[논문 리뷰] Accelerating Large Language Model Decoding with Speculative Sampling
사전적 샘플링이 빠른 드래프트 모델을 사용해 여러 토큰을 초안으로 작성하고 수정된 거절 샘플링 스킴으로 대상 모델의 분포를 보존함으로써 대상 모델을 수정하지 않고도 Chinchilla 70B에서 2–2.5배의 속도 향상을 달성한다.
We present speculative sampling, an algorithm for accelerating transformer decoding by enabling the generation of multiple tokens from each transformer call. Our algorithm relies on the observation that the latency of parallel scoring of short continuations, generated by a faster but less powerful draft model, is comparable to that of sampling a single token from the larger target model. This is combined with a novel modified rejection sampling scheme which preserves the distribution of the target model within hardware numerics. We benchmark speculative sampling with Chinchilla, a 70 billion parameter language model, achieving a 2-2.5x decoding speedup in a distributed setup, without compromising the sample quality or making modifications to the model itself.
연구 동기 및 목표
- 매우 큰 트랜스포머에서 자기회귀 디코딩의 지연시간 감소를 촉진한다.
- 대상 모델 호출당 다중 초안 토큰을 생성하기 위해 추측적 샘플링(SpS)을 제안한다.
- SpS가 하드웨어 수치 내에서 대상 분포를 보존하고 대상 모델을 수정하지 않고 배포될 수 있음을 보인다.
- 샘플 품질을 유지하면서 자연어 작업 전반에서 Chinchilla 크기의 모델에 대해 실질적인 속도 향상을 보여준다.
제안 방법
- 더 빠른 드래프트 모델(자회귀 또는 병렬)을 사용하여 길이 K의 짧은 초안을 생성한다.
- 더 큰 대상 모델로 초안의 연속을 채점하여 로짓 분포를 얻는다.
- 초안 토큰을 수락하고 대상 분포를 회복하기 위해 수정된 거절 샘플링 스킴을 적용한다.
- 이 스킴이 대상 분포를 보존함을 증명한다(정리 1).
- 4B 드래프트 모델과 70B 대상 모델(Chinchilla)을 사용하여 대기 시간과 품질을 측정한다.
- 일반적인 디코딩 방법(nucleus, top-k, temperature)과의 호환성을 보여주고, 다른 효율 기법과의 결합 가능성을 시사한다.
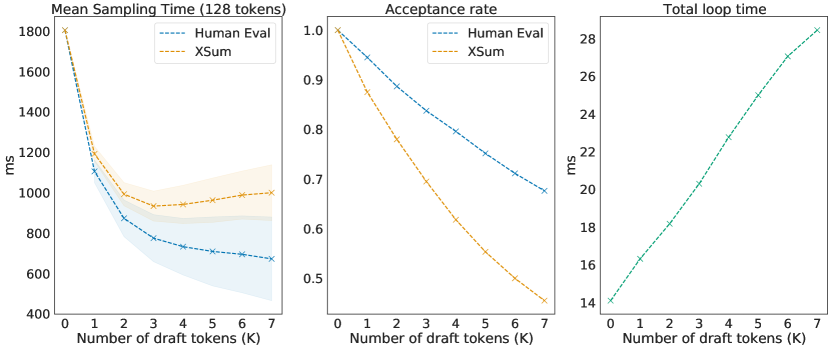
실험 결과
연구 질문
- RQ1대상 모델을 수정하지 않고도 추측적 샘플링으로 지연 시간을 줄일 수 있는가?
- RQ2초안 길이 K와 작업 및 디코딩 전략 전반에 걸친 전반적인 속도 향상 사이의 트레이드오프는 무엇인가?
- RQ3초안 토큰의 수락률이 도메인 및 디코딩 설정에 따라 어떻게 달라지며 샘플 품질은 여전히 유지되는가?
주요 결과
| Sampling Method | Benchmark | Result | Mean Token Time | Speed Up |
|---|---|---|---|---|
| ArS (Nucleus) | XSum (ROUGE-2) | 0.112 | 14.1ms/Token | 1× |
| SpS (Nucleus) | XSum (ROUGE-2) | 0.114 | 7.52ms/Token | 1.92× |
| ArS (Greedy) | XSum (ROUGE-2) | 0.157 | 14.1ms/Token | 1× |
| SpS (Greedy) | XSum (ROUGE-2) | 0.156 | 7.00ms/Token | 2.01× |
| ArS (Nucleus) | HumanEval (100 Shot) | 45.1% | 14.1ms/Token | 1× |
| SpS (Nucleus) | HumanEval (100 Shot) | 47.0% | 5.73ms/Token | 2.46× |
- 분산 설정에서 Chinchilla 70B를 샘플링할 때 2–2.5×의 디코딩 속도를 달성한다.
- 추측적 샘플링은 수치 내에서 대상 분포를 보존하며, XSum 및 HumanEval 작업에서 경험적 결과가 기준값과 일치한다.
- 4B 초안 모델은 동일 하드웨어에서 1.8 ms/token에 도달할 수 있으며 대상 모델은 14.1 ms/token으로, 실질적인 속도 향상을 크게 가능하게 한다.
- 일부 경우(예: XSum의 그리디 방식과 HumanEval에서)에서 속도 향상은 하드웨어 메모리 대역폭 한도를 초과할 수 있다.
- 수락률과 효율은 K 및 도메인에 의존하며, 작업에 따라 최적 K가 다르다(예: XSum의 경우 K=3).
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.