰 목표 학습률 사용 가능성과 일반화에 미치는 영향을 정량화한다.
- 워밍업의 필요를 줄이거나 제거하기 위한 초기화 전략을 제안한다.
- 전처형된 샤프니스를 줄이기 위해 Adam 초기화 방법(GI-Adam)을 실용적으로 제시한다.
제안 방법
- FCN, ResNet, Transformer에 걸친 CIFAR-10/100, TinyImageNet, WikiText-2에 대한 체계적 실증 연구.
- 선형 워밍업과 다양한 매개변수화(SP, μP)를 사용한 SGD, 모멘텀을 가진 SGD, Adam의 분석.
- 안정성 임계치를 평가하기 위한 샤프니스(λ^H)와 사전 조정 샤프니스(λ^{P^{-1}H})의 정의 및 사용.
- 훈련 불안정성과 워밍업 효과를 설명하는 Catapult/자기안정화 프레임워크.
- 두 번째 모멘트 g0^2를 초기화하여 사전 조정 샤프니스를 감소시키는 GI-Adam의 도입.
- Forward pass와 이진/지수 탐색을 통해 η_c를 추정하는 η_init 탐색 방법의 제안.
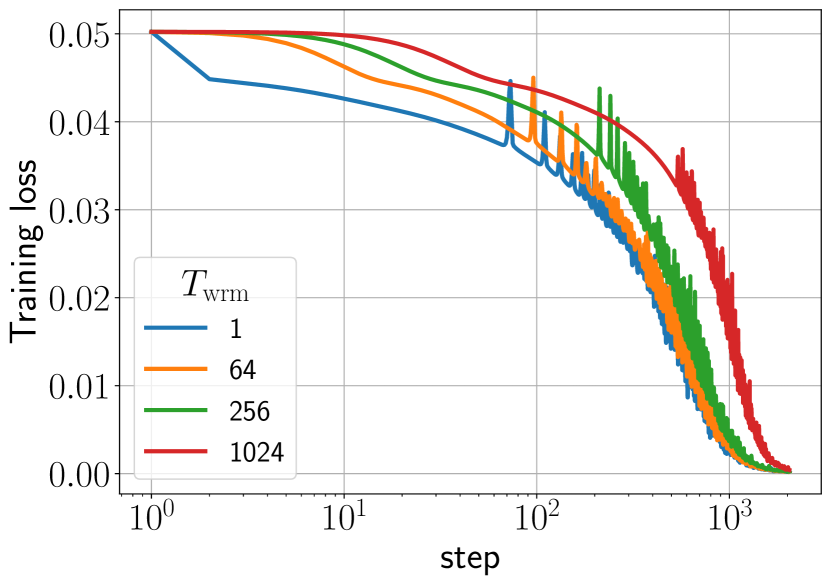
실험 결과
연구 질문
- RQ1학습률 워밍업이 훈련 성능을 향상시키는 주된 기계는 무엇인가?
- RQ2워밍업 다이나믹스가 SGD, SGD with momentum, Adam 하에서 샤프니스 진화와 어떤 상호 작용을 하는가?
- RQ3워밍업이 로스 평면의 더 완만한 영역으로 이동시켜 더 큰 목표 학습률을 허용할 수 있는가?
- RQ4초기화 및 매개변수화(SP 대 μP)가 워밍업 레짐과 효과성에 어떤 영향을 미치는가?
- RQ5GI-Adam, η_init ≈ η_c와 같은 원리적 초기화 전략으로 워밍업을 줄이거나 제거할 수 있는가?
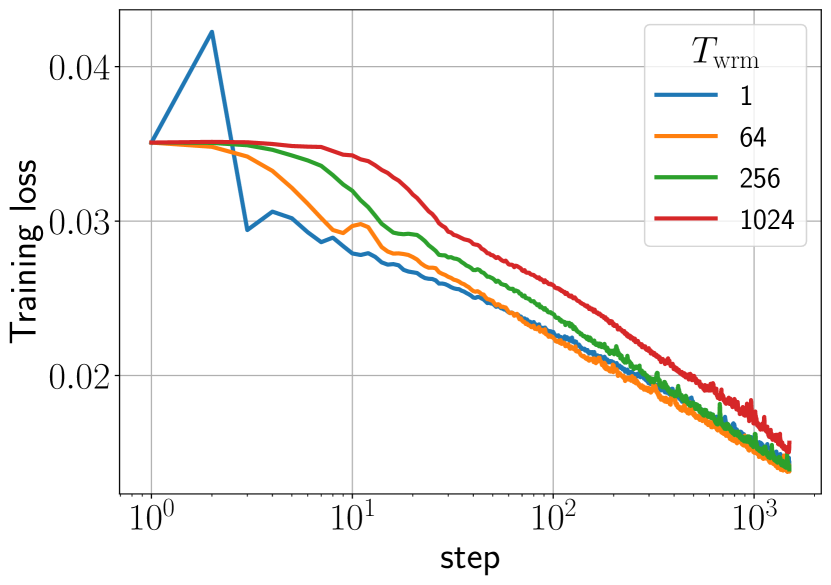
주요 결과
- 워밍업은 네트워크가 증가된 η_trgt를 견딜 수 있도록 하여 더 높은 목표 학습률을 허용함으로써 주로 이점을 가져온다.
- 두 가지 주요 레짐을 관찰: 자연스러운 점진적 샤프닝(Natural Progressive Sharpening)과 자연스러운 샤프니스 감소(Natural Sharpness Reduction)로, 워밍업이 손실 평면과 상호 작용하는 방식을 결정한다.
- Adam의 경우 주요 불안정성은 사전 조정 샤프니스와 연결되며, 워밍업은 λ^{P^{-1}H}를 감소시켜 큰 캐토폴트를 완화한다.
- GI-Adam은 gradient 제곱으로 두 번째 모멘트를 초기화하여 초기의 사전 조정 샤프니스를 감소시키고 워밍업과 유사한 안정성을 개선한다.
- Forward pass를 이용해 η_c를 추정하는 η_init 선택 방법은 워밍업 시간을 크게 줄이거나 일부 경우 제거할 수 있다.
- 더 긴 워밍업은 일반적으로 불안정성 임계치를 지연시키고 캐토폴트를 완만하게 만들어 로버스트니스와 일반화를 향상시킨다.
- 최종 성능은 주로 η_trgt에 의해 결정되며, 워밍업 지속 시간은 로버스트니스와 사용 가능한 학습률 범위를 미세하게 조정한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.