[논문 리뷰] ZeroShotDataAug: Generating and Augmenting Training Data with ChatGPT
논문은 zero-shot prompting이 효과적인 합성 학습 데이터를 생성하여 SST-2, SNIPS, TREC에서 여러 전통적 증강 방법을 능가한다는 것을 보여주며, few-shot ChatGPT와의 비교도 포함한다.
In this paper, we investigate the use of data obtained from prompting a large generative language model, ChatGPT, to generate synthetic training data with the aim of augmenting data in low resource scenarios. We show that with appropriate task-specific ChatGPT prompts, we outperform the most popular existing approaches for such data augmentation. Furthermore, we investigate methodologies for evaluating the similarity of the augmented data generated from ChatGPT with the aim of validating and assessing the quality of the data generated.
연구 동기 및 목표
- 대형 언어 모델(ChatGPT)에 대한 프롬프트를 사용하여 저자원 NLP 작업에 대한 데이터 증강을 동기를 부여한다.
- 다수의 데이터셋에서 확립된 기준선과 대조하여 zero-shot ChatGPT 데이터 증강을 평가한다.
- ChatGPT가 생성한 데이터와 원본 데이터 간의 유사도를 측정하는 방법을 제안하고 품질을 검증한다.
- 증강 크기가 성능에 미치는 영향을 정량화하고 학습 데이터 없이도 데이터의 충분성을 탐색한다.
제안 방법
- zero-shot ChatGPT 증강을 EDA, Back-Translation, 그리고 transformer 기반 증강 기준선과 비교한다.
- 저자원 설정에서 세 가지 데이터셋(SST-2, SNIPS, TREC)을 사용하되 클래스당 10개 예제로 한다.
