[논문 리뷰] Conformer: Convolution-augmented Transformer for Speech Recognition
Conformer는 음성의 지역 의존성과 전역 의존성을 모두 모델링하기 위해 합성곱과 자기 주의를 결합하고, 다양한 매개변수 규모에서 언어 모델 여부에 관계없이 LibriSpeech WER에서 최첨단 성능을 달성한다.
Recently Transformer and Convolution neural network (CNN) based models have shown promising results in Automatic Speech Recognition (ASR), outperforming Recurrent neural networks (RNNs). Transformer models are good at capturing content-based global interactions, while CNNs exploit local features effectively. In this work, we achieve the best of both worlds by studying how to combine convolution neural networks and transformers to model both local and global dependencies of an audio sequence in a parameter-efficient way. To this regard, we propose the convolution-augmented transformer for speech recognition, named Conformer. Conformer significantly outperforms the previous Transformer and CNN based models achieving state-of-the-art accuracies. On the widely used LibriSpeech benchmark, our model achieves WER of 2.1%/4.3% without using a language model and 1.9%/3.9% with an external language model on test/testother. We also observe competitive performance of 2.7%/6.3% with a small model of only 10M parameters.
연구 동기 및 목표
- 종단 간(end-to-end) ASR 모델이 로컬과 글로벌 음성 특징을 모두 효율적으로 포착하도록 동기를 부여한다.
- Macaron 스타일 피드포워드 계층과 함께 컨볼루션과 자기 주의를 융합하는 Conformer 블록을 제안한다.
- 여러 모델 크기에 걸쳐 LibriSpeech에서 매개변수 효율적인 성능 이점을 입증한다.
- 성능 향상의 원인을 이해하기 위한 설계 선택(어텐션 헤드 수, 커널 크기, FFN 배치)을 분석한다.
제안 방법
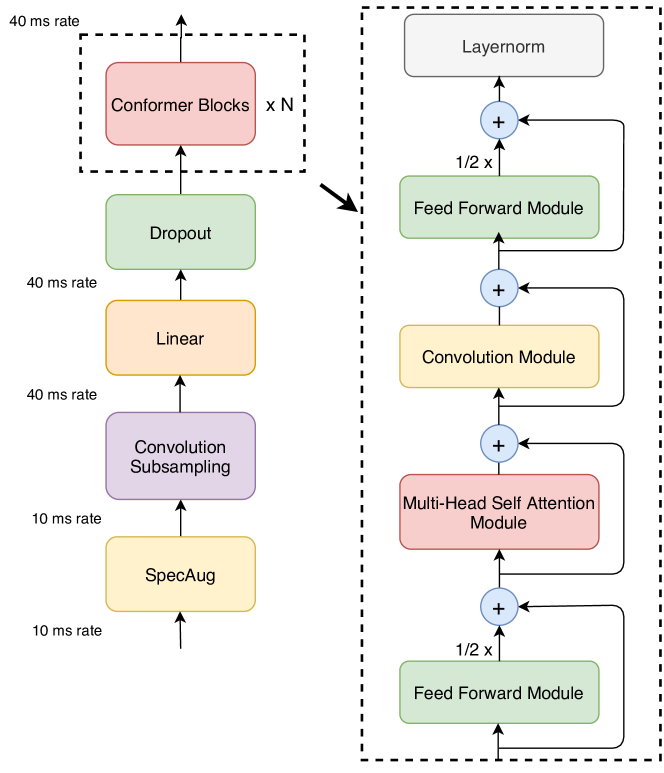
- 피드포워드, 다중 헤드 자기 주의, 컨볼루션, 두 번째 피드포워드로 구성된 네 개의 하위 블록을 갖는 Conformer 인코더를 소개한다.
- 길이 강건성을 위한 MHSA에서 상대적 사인파 위치 인코딩을 사용한다.
- 게이팅 메커니즘(GLU)과 depthwise 컨볼루션이 포함된 컨볼루션 모듈을 구현하고, 배치 노멀과 Swish 활성화를 따른다.
- MHSA와 Convolution 주변에 Macaron-Net에서 영감을 받은 두 개의 반 스텝 FFN 모듈을 도입하고, 절반 스텝 잔차와 최종 층 정규화를 적용한다.
- SpecAugment, 드롭아웃, 변화적 노이즈, Adam 옵티마이저로 학습하고, 디코딩 시 얕은 융합을 위해 3-layer LSTM 언어 모델을 사용한다.
- LibriSpeech에서 10.3M, 30.7M, 118.8M 매개변수를 가진 세 가지 모델 크기(S, M, L)를 평가한다.
실험 결과
연구 질문
- RQ1컨볼루션이 보강된 트랜스포머가 순수 트랜스포머나 CNN보다 음성에서 로컬 및 글로벌 의존성을 더 효율적으로 포착할 수 있는가?
- RQ2아키텍처 선택(Macaron FFN, MHSA 앞/뒤의 컨볼루션, 커널 크기, 헤드 수)이 ASR 성능에 미치는 영향은 무엇인가?
- RQ3Conformer가 LibriSpeech에서 매개변수 예산이 다른 경우 언어 모델의 유무에 따라 어떻게 성능을 보이는가?
주요 결과
| 모델 | 매개변수 수 (M) | WER without LM (test-clean) | WER without LM (test-other) | WER with LM (test-clean) | WER with LM (test-other) | 비고 |
|---|---|---|---|---|---|---|
| Conformer(S) | 10.3 | 2.7 | 6.3 | 2.1 | 5.0 | Dev set and test set results with 10M-parameter regime |
| Conformer(M) | 30.7 | 2.3 | 5.0 | 2.0 | 4.3 | Mid-size model outperforming prior Transformer Transducer |
| Conformer(L) | 118.8 | 2.1 | 4.3 | 1.9 | 3.9 | Large model achieving SOTA on LibriSpeech |
- Conformer는 모델 규모에 관계없이 LibriSpeech에서 최첨단 결과를 달성하며, 예를 들어 대형 모델의 경우 LM 없이 2.1%/4.3% WER이고, LM을 사용할 때 1.9%/3.9%이다.
- 10.3M (S) 모델: 2.7% test-clean / 6.3% test-other LM 없이; 2.1% / 5.0% LM 포함.
- 30.7M (M) 모델: 2.3% test-clean / 5.0% test-other LM 없이; 2.0% / 4.3% LM 포함.
- 118.8M (L) 모델: 2.1% test-clean / 4.3% test-other LM 없이; 1.9% / 3.9% LM 포함.
- 변형 연구에서 컨볼루션 하위 블록과 Macaron FFN 쌍이 중요하며, 컨볼루션을 MHSA 뒤에 배치하는 것이 이로운 점, 더 큰 커널 크기(최대 32)가 성능을 향상시키며, 헤드를 16까지 증가시키면 dev 세트에서 정확도가 향상된다.

더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.