[논문 리뷰] A Note on Normalized Emergence Timing (in Pythia Language Model Evaluations)
이 논문은 동일한 데이터 순서로 학습된 공개적으로 이용 가능한 Pythia 라인업을 소개하고, 학습 다이나믹스, 스케일링 효과, 바이어스, 암기, 용어 빈도 영향에 대한 사례 연구를 분석합니다.
How do large language models (LLMs) develop and evolve over the course of training? How do these patterns change as models scale? To answer these questions, we introduce extit{Pythia}, a suite of 16 LLMs all trained on public data seen in the exact same order and ranging in size from 70M to 12B parameters. We provide public access to 154 checkpoints for each one of the 16 models, alongside tools to download and reconstruct their exact training dataloaders for further study. We intend extit{Pythia} to facilitate research in many areas, and we present several case studies including novel results in memorization, term frequency effects on few-shot performance, and reducing gender bias. We demonstrate that this highly controlled setup can be used to yield novel insights toward LLMs and their training dynamics. Trained models, analysis code, training code, and training data can be found at \url{https://github.com/EleutherAI/pythia}.
연구 동기 및 목표
- 대규모 언어 모델에 대한 과학적 연구를 표준화된 공개 모델 스위트를 제공함으로써 촉진한다.
- 학습 데이터 순서, 중복 제거, 모델 크기가 학습 다이나믹스와 편향에 어떤 영향을 미치는지 조사한다.
- 사전 학습 용어 빈도가 다운스트림 작업 성능에 미치는 역할을 학습 진행과 함께 검토한다.
제안 방법
- 동일한 데이터 순서로 학습된 8개의 모델 sizes(70M ~ 12B 파라미터)를 공개 체크포인트(모델당 154개)와 함께 제공한다.
- Pile 및 중복 제거된 Pile에서 두 복사본의 스위트를 학습하여 데이터 효과를 연구한다.
- 해석 가능성과 효율성을 위해 밀집 평행 어텐션과 회전 임베딩을 사용하고 임베딩 매트릭스는 풀링 해제된 형태로 사용한다.
- 확장성을 위해 대형 배치 사이즈(1024)로 GPT-NeoX 프레임워크, ZeRO, 데이터/텐서 병렬성, Flash Attention을 활용한다.
- 8개의 벤치마크에서 Language Model Evaluation Harness로 평가하여 OPT/BLOOM 베이스라인과 비교한다.
- 전체 모델, 체크포인트 및 평가 코드를 Apache 2.0 하에 공개하여 완전 재현성을 제공한다.
실험 결과
연구 질문
- RQ1학습 데이터 순서와 중복 제거가 스케일에 따라 모델 성능과 암기에 어떤 영향을 주는가?
- RQ2사전 학습 용어 빈도가 학습 중 작업 성능에 어떤 영향을 미치는가?
- RQ3병렬 어텐션과 MLP 계층의 아키텍처 선택이 소형 모델 대 대형 모델 성능에 어떤 영향을 주는가?
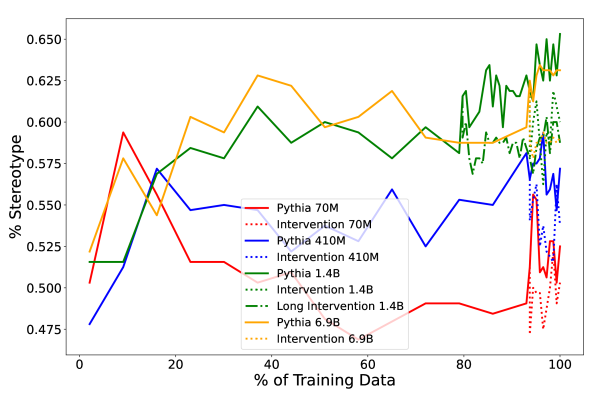
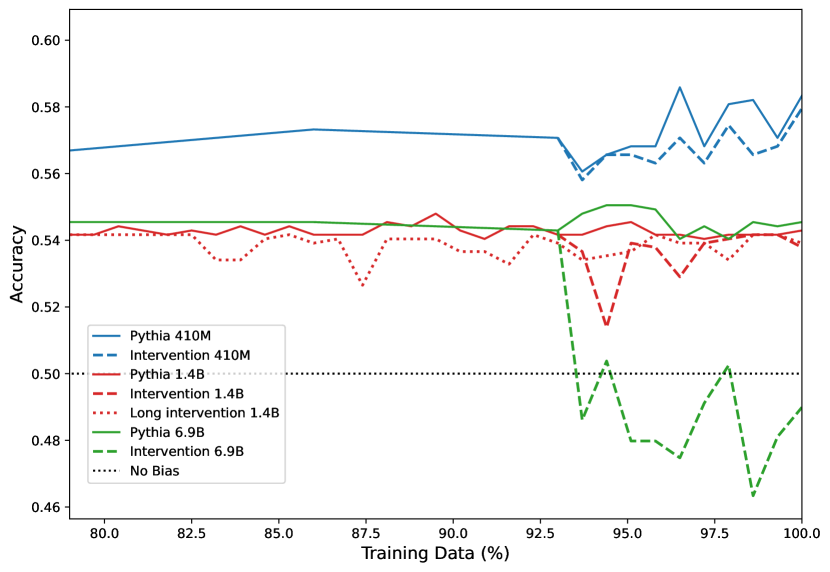
- RQ4대상 벤치마크에서 프라이언 대명사 빈도 수정으로 인한 성별 편향 개입이 모델 크기에 따라 다운스트림 편향 측정에 어떤 영향을 미치는가?
주요 결과
- 중복 제거가 Pythia 모델의 언어 모델링 성능에 명확한 이점으로 나타나지 않는다.
- 동일 토큰 수/동일 매개변수에서 병렬 어텐션 + MLP로 스케일을 따라 성능이 균등하게 나타나며, 일부 선행 주장과 달리 성능이 유지된다.
- BLOOM에서 벤치마크에 따라 다국어의 저주가 미미하고 불일치하므로 다양한 작업으로 재평가가 필요하다.
- 포아송 포인트 프로세스가 암기를 시점에 잘 맞춘 모델링으로 작동하며 학습 순서가 암기된 시퀀스에 미치는 영향은 제한적임을 시사한다.
- 약 65,000 학습 스텝(학습의 45%) 전후에서 중요한 상전이 단계가 발생하며 더 큰 모델(2.8B+)이 작업 정확도와 사전 학습 용어 빈도 간의 상관성을 보이기 시작한다.
- 마지막 7% 또는 21%의 학습에서 대명사 빈도 개입이 대상 벤치마크의 성별 편향을 줄이면서도 기본 작업의 퍼플렉시티에 큰 영향을 주지 않는다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.