[논문 리뷰] ARAGOG: Advanced RAG Output Grading
이 논문은 다수의 검색 증강 생성(RAG) 기법을 검색 정확도와 답변 유사도에서 벤치마크하며, HyDE와 LLM 기반 재정렬이 검색 품질을 높이고, Sentence Window 검색이 최고 수준의 검색 정확도를 제공하는 반면, 일부 기법은 Naive RAG를 능가하지 못하는 것으로 나타났다.
Retrieval-Augmented Generation (RAG) is essential for integrating external knowledge into Large Language Model (LLM) outputs. While the literature on RAG is growing, it primarily focuses on systematic reviews and comparisons of new state-of-the-art (SoTA) techniques against their predecessors, with a gap in extensive experimental comparisons. This study begins to address this gap by assessing various RAG methods' impacts on retrieval precision and answer similarity. We found that Hypothetical Document Embedding (HyDE) and LLM reranking significantly enhance retrieval precision. However, Maximal Marginal Relevance (MMR) and Cohere rerank did not exhibit notable advantages over a baseline Naive RAG system, and Multi-query approaches underperformed. Sentence Window Retrieval emerged as the most effective for retrieval precision, despite its variable performance on answer similarity. The study confirms the potential of the Document Summary Index as a competent retrieval approach. All resources related to this research are publicly accessible for further investigation through our GitHub repository ARAGOG (https://github.com/predlico/ARAGOG). We welcome the community to further this exploratory study in RAG systems.
연구 동기 및 목표
- 고급 RAG 기법 스펙트럼이 검색 정확도와 답변 유사도에 어떤 영향을 미치는지 평가한다.
- 검색 및 생성 구성 요소의 조합이 RAG 파이프라인에서 가장 강한 성능을 낳는지 식별한다.
- 검색 품질, 지연 시간, 비용 간의 트레이드오프에 대한 실무적 지침을 제공한다.
- 커뮤니티의 재현 및 확장을 가능하게 하기 위해 실험 파이프라인을 공개적으로 제공한다.
제안 방법
- Sentence-window 검색, Document Summary Index, HyDE, Multi-query, MMR, Cohere rerank, 및 LLM rerank를 포함한 광범위한 RAG 기법 세트를 평가한다.
- 각 방법의 필요를 반영하기 위해 서로 다른 청킹 전략(512-token 토큰과 50-token 중복, 3-문장 창, 3072-token 요약)을 사용하여 벡터 데이터베이스를 구성한다.
- 생성기로 GPT-3.5-turbo를 사용하고, 평가를 위해 Tonic Validate 지표를 통해 LLM으로 평가한다.
- 기법별로 LLM 변동성을 완화하기 위해 Retrieval Precision과 Answer Similarity(0-5)를 10회 수행하여 측정한다.
- 검색 정확도 차이의 통계적 유의성을 평가하기 위해 ANOVA와 Tukey’s HSD를 적용한다.
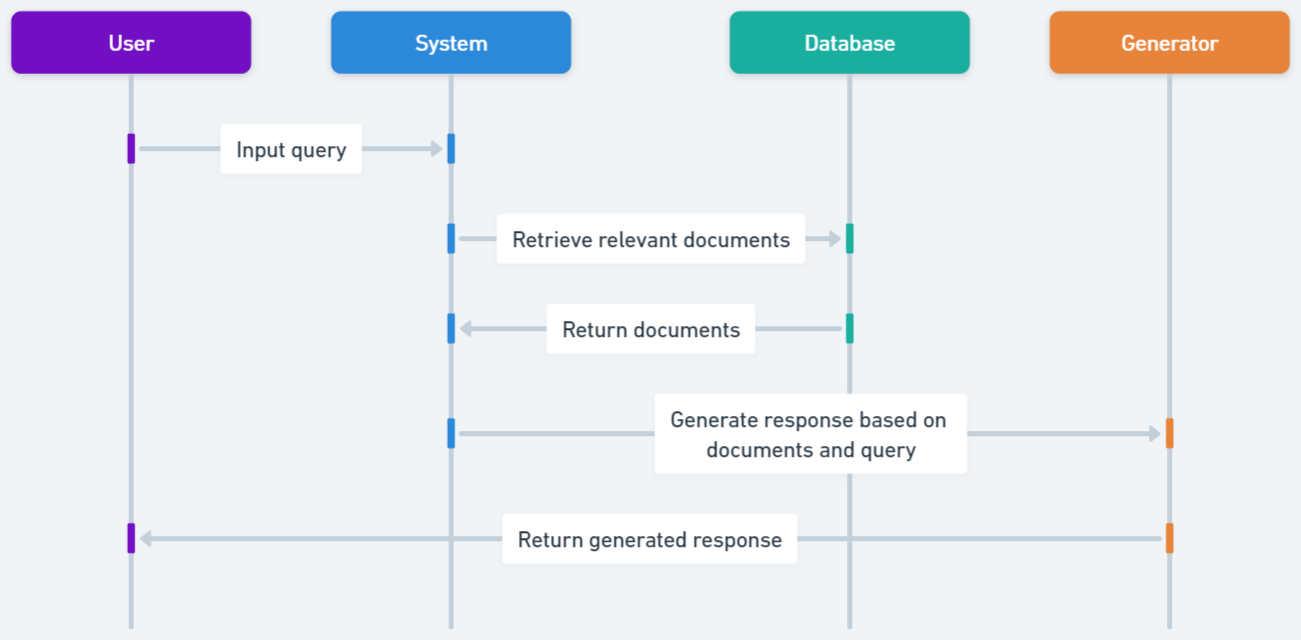
실험 결과
연구 질문
- RQ1Naive RAG에 비해 어떤 RAG 기법이 검색 정확도를 가장 크게 개선하는가?
