[논문 리뷰] AutoRT: Embodied Foundation Models for Large Scale Orchestration of Robotic Agents
AutoRT 시스템은 비전-언어 및 언어 모델을 활용하여 현실 세계 로봇의 함대를 조율하고 다양한 데이터 수집을 수행하며, 7개월 동안 20+ 대의 로봇에서 77k 에피소드를 달성하고 혼합 자율성과 원격 조작으로 운영됩니다.
Foundation models that incorporate language, vision, and more recently actions have revolutionized the ability to harness internet scale data to reason about useful tasks. However, one of the key challenges of training embodied foundation models is the lack of data grounded in the physical world. In this paper, we propose AutoRT, a system that leverages existing foundation models to scale up the deployment of operational robots in completely unseen scenarios with minimal human supervision. AutoRT leverages vision-language models (VLMs) for scene understanding and grounding, and further uses large language models (LLMs) for proposing diverse and novel instructions to be performed by a fleet of robots. Guiding data collection by tapping into the knowledge of foundation models enables AutoRT to effectively reason about autonomy tradeoffs and safety while significantly scaling up data collection for robot learning. We demonstrate AutoRT proposing instructions to over 20 robots across multiple buildings and collecting 77k real robot episodes via both teleoperation and autonomous robot policies. We experimentally show that such "in-the-wild" data collected by AutoRT is significantly more diverse, and that AutoRT's use of LLMs allows for instruction following data collection robots that can align to human preferences.
연구 동기 및 목표
- 실험실 환경을 넘어 대규모의 현실 세계 로봇 데이터 수집의 필요성을 동기화합니다.
- 기초 모델을 사용하여 로봇 함대를 이용해 과업을 계획하고 근거를 제시하며 실행하는 시스템을 제안합니다.
- 안전 제약 하에 자율 정책과 인간 원격조작자의 혼합 감독을 가능하게 합니다.
- 다수의 건물에서의 실제 배치와 substantial 데이터 수집을 달성합니다.
- AutoRT를 통해 수집된 데이터가 다운스트림 로봇 학습 모델을 개선하는지를 보여줍니다.
제안 방법
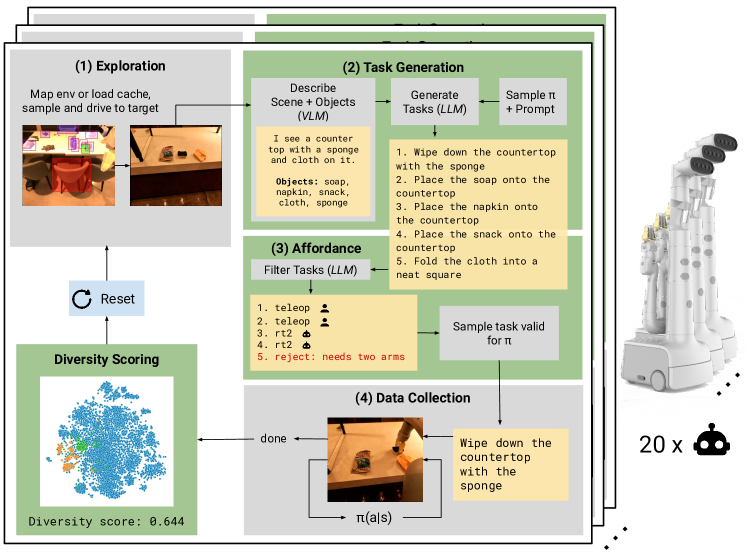
- 비전-언어 모델을 사용해 장면을 설명하고 객체를 근거화합니다.
- 대형 언어 모델을 활용해 장면 설명으로부터 다양하고 새로운 조작 과업을 생성합니다.
- 과업 제안을 제약하기 위해 안전 및 구현 규칙이 포함된 로봇 구성 원칙을 적용합니다.
- LLM이 가능하고(feasible)한 과업과 정책을 비판하고 선택하는 활용성 필터(affordance filtering) 단계를 도입합니다.
- 감독 제약 하에 다수의 수집 정책(텔레오프, 스크립트 피크, RT-2)으로 로봇 함대를 조정합니다.
- 생성 과업의 다양성과 가능성을 평가하고 RT-1 모델 미세 조정에 대한 데이터 유용성을 입증합니다.
실험 결과
연구 질문
- RQ1구현된 기반 모델 구동 시스템이 여러 대의 로봇에 걸쳐 현실 세계 로봇 데이터 수집을 규모 있게 확장할 수 있습니까?
- RQ2LLMs가 시각적 관찰에 근거한 안전하고 가능하며 다양한 조작 과업을 얼마나 효과적으로 생성할 수 있습니까?
- RQ3로봇 구성 및 활용성 프롬프트가 과업 안전성과 적합성에 어떤 영향을 미칩니까?
- RQ4AutoRT 데이터가 RT-1과 같은 다운스트림 로봇 학습 모델에 어떤 영향을 줍니까?
- RQ5혼합 감독하의 현장 데이터 수집에서 처리량, 다양성, 안전성 특성은 어떤가요?
주요 결과
| Collect Policy | #Episodes | Success Rate |
|---|---|---|
| 스크립트 정책 | 73293 | 21% |
| 원격 조작 | 3060 | 82% |
| RT-2 | 936 | 4.7% |
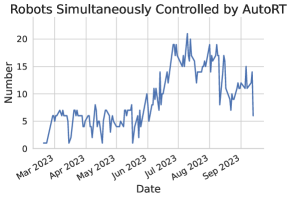
- AutoRT는 7개월 동안 4개의 건물에서 53대의 로봇에 걸쳐 77,000개의 현실 세계 에피소드를 수집했습니다.
- 하나의 사람 감독이 3–5대의 로봇을 관리하여 확장 가능한 배치를 가능케 했습니다.
- 원격 조작은 과업 성공률이 가장 높았고(82%), 반면 스크립트 정책은 가장 자주 사용되었습니다(73,293 에피소드).
- RT-2 자율성은 수집 도중 낮은 성공률(4.7%)을 보였으며 이는 학습 데이터의 도메인 시프트를 반영합니다.
- AutoRT 데이터는 배경 데이터 대비 언어적 다양성 및 시각적 다양성이 더 높았고, 프롬프트된 데이터는 RT-1 성능(높은 피킹 높이, 닦기 등)을 개선할 수 있습니다.
- 구성 프롬프트와 자기성찰 기반 활용성 필터링은 제안 과업의 안전성과 실행 가능성을 향상시켰습니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.