[논문 리뷰] Analyzing Leakage of Personally Identifiable Information in Language Models
본 논문은 세 가지 PII 누출 공격(extraction, reconstruction, inference)을 소개하고, 이를 law, 건강, 및 이메일 도메인에서 미세조정된 GPT-2 변형에 방어 여부와 함께 평가하며, scrubbing과 differential privacy가 PII 누출에 미치는 영향을 분석한다.
Language Models (LMs) have been shown to leak information about training data through sentence-level membership inference and reconstruction attacks. Understanding the risk of LMs leaking Personally Identifiable Information (PII) has received less attention, which can be attributed to the false assumption that dataset curation techniques such as scrubbing are sufficient to prevent PII leakage. Scrubbing techniques reduce but do not prevent the risk of PII leakage: in practice scrubbing is imperfect and must balance the trade-off between minimizing disclosure and preserving the utility of the dataset. On the other hand, it is unclear to which extent algorithmic defenses such as differential privacy, designed to guarantee sentence- or user-level privacy, prevent PII disclosure. In this work, we introduce rigorous game-based definitions for three types of PII leakage via black-box extraction, inference, and reconstruction attacks with only API access to an LM. We empirically evaluate the attacks against GPT-2 models fine-tuned with and without defenses in three domains: case law, health care, and e-mails. Our main contributions are (i) novel attacks that can extract up to 10$ imes$ more PII sequences than existing attacks, (ii) showing that sentence-level differential privacy reduces the risk of PII disclosure but still leaks about 3% of PII sequences, and (iii) a subtle connection between record-level membership inference and PII reconstruction. Code to reproduce all experiments in the paper is available at https://github.com/microsoft/analysing_pii_leakage.
연구 동기 및 목표
- 일반적인 암기(memory)를 넘어 LMs에서 PII 누출을 연구할 필요성을 촉진하고, 특히 직접적이거나 맥락상 노출되는 PII에 대해.
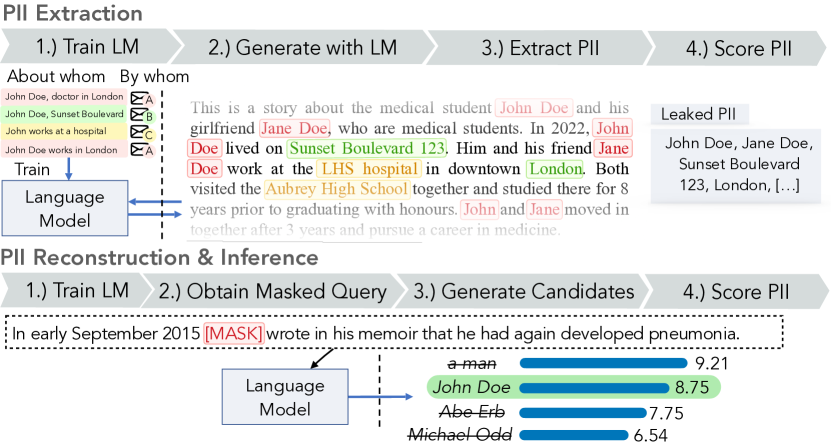
- 추출(extraction), 재구성(reconstruction), 추론(inference)을 통한 PII 누출에 대해 형식적 분류체계와 게임 기반 정의를 개발한다.
- 세 가지 도메인에서 미세조정된 GPT-2 변형에 대해 블랙박스 API 접근을 사용하여 PII 누출을 실증적으로 평가하며, undefended, scrubbed, 및 DP-trained 모델을 비교한다.
- 프라이버시-유틸리티 트레이드오프를 정량화하고 방어 설계 및 정책에 대한 실행 가능한 통찰을 제공한다.
제안 방법
- 형식적인 게임 기반 정의를 포함하여 세 가지 PII 누출 위협: extraction, reconstruction, and inference를 제안한다.
- 블랙박스 LM 접근 하에서 추출가능성(extractability) 및 재현율(recall)을 포함한 PII 누출에 대한 지표를 정의한다.
- 접미사/접두사 정보 및 마스킹된 출력(outputs)을 사용하여 이상적 누출에 근접한 구체적인 공격 알고리즘을 개발한다.
- 법, 건강 관리, 이메일 도메인에서 미세조정된 GPT-2 변형에 대해 undefended, scrubbed, 및 DP-trained 설정 하에서 공격을 평가한다.
- 스크러빙과 DP가 모델의 perplexity 및 PII 누출 위험에 미치는 영향을 분석한다.
- 실험 재현을 위한 코드를 제공한다.
실험 결과
연구 질문
- RQ1블랙박스 API 접근을 통해 extraction, reconstruction, 및 inference 공격으로 언어 모델이 얼마나 많은 PII를 누출하는가?
- RQ2PII scrubbing 또는 differential privacy가 PII 누출을 충분히 완화하는가, 그리고 그에 따른 프라이버시/유용성 트레이드오프는 무엇인가?
- RQ3실무에서 기록 수준의 멤버십 추론과 PII 재구성의 관계는 무엇인가?
- RQ4기록 수준의 DP 방어가 PII 누출를 제한할 수 있는가, 모델 유용성을 손상시키지 않고?
주요 결과
- The attacks can extract up to 10× more PII sequences than existing attacks.
- Sentence-level differential privacy reduces PII leakage risk but still leaks about 3% of PII sequences.
- There is a subtle connection between record-level membership inference and PII reconstruction.
- DP offers substantial but not complete protection against PII leakage, highlighting the need for complementary defenses.
- Scrubbing and DP trade-offs can be tuned to balance privacy and utility, suggesting potential for combined or lighter scrubbing when DP is present.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.