- ChatGPT용 작업 특화 제로샷 프롬프트를 통해 합성 데이터를 생성하고 15회 실행에서 평가한다.
- 증강 데이터를 사용하여 BERT-base-uncased를 미세조정하고 정확도와 표준편차를 보고한다.
- Sentence Embedding (MiniLM), TF-IDF, 및 Word Overlap 지표를 사용하여 데이터 오염 및 유사성을 평가한다.
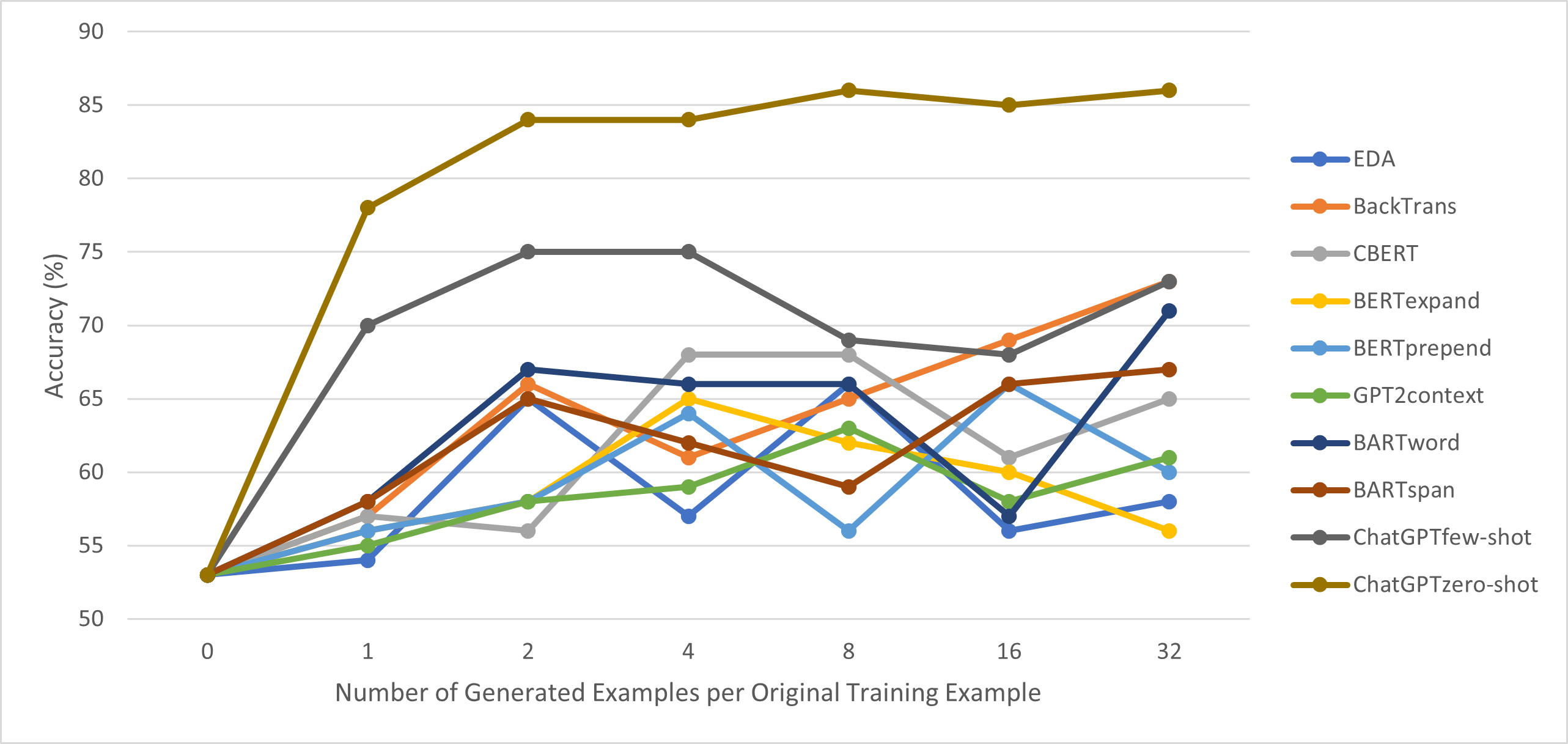
- 성능 추세를 연구하기 위해 다양한 증강 수를 실험한다.
실험 결과
연구 질문
- RQ1텍스트 분류 작업에서 전통적 방법과 비교하여 zero-shot ChatGPT 프롬프트가 데이터 증강에 얼마나 효과적인가?
- RQ2저자원 환경에서 ChatGPT 생성 데이터의 양이 모델 성능에 어떤 영향을 미치는가?
- RQ3 memorization이나 오염을 배제하기 위해 ChatGPT 생성 데이터와 실제 데이터 간의 유사성을 신뢰성 있게 평가할 수 있는가?
- RQ4원래의 학습 데이터가 전혀 없어도 zero-shot ChatGPT 증강이 다른 방법을 능가할 수 있는가?
주요 결과
- Zero-shot ChatGPT 증강은 78.1% (SST-2), 91.2% (SNIPS), 및 75.3% (TREC) 정확도를 달성하여 SNIPS에서 few-shot ChatGPT를 제외한 모든 기준선을 능가한다.
- SST-2와 TREC에서 비-ChatGPT 증강 중 최상위를 각각 20%와 8% 앞서며, SNIPS에서는 4% 앞선다.
- 원래 예제당 ChatGPT 생성 증강 예제의 수가 증가함에 따라 성능 향상이 지속되며(K in {1,2,4,8,16,32}).
- 원래 학습 데이터가 없어도 ChatGPT zero-shot 증강은 평균 정확도 0.80 (SST-2), 0.78 (SNIPS), 및 0.62 (TREC)를 산출하여 SST-2의 기존 방법 대비 경쟁력 있거나 더 나으며 TREC에서는 최상위에 근접하다.
- 유사성 분석(Cosine Sentence Embedding, Cosine TF-IDF, Word Overlap)은 ChatGPT 생성 데이터에서 데이터 암기나 오염의 증거가 거의 없음을 보인다.
- 데이터 유사성 결과는 ChatGPT 생성 데이터가 평균적으로 훈련 데이터에 더 근접하다고 나타내어 암기보다는 일반화를 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.