[논문 리뷰] A Vision-Language Foundation Model to Enhance Efficiency of Chest X-ray Interpretation
이 논문은 CheXinstruct, CheXagent, CheXbench를 도입하여 흉부 X-선 해석을 위한 비전-언어 기초 모델을 구축하고 평가하며, 베이스라인 대비 큰 향상을 달성하고 공정성 평가를 수행한다.
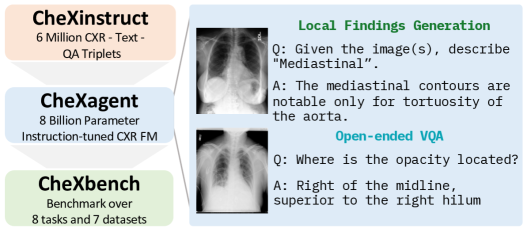
Over 1.4 billion chest X-rays (CXRs) are performed annually due to their cost-effectiveness as an initial diagnostic test. This scale of radiological studies provides a significant opportunity to streamline CXR interpretation and documentation. While foundation models are a promising solution, the lack of publicly available large-scale datasets and benchmarks inhibits their iterative development and real-world evaluation. To overcome these challenges, we constructed a large-scale dataset (CheXinstruct), which we utilized to train a vision-language foundation model (CheXagent). We systematically demonstrated competitive performance across eight distinct task types on our novel evaluation benchmark (CheXbench). Beyond technical validation, we assessed the real-world utility of CheXagent in directly drafting radiology reports. Our clinical assessment with eight radiologists revealed a 36% time saving for residents using CheXagent-drafted reports, while attending radiologists showed no significant time difference editing resident-drafted or CheXagent-drafted reports. The CheXagent-drafted reports improved the writing efficiency of both radiology residents and attending radiologists in 81% and 61% of cases, respectively, without loss of quality. Overall, we demonstrate that CheXagent can effectively perform a variety of CXR interpretation tasks and holds potential to assist radiologists in routine clinical workflows.
연구 동기 및 목표
- 여러 작업에 걸친 흉부 X-선용 대규모 지시-튜닝 데이터셋(CheXinstruct)을 생성한다.
- CXR 해석을 위한 8B-parameter 비전-언어 기초 모델(CheXagent)을 개발한다.
- 임상 LLM, CXR 비전 인코더, 브리징 모듈을 포함하는 학습 파이프라인으로 비전과 언어를 연결한다.
- CXR에서 이미지 지각과 텍스트 이해 전반에 걸친 FM 성능을 평가하기 위해 CheXbench를 구축한다.
- 투명성 향상을 위해 성별, 인종, 연령에 따른 모델 공정성을 평가한다.]
- method:[
제안 방법
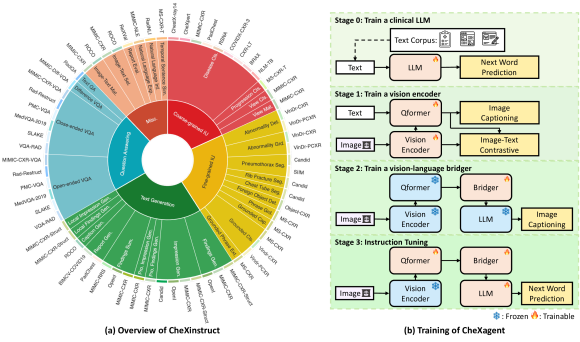
- CXRs를 위한 34개 작업과 65개 데이터셋으로부터 CheXinstruct를 구성하여 6.1M개의 지시-답변 삼중항을 생성한다.
- 비전 인코더, 비전-언어 브리저, 언어 디코더를 갖춘 CheXagent를 구축하고 임상 텍스트에 적응시키는 것을 포함하여 네 단계로 학습한다.
- Stage 0: PMC 초록, MIMIC-IV 방사선학 리포트, 퇴원 요약, Wikipedia 용어, 및 CheXinstruct 데이터를 이용하여 임상 LLM을 훈련한다.
- Stage 1: MIMIC-CXR, PadChest, BIMCV-COVID-19 데이터셋에서 ITC 및 IC 목표를 갖춘 CXR 비전 인코더를 훈련한다.
- Stage 2: LLM과 비전 인코더를 고정한 채 이미지-텍스트 표현 정렬을 위해 비전-언어 브리저를 훈련한다.
- Stage 3: CheXinstruct 작업에 대해 다음 단어 예측 목표를 사용하여 멀티모달 모델을 지시-튜닝하고 정답에 초점을 맞춘다.
실험 결과
연구 질문
- RQ1대규모 지시-튜닝 데이터셋이 다중모달 기초 모델에 의해 견고한 CXR 해석을 가능하게 할까?
- RQ2CXRs에서 사전훈련된 비전-언어 FM이 일반 도메인 및 의학 도메인 FM과 비교하여 핵심 지각 및 텍스트 생성 작업에서 어떻게 성능을 보일까?
- RQ3성별, 인종, 연령에 걸친 이러한 모델의 공정성 함의와 잠재적 편향은 무엇인가?
- RQ4제안된 CheXbench가 다중모달 CXR 해석 작업에 대한 신뢰할 수 있는 벤치마킹 프레임워크를 제공하는가?
- RQ5소견 생성 및 요약 작업에서 방사선과 전문의 수준의 품질은 어느 정도 달성될 수 있는가?
주요 결과
- CheXagent는 CheXbench 축 1의 이미지 지각 작업에서 일반 도메인 FM보다 평균 97.5% 더 우수하다.
- CheXagent는 축 1의 이미지 지각 작업에서 의학 도메인 FM보다 평균 55.7% 더 우수하다.
- 시야 분류에서 CheXagent는 MIMIC-CXR 및 CheXpert 데이터셋에서 베이스라인 대비 큰 성능 향상(거의 완전)에 이른다.
- 시각 질문 응답에서 CheXagent는 강한 성과를 보이고 hold-out 데이터셋(SLAKE, Rad-Restruct)으로 일반화한다.
- 텍스트 생성 작업에서 CheXagent는 비공개 및 MIMIC-CXR 데이터셋에서 더 우수한 소견 생성과 더 큰 LLM에 비해 요약 성능에서도 경쟁력 있는 모습을 보인다.
- 방사선과 의사 평가자 연구는 소견 요약에서 CheXagent가 의사와 비견하는 수준임을 보여주며 소견 생성의 차이를 지적하고 개선을 위한 질적 통찰을 제시한다.
- 공정성 분석은 성별, 인종, 연령에 따른 성능 차이를 드러내며 다양한 데이터와 편향 완화의 필요성을 강조한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.