[논문 리뷰] Yi: Open Foundation Models by 01.AI
Yi는 6B 및 34B 언어 모델을 채팅, 긴 컨텍스트, 깊이 확장, 및 비전-언어 변형으로 확장했고, 데이터 품질과 확장 가능한 인프라를 강조하여 더 낮은 비용으로 GPT-3.5 수준의 성능에 도달하려 한다.
We introduce the Yi model family, a series of language and multimodal models that demonstrate strong multi-dimensional capabilities. The Yi model family is based on 6B and 34B pretrained language models, then we extend them to chat models, 200K long context models, depth-upscaled models, and vision-language models. Our base models achieve strong performance on a wide range of benchmarks like MMLU, and our finetuned chat models deliver strong human preference rate on major evaluation platforms like AlpacaEval and Chatbot Arena. Building upon our scalable super-computing infrastructure and the classical transformer architecture, we attribute the performance of Yi models primarily to its data quality resulting from our data-engineering efforts. For pretraining, we construct 3.1 trillion tokens of English and Chinese corpora using a cascaded data deduplication and quality filtering pipeline. For finetuning, we polish a small scale (less than 10K) instruction dataset over multiple iterations such that every single instance has been verified directly by our machine learning engineers. For vision-language, we combine the chat language model with a vision transformer encoder and train the model to align visual representations to the semantic space of the language model. We further extend the context length to 200K through lightweight continual pretraining and demonstrate strong needle-in-a-haystack retrieval performance. We show that extending the depth of the pretrained checkpoint through continual pretraining further improves performance. We believe that given our current results, continuing to scale up model parameters using thoroughly optimized data will lead to even stronger frontier models.
연구 동기 및 목표
- 대규모로 엄선된 이중언어 말뭉치로 학습된 6B 및 34B 고성능 언어 모델을 입증한다.
- 채팅, 긴 컨텍스트(200K), 깊이 확장 및 비전-언어 변형으로의 확장을 선보인다.
- 강한 벤치마크와 인간 선호를 가능하게 하는 데이터 품질, 전처리 및 정렬 전략을 조사한다.
- 사전 학습, 미세 조정 및 효율적 서빙을 지원하는 확장 가능한 인프라 및 최적화 기법을 제공한다.
제안 방법
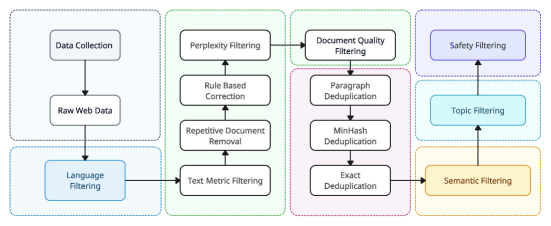
- 3.1T의 이중언어 영어/중국어 토큰에서 캐스케이드 중복 제거 및 품질 필터링으로 6B 및 34B 디코더-전용 트랜스포머를 사전 학습한다.
- Long-context 확장을 위해 Grouped-Query Attention(GQA), SwiGLU 활성화 및 Rotary/RoPE 기반 위치 임베딩과 RoPE ABF를 도입한다.
- ChatML 형식 프롬프트와 계층적 데이터 혼합 그리드 검색을 사용하여 작고 고품질의 지시 데이터셋(<10K)으로 미세조정한다.
- 장-시퀀스 프리트레이닝을 통한 200K 컨텍스트 길이 확장, 비전 인코더를 통한 비전-언어 정렬 및 지속적 사전 학습을 통한 깊이 확장을 통해 기능을 확장한다.
- 4비트/8비트 양자화, 동적 배치, PagedAttention를 사용한 크로스-클라우드 스케줄링, 회복력 있는 학습 및 효율적 추론을 위한 풀스택 인프라를 구축한다.
실험 결과
연구 질문
- RQ1강력한 데이터 큐레이션을 고려할 때 소형에서 중형 규모의 모델(6B/34B)이 표준 벤치마크에서 GPT-3.5 수준의 성능을 달성할 수 있는가?
- RQ2200K로 컨텍스트 길이를 늘리고 비전-언어 정렬을 추가하는 것이 검색 및 다중모달 역량을 크게 향상시키는가?
- RQ3지속적 사전 학습을 통한 깊이 확장이 모델 성능에 미치는 영향은 무엇인가?
- RQ4데이터 품질과 표적 미세조정이 과제 전반의 인간 선호도와 자동 평가에 어떤 영향을 미치는가?
- RQ5대형 언어 모델의 사전 학습, 미세조정 및 서빙을 비용 효율적으로 가능하게 하는 인프라 및 최적화 기법은 무엇인가?
주요 결과
| 모델 | 크기 | MMLU | BBH | C-Eval | CMMLU | Gaokao | CR | RC | 코드 | 수학 |
|---|---|---|---|---|---|---|---|---|---|---|
| Yi | 6B | 63.2 | 42.8 | 72.0 | 75.5 | 72.2 | 72.2 | 68.7 | 21.1 | 18.6 |
| Yi | 34B | 76.3 | 54.3 | 81.4 | 83.7 | 82.8 | 80.7 | 76.5 | 32.1 | 40.8 |
- Yi-34B가 많은 벤치마크에서 GPT-3.5 수준의 성능에 근접하고 평가에서 강한 인간 선호 신호를 제공한다.
- Yi-34B는 긴 컨텍스트 학습 및 양자화 이후 최소한의 성능 손실로 200K 컨텍스트 길이에 도달한다.
- 4비트 양자화와 8비트 KV 캐시로 MMLU/CMMLU와 같은 벤치마크에서 정확도 손실은 무시할 정도로 메모리 절감이 크다.
- 맥락 내 학습 실험은 더 큰 규모에서 출현하는 능력을 시사하며, Yi-34B가 다중 매개변수 추론 과제에서 뛰어난 성능을 보인다.
- 비전-언어 확장은 시각 표현을 언어 의미 공간에 정렬하여 다중 모달 기능을 가능하게 한다.
- Yi-34B-Chat은 자동 평가와 인간 평가에서 강한 결과를 보이며, 특히 수학 관련 및 코드 유사 작업에서 더 작은 기준 대비 두드러진 성과를 보인다.
![Figure 2: Yi’s pre-training data mixture. Overall our data consist of 3.1T high-quality tokens in Both English and Chinese, and come from various sources. Our major differences from existing known mixtures like LLaMA [ 76 ] and Falcon [ 56 ] are that we are bilingual, and of higher quality due to ou](https://ar5iv.labs.arxiv.org/html/2403.04652/assets/x2.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.