[논문 리뷰] YOLOv10: Real-Time End-to-End Object Detection
YOLOv10은 일관된 이중 할당과 전체적 효율-정확도 설계를 통해 NMS-없는 학습을 도입하여 모델 규모 전반에서 최첨단 엔드투엔드 실시간 객체 탐지 성능을 달성합니다.
Over the past years, YOLOs have emerged as the predominant paradigm in the field of real-time object detection owing to their effective balance between computational cost and detection performance. Researchers have explored the architectural designs, optimization objectives, data augmentation strategies, and others for YOLOs, achieving notable progress. However, the reliance on the non-maximum suppression (NMS) for post-processing hampers the end-to-end deployment of YOLOs and adversely impacts the inference latency. Besides, the design of various components in YOLOs lacks the comprehensive and thorough inspection, resulting in noticeable computational redundancy and limiting the model's capability. It renders the suboptimal efficiency, along with considerable potential for performance improvements. In this work, we aim to further advance the performance-efficiency boundary of YOLOs from both the post-processing and model architecture. To this end, we first present the consistent dual assignments for NMS-free training of YOLOs, which brings competitive performance and low inference latency simultaneously. Moreover, we introduce the holistic efficiency-accuracy driven model design strategy for YOLOs. We comprehensively optimize various components of YOLOs from both efficiency and accuracy perspectives, which greatly reduces the computational overhead and enhances the capability. The outcome of our effort is a new generation of YOLO series for real-time end-to-end object detection, dubbed YOLOv10. Extensive experiments show that YOLOv10 achieves state-of-the-art performance and efficiency across various model scales. For example, our YOLOv10-S is 1.8$ imes$ faster than RT-DETR-R18 under the similar AP on COCO, meanwhile enjoying 2.8$ imes$ smaller number of parameters and FLOPs. Compared with YOLOv9-C, YOLOv10-B has 46\% less latency and 25\% fewer parameters for the same performance.
연구 동기 및 목표
- YOLO의 NMS 후처리 제거로 엔드투엔드 실시간 객체 탐지 한계 확장.
- NMS-free 추론을 위한 일관된 이중 할당 훈련 스킴 개발.
- 효율성과 정확성을 위한 YOLO 구성 요소의 총체적 최적화.
- COCO에서 모델 규모에 따른 최첨단 지연-정확도 트레이드오프를 입증.
제안 방법
- NMS-free 학습을 위한 Consistent Dual Assignments 제안(다중 레이블 헤드 하나-다수의 감독, 추론용 한-일대일).
- 일대일 및 다대일 할당을 연결하는 일관된 매칭 지표 도입으로 감독을 조화롭게 맞춤.
- 경량화 분류 헤드, 공간-채널 분리 다운샘플링, 랭크 안내 블록 설계를 포함한 holistic 효율-정확도 중심 모델 디자인 구현.
- 저비용으로 성능을 높이는 대형 커널 컨볼루션과 부분적 자기어텐션(PSA) 모듈을 활용한 정확도 중심 설계 탐구.
- 중복이 남지 않도록 compact blocks(CIB)를 랭크 기반으로 배치하고 모델 규모에 따라 대형 커널 및 PSA를 선택적으로 적용.
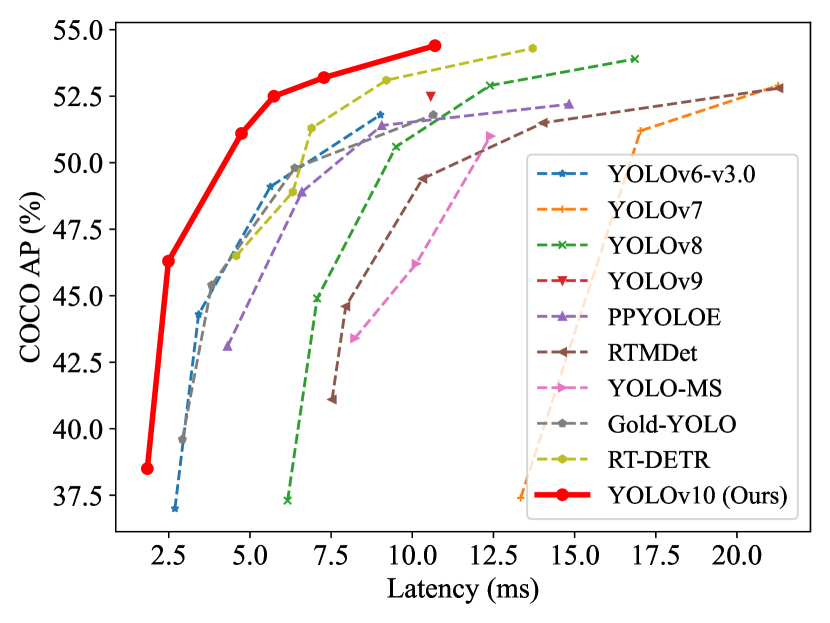
실험 결과
연구 질문
- RQ1NMS 기반 YOLO와 비교해 NMS-free 엔드투엔드 YOLO가 AP에서 비슷하거나 더 나은 성능을 내면서 추론 지연을 줄일 수 있는가?
- RQ2이중 라벨 할당과 통합 매칭 지표가 헤드 간 감독을 맞춰 학습 효율을 개선할 수 있는가?
- RQ3모델 규모에 따라 더 나은 효율-정확도 트레이드오프를 제공하는 총체적 아키텍처 변화는 무엇인가?
- RQ4대형 커널 컨볼루션과 PSA가 실시간 탐지기에서 비용 증가 없이 이점을 제공하는가?
- RQ5랭크 가이드 블록 설계 및 분리된 다운샘플링이 성능을 손상시키지 않으면서 중복성을 줄일 수 있는가?
주요 결과
- YOLOv10은 모델 규모에 따른 COCO 상의 지연-정확도 트레이드오프에서 최첨단 성능을 달성합니다.
- YOLOv10-S는 비슷한 AP에서 RT-DETR-R18보다 1.8배 빠르며 매개변수와 FLOPs이 각각 2.8배 줄어듭니다.
- YOLOv10-B는 동일한 성능 대비 YOLOv9-C에 비해 지연 시간이 46% 감소하고 매개변수는 25% 감소합니다.
- YOLOv10-L 및 YOLOv10-X는 0.3–1.0 AP의 이점으로 YOLOv8-L/X보다 더 우수하며 매개변수는 현저하게 적습니다(0.5–2.3배).
- YOLOv10-N/S는 경량 모델에서 로 Latency 및 AP 면에서 YOLOv6-3.0-N/S 및 RT-DETR 기준점을 상회하며 끝-에서의 지연 감소가 최대 약 70%에 이릅니다.
![Figure 2: (a) Consistent dual assignments for NMS-free training. (b) Frequency of one-to-one assignments in Top-1/5/10 of one-to-many results for YOLOv8-S which employs $\alpha_{o2m}$ =0.5 and $\beta_{o2m}$ =6 by default [ 20 ] . For consistency, $\alpha_{o2o}$ =0.5; $\beta_{o2o}$ =6. For inconsiste](https://ar5iv.labs.arxiv.org/html/2405.14458/assets/x3.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.