[논문 리뷰] Are Sounds Sound for Phylogenetic Reconstruction?
연구는 열 개의 언어 데이터세트에 걸쳐 어휘적 동족어, 음향 대응, 그리고 이들의 조합으로 추론된 계통발생도를 비교하여, 동족어 기반 트리와 연결 데이터 기반 트리가 일반적으로 음향 기반 트리보다 황금 표준에 더 가깝다는 것을 발견한다; 분자 데이터에 적합한 베이esian 사전은 언어 분석에 편향을 줄 수 있으며, 음향 기반 접근법은 거의 동족어 기반에 비해 성과를 내지 못한다.
In traditional studies on language evolution, scholars often emphasize the importance of sound laws and sound correspondences for phylogenetic inference of language family trees. However, to date, computational approaches have typically not taken this potential into account. Most computational studies still rely on lexical cognates as major data source for phylogenetic reconstruction in linguistics, although there do exist a few studies in which authors praise the benefits of comparing words at the level of sound sequences. Building on (a) ten diverse datasets from different language families, and (b) state-of-the-art methods for automated cognate and sound correspondence detection, we test, for the first time, the performance of sound-based versus cognate-based approaches to phylogenetic reconstruction. Our results show that phylogenies reconstructed from lexical cognates are topologically closer, by approximately one third with respect to the generalized quartet distance on average, to the gold standard phylogenies than phylogenies reconstructed from sound correspondences.
연구 동기 및 목표
- 음향 대응 패턴이 어휘적 동족어보다 더 정확한 언어 계통발생을 산출하는지 평가한다.
- 동족어 탐지 및 음향 대응 추론의 자동화와 베이지안 및 ML 프레임워크 내 평가.
- 베이지안 결과를 최대우도 analyses로 교차 검증하고 사전 효과를 검토한다.
- 음향 기반 계통발생을 황금 표준인 Glottolog 트리와 비교한다.
- 데이터 유형을 결합하는 것이 더 우수한 계통발생 신호를 제공하는지 조사한다.
제안 방법
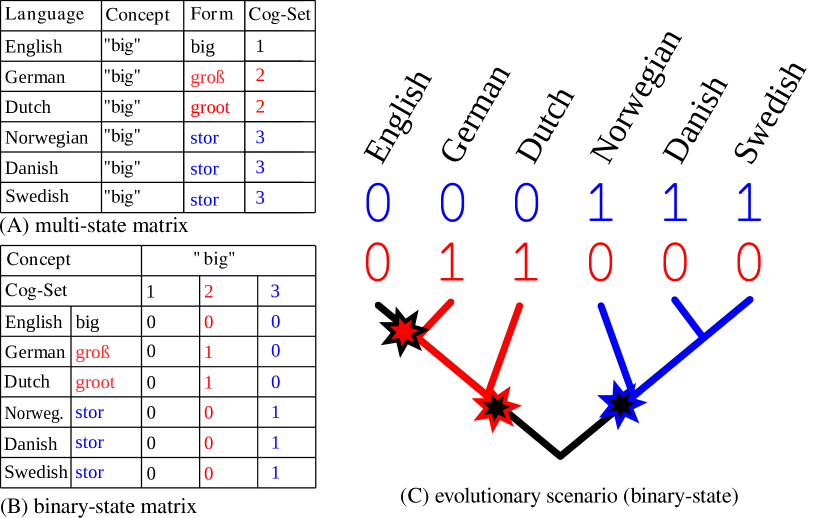
- 동족어 판단 및 음향 대응 패턴을 이진 존재-부재 행렬로 인코딩한다.
- 특성의 획득/손실에 대해 시간대칭 이진 상태 CTMC로 진화를 모델링한다.
- 표준화된 사전을 사용한 MrBayes로 베이esian 계통 추론을 수행하고 알파 형상 priors를 검토한다.
- BIN+G 하에서 ML-추정 알파를 사용하여 속도 이질성에 대한 ML 계통 추론을 RAxML-NG로 수행한다.
- 잡음 감소를 위해 음성 정렬을 다듬고 LingRex/LingPy로 음향 대응을 계산하며; Glottolog 트리와의 일반화 사분발거리(GQD)로 평가한다.
- 세 가지 데이터세트를 테스트한다: 동족어, 음향 대응, 그리고 연결된 행렬들.
실험 결과
연구 질문
- RQ1동족어 데이터로부터 추정된 계통발생이 음향 대응으로부터 추정된 계통발생보다 황금 표준 트리와 더 잘 일치하는가?
- RQ2음향 대응 기반의 계통발생이 동족어 기반 계통발생보다 황금 표준에 더 근접한 경우가 있는가?
- RQ3동족어와 음향 데이터를 결합한 경우 하나의 데이터 유형을 사용하는 것보다 더 우수한 계통발생 신호를 제공하는가?
- RQ4분자 데이터에 맞춘 베이지안 사전이 언어 계통발생 결과에 편향을 주는가, ML 분석이 이러한 편향을 드러내는가?
- RQ5여러 데이터 세트에서 음향 기반 계통발생과 동족어 기반 계통발생은 일반화된 사분거리(GQD) 측면에서 어떻게 비교되는가?
주요 결과
- 동족어 데이터와 연결 데이터의 계통발생은 대략 비슷한 정확도 범위에 있으며 일반적으로 음향 기반 트리보다 황금 표준에 더 가깝다.
- 음향 대응 기반 계통발생은 10개의 데이터세트 전체에서 베이지안 분석에서 최상의 결과를 내지 못한다.
- 연결 데이터가 열 개 중 일곱 데이터세트에서 최상의 결과를 제공하고, 남은 세 개는 동족어 데이터가 최상이다.
- ML 분석은 대체로 베이지안 결과를 확인시키며, 동족어 및 연결 기반 트리가 음향 기반 트리보다 일반적으로 황금 표준에 더 가까움을 보여준다.
- 기본 분자 사전은 언어 베이지안 결과에 편향을 줄 수 있으며, ML 분석으로 보완하면 이러한 편향을 진단하는 데 도움이 된다.
- 본 연구는 언어 데이터에 베이지안 방법을 적용할 때 사전 및 모델링 선택을 재평가할 필요성을 강조한다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.