- RQ2검색 정확도와 답변 유사도 및 비용 간의 무역은 어떻게 나타나는가?
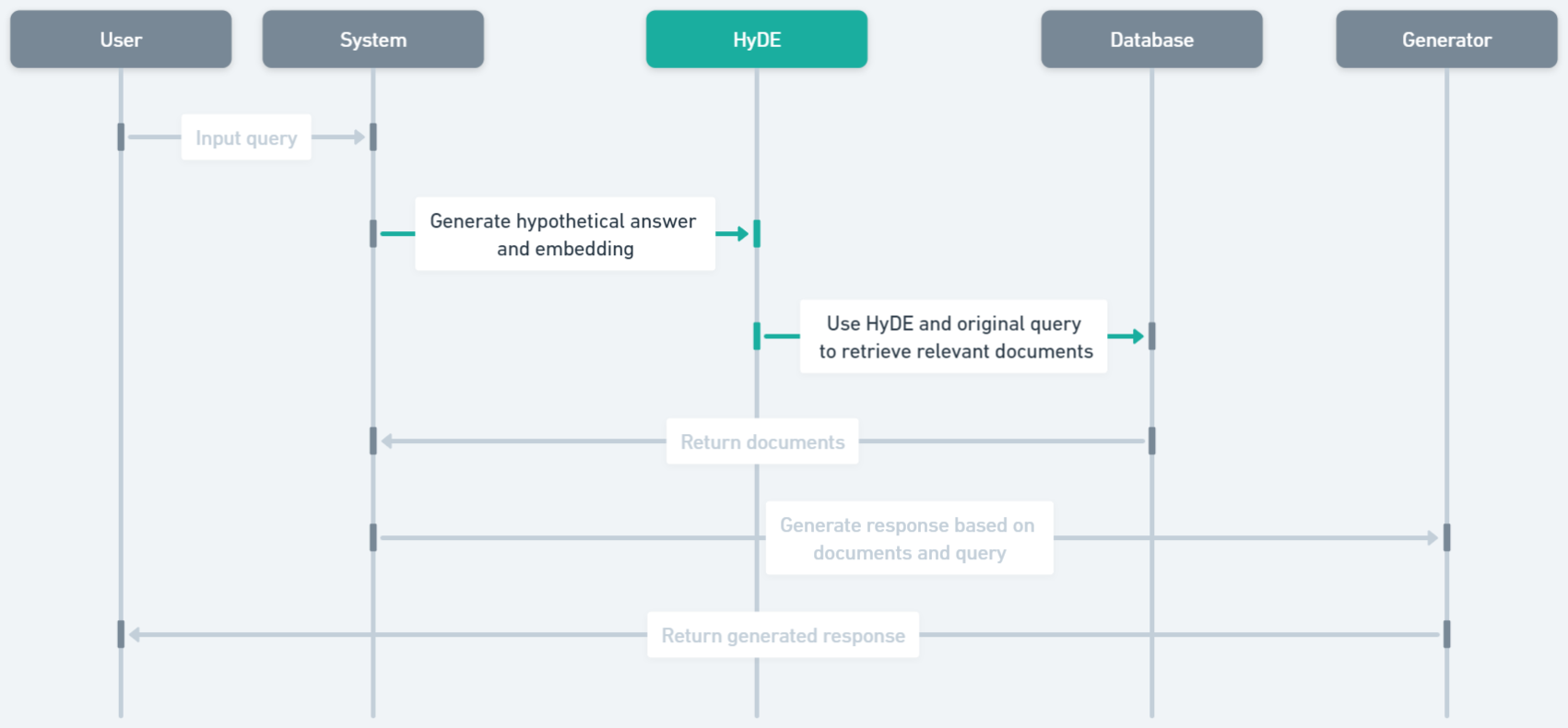
- RQ3HyDE 또는 재정렬자와 같은 기법이 데이터 세트 및 청킹 방식에 따라 일관되게 Baseline을 능가하는가?
- RQ4Sentence Window 검색이 구성에 따라 검색 정확도에서 일관되게 우수한가?
주요 결과
- HyDE 및 LLM 재정렬이 Naive RAG에 비해 검색 정확도를 크게 향상시킨다.
- Sentence Window Retrieval은 높은 검색 정확도를 제공하며 종종 클래식 벡터 데이터베이스 벤치마크를 능가한다.
- MMR 및 Cohere 재정렬은 검색 정확도에서 Naive RAG에 비해 거의 개선을 보이지 않는다.
- Multi-query 방식은 검색 정확도에서 Baseline Naive RAG에 비해 저조하다.
- Document Summary Index 방식은 최적의 Classic VDB 설정과 유사한 성능을 보이지만 사전 요약 작업이 필요하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.