[논문 리뷰] ChatPose: Chatting about 3D Human Pose
PoseGPT는 SMPL 포즈를 고유 토큰으로 임베딩하여 텍스트나 이미지로부터 3D 인간 포즈를 생성하고 추론하는 다중모달 LLM 프레임워크이며, 추정적 포즈 생성 및 추론 기반 포즈 추정 벤치마크를 도입합니다.
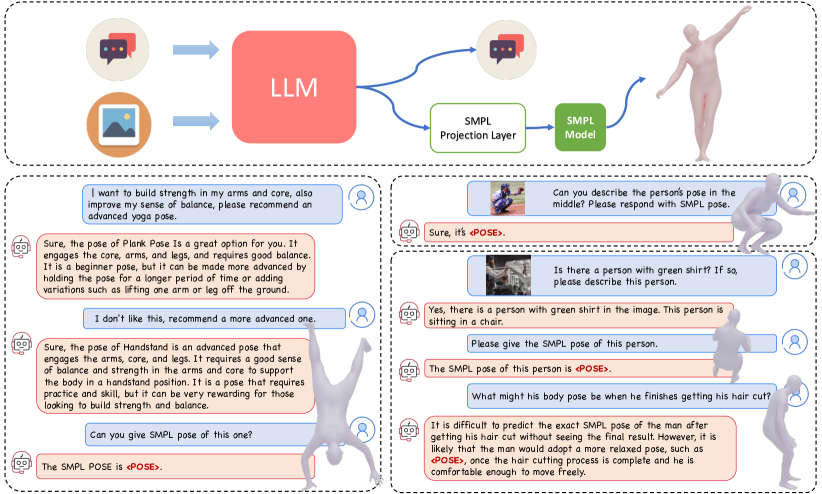
We introduce ChatPose, a framework employing Large Language Models (LLMs) to understand and reason about 3D human poses from images or textual descriptions. Our work is motivated by the human ability to intuitively understand postures from a single image or a brief description, a process that intertwines image interpretation, world knowledge, and an understanding of body language. Traditional human pose estimation and generation methods often operate in isolation, lacking semantic understanding and reasoning abilities. ChatPose addresses these limitations by embedding SMPL poses as distinct signal tokens within a multimodal LLM, enabling the direct generation of 3D body poses from both textual and visual inputs. Leveraging the powerful capabilities of multimodal LLMs, ChatPose unifies classical 3D human pose and generation tasks while offering user interactions. Additionally, ChatPose empowers LLMs to apply their extensive world knowledge in reasoning about human poses, leading to two advanced tasks: speculative pose generation and reasoning about pose estimation. These tasks involve reasoning about humans to generate 3D poses from subtle text queries, possibly accompanied by images. We establish benchmarks for these tasks, moving beyond traditional 3D pose generation and estimation methods. Our results show that ChatPose outperforms existing multimodal LLMs and task-specific methods on these newly proposed tasks. Furthermore, ChatPose's ability to understand and generate 3D human poses based on complex reasoning opens new directions in human pose analysis.
연구 동기 및 목표
- 이미지/텍스트 이해와 3D 인간 포즈를 단일 모델로 연결하는 동기를 부여합니다.
- 채팅 기반의 다중모달 LLM을 통해 SMPL 포즈의 생성과 추정이 가능하게 합니다.
- 추정적 포즈 생성과 추론 기반 포즈 추정을 새로운 작업으로 도입합니다.
제안 방법
- SMPL 포즈를 <POSE> 토큰으로 다중모달 LLM 내부에 임베딩하여 언어 임베딩을 SMPL 포즈 파라미터로 매핑하기 위해 MLP 프로젝션 계층을 사용합니다.
- 학습 중 비전 인코더를 고정하고; SMPL 프로젝션 계층만 학습시키는 동안 LoRA로 LLM을 미세조정합니다.
- 포즈 생성과 포즈 추론을 가능하게 하기 위해 텍스트-포즈, 이미지-포즈 및 다중모달 명령 준수 데이터를 이용해 학습합니다.
실험 결과
연구 질문
- RQ1다중모달 LLM이 텍스트나 이미지로부터 3D 인간 포즈(SMPL)를 이해하고 생성할 수 있는가?
- RQ2모델이 세계 지식과 현장 지식을 활용하여 추정적 포즈 생성과 추론 기반 포즈 추정을 수행할 수 있는가?
- RQ3포즈 생성 및 포즈 추정(추론 기반 작업 포함)에서 PoseGPT가 작업 특화 및 다른 다중모달 기반선과 어떻게 비교되는가?
주요 결과
| 방법 | MPJPE 3DPW (mm) | PA-MPJPE 3DPW (mm) | MPJRE 3DPW | MPJPE H36M (mm) | PA-MPJPE H36M (mm) | MPJRE H36M |
|---|---|---|---|---|---|---|
| PoseGPT (본 연구) | 163.6 | 81.9 | 10.4 | 126.0 | 82.4 | 10.4 |
- PoseGPT는 텍스트나 이미지로부터 SMPL 포즈를 생성할 수 있으며 대화 기반 포즈 추론을 가능하게 합니다.
- 추정적 포즈 생성에서 PoseGPT는 PoseScript를 능가하고 고전적 포즈 생성 벤치마크와 경쟁력 있는 결과를 달성합니다.
- 추론 기반 포즈 추정에서 PoseGPT는 다른 다중모달 LLM 및 작업 특화 방법을 앞지르지만, 표준 포즈 추정 지표에서는 여전히 고전적 포즈 추정기가 더 강합니다.
- 모델은 가림에 대한 강건성과 텍스트 포즈 설명보다 포즈 임베딩 사용에서 이점을 보여줍니다.
- 더 큰 LLM 백본(13B 대 7B)을 사용하면 PoseGPT 성능이 향상됩니다.
- 이 접근법은 3D 포즈 맥락에서 추론 능력을 평가하기 위한 두 가지 새로운 벤치마크(SPG와 RPE)를 가능하게 합니다.
![Figure 2 : Method and Training Overview. Our model is composed of a multi-modal LLM (with vision encoder, vision projection layer and LLM), a SMPL projection layer, and the parametric human body model, i.e. SMPL [ 29 ] . The multi-modal LLM processes text and image inputs (if provided) to generate t](https://ar5iv.labs.arxiv.org/html/2311.18836/assets/x2.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.