[논문 리뷰] YaRN: Efficient Context Window Extension of Large Language Models
YaRN은 RoPE 기반 LLM의 맥락 창을 효율적으로 확장하기 위해 추론 시 주의 온도 조정과 함께 타깃 RoPE 보간 방법을 도입하여 최소한의 미세조정 및 데이터로 최신 상태의 확장을 달성합니다. 이 방법은 LLaMA-2 모델에서 최대 128k 맥락을 가능하게 하며, 이전의 전 맥락 창 확장 방법보다 강한 전달 및 긴 시퀀스 성능을 보입니다.
Rotary Position Embeddings (RoPE) have been shown to effectively encode positional information in transformer-based language models. However, these models fail to generalize past the sequence length they were trained on. We present YaRN (Yet another RoPE extensioN method), a compute-efficient method to extend the context window of such models, requiring 10x less tokens and 2.5x less training steps than previous methods. Using YaRN, we show that LLaMA models can effectively utilize and extrapolate to context lengths much longer than their original pre-training would allow, while also surpassing previous the state-of-the-art at context window extension. In addition, we demonstrate that YaRN exhibits the capability to extrapolate beyond the limited context of a fine-tuning dataset. Code is available at https://github.com/jquesnelle/yarn
연구 동기 및 목표
- RoPE 기반 트랜스포머 모델의 맥락 창 확장을 사전 학습 한계를 넘어 확장하도록 동기를 부여하고 가능하게 한다.
- 주목적 RoPE 보간 방법인 YaRN을 제안하며, 높은 주파수 정보와 국소 거리를 보존하기 위해 주의(attention) 온도 스케일링을 적용한다.
- 계산 효율적인 미세조정(약 데이터의 0.1%) 및 효과적인 제로샷/추론 시점 외삽을 입증한다.
- 장기 시퀀스 perplexity, 패스키 검색 및 표준 벤치마크에 대해 LLaMA/Llama 2 계열에서 YaRN을 평가하여 강건성과 전달 가능성을 보인다.
제안 방법
- YaRN을 RoPE 주파수 전반에 걸친 타깃 보간인 NTK-by-parts 보간과 길이 스케일링 트릭으로 구현된 주의 온도 스케일링(로짓 온도 t)의 결합으로 공식화한다.
- RoPE 차원을 파장 λ_d과 맥락 길이 L에 따라 선택적으로 보간하도록 g(m)과 h(θ_d)를 정의하고, γ 램프 함수를 이용해 보간 여부를 결정한다.
- α, β 매개변수를 사용한 NTK-by-parts로 RoPE 차원을 r(d)=L/λ_d로 분류하고 적절할 때 선형 보간을 s로 적용하되 고주파 차원은 변화시키지 않는다.
- 추론에서 전방 패스를 거칠게 늘려 사전학습 한계를 넘어가도록 매 순전파마다 스케일 s를 업데이트하는 동적 스케일링(Dynamic NTK)을 적용한다.
- 작은 미세조정 데이터셋(PG19, 확장 단계당 64k 토큰)을 사용하고 낮은 스텝(스=16일 때 400스텝, 스=32일 때 200스텝)과 표준 최적화(AdamW, LR=2e-5)로 학습한다.
- Table 2, Figure 1 및 Tables 1–5를 재현하기 위한 코드와 평가 도구가 포함된 재현 가능한 설정을 제공한다.
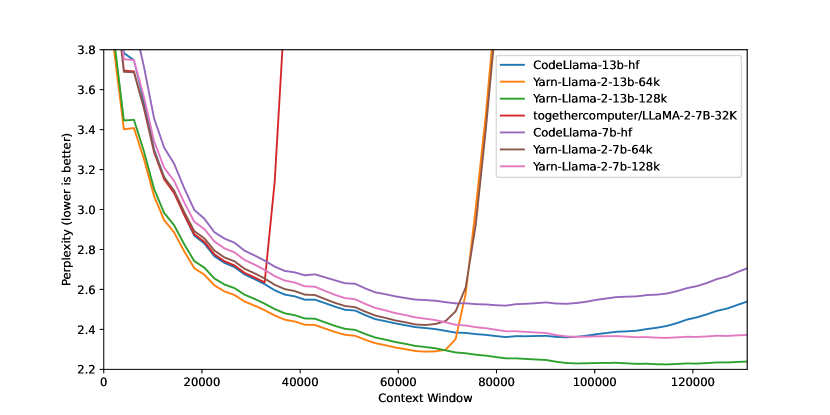
실험 결과
연구 질문
- RQ1RoPE 기반 LLM이 사전 학습 창보다 훨씬 긴 맥락 길이에 대해 컴퓨트 효율적인 보간 방법으로 일반화할 수 있는가?
- RQ2타깃 보간(NTK-by-parts)과 추론 시 스케일링(YaRN)을 결합한 방법이 장맥락 작업에서 PI 및 NTK 인식 방식과 비교하여 어떤 성능을 보이는가?
- RQ3YaRN의 전달 및 외삽 능력은 7B, 13B 모델 스케일에서 어떻게 나타나며 제한된 데이터로의 미세조정 후에는 어떠한가?
- RQ4YaRN이 맥락 창을 매우 길게 확장하더라도 표준 벤치마크에서의 성능이 유지되는가?
- RQ5Dynamic Scaling을 사용할 때 재학습 없이 맥락을 더 확장하는 실용적인 제로샷/추론 시점 방법이 존재하는가?
주요 결과
| Extension | Trained Tokens | Context Window | 2048 | 4096 | 6144 | 8192 | 10240 |
|---|---|---|---|---|---|---|---|
| PI (s=2) | 1B | 8k | 3.92 | 3.51 | 3.51 | 3.34 | 8.07 |
| NTK (θ=20k) | 1B | 8k | 4.20 | 3.75 | 3.74 | 3.59 | 6.24 |
| YaRN (s=2) | 400M | 8k | 3.91 | 3.50 | 3.51 | 3.35 | 6.04 |
- YaRN은 사전학습 데이터의 약 0.1% 수준의 데이터와 16s에서 400스텝, 32s에서 200스텝의 학습으로도 최첨단 맥락 창 확장을 달성한다.
- YaRN은 LLaMA/Llama 2 모델이 128k 맥락으로 외삽되도록 하며 32s에서 128k에서도 perplexity 개선이 지속된다.
- PI 및 NTK 인식 기반 벤치마크와 비교할 때 YaRN은 장맥락 perplexity 및 패스키 검색 성능이 우수하며 표준 벤치마크에서의 저하가 최소화된다.
- Dynamic NTK(Dynamic Scaling)를 통해 미세조정 없이 맥락 확장이 가능하며, YaRN의 NTK-by-parts 및 온도 스케일링은 다양한 맥락 길이에서도 성능을 유지한다.
- YaRN은 강력한 전이 학습을 보여주며 s=16에서 s=32로의 더 큰 맥락 확장을 전이 학습을 통해 가능하게 하고, s=16 모델의 재학습 없이 보간 임베딩을 전달한다.
- Open LLM 벤치마크에서 YaRN 모델은 Llama 2 베이스라인에 비해 성능 저하가 미미하며, s=16에서 s=32 사이의 평균 소폭 하락이 나타난다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.