[논문 리뷰] Data thinning for convolution-closed distributions
논문은 합성(closed) 분포에서 하나의 관찰을 두 개(또는 그 이상)의 독립적인 부분으로 분해하여 원래 관찰값의 합으로 되도록 하고, 각 부분이 알려진 매개변수 스케일링까지 같은 분포를 따르도록 하는 데이터 희석(data thinning) 방법을 소개한다. 이를 통해 전통적인 샘플 분할 없이 학습/테스트 검증을 가능하게 한다.
We propose data thinning, an approach for splitting an observation into two or more independent parts that sum to the original observation, and that follow the same distribution as the original observation, up to a (known) scaling of a parameter. This very general proposal is applicable to any convolution-closed distribution, a class that includes the Gaussian, Poisson, negative binomial, gamma, and binomial distributions, among others. Data thinning has a number of applications to model selection, evaluation, and inference. For instance, cross-validation via data thinning provides an attractive alternative to the usual approach of cross-validation via sample splitting, especially in settings in which the latter is not applicable. In simulations and in an application to single-cell RNA-sequencing data, we show that data thinning can be used to validate the results of unsupervised learning approaches, such as k-means clustering and principal components analysis, for which traditional sample splitting is unattractive or unavailable.
연구 동기 및 목표
- 샘플 분할이 적용되지 않는 경우 검증 도구의 필요성을 동기화한다.
- 데이터 희석을 독립적으로 같은 분포를 가지는 단일 관찰의 원래 분포(스케일링에 따라)로의 원리적 분해로 정의한다.
- 희석을 다중 폴드로 확장하고 합성 닫힌 분포의 광범위한 클래스에 적용한다.
- 데이터 희석과 샘플 분할 및 데이터 파편화(data fission)를 비교하고, 클러스터링, 저랭크 근사, 단일세포 RNA 시퀀싱에서의 활용을 설명한다.
제안 방법
- 합성(closed) 분포와 선형 기댓값 속성을 정의한다.
- 단일 관찰 X를 F_λ에서 X^(1)과 X^(2)로 희석하는 알고리즘 1을 제시하고 X^(1) ~ F_{ελ}, X^(2) ~ F_{(1-ε)λ}이며 독립적이고 합이 X가 되도록 한다.
- 정리 1에서 희석이 분포 형태와 독립성을 보존함을 보이고 E[X^(1)] = ε E[X], E[X^(2)] = (1-ε) E[X]를 만족함을 증명한다.
- 다중 폴드 확장(멀티폴드) 희석을 알고리즘 2와 정리 2로 확장하여 X^(m) ~ F_{ε_m λ}이고 폴드 간 독립성을 가지며 합이 X가 되도록 보인다.
- 알려지지 않은 요인 변수(nuisance parameters)의 실용적 측면을 논의하고, 표 2 및 표 3에서 일반 분포에 대한 희석의 세부를 요약한다.
- 희석을 샘플 분할 및 데이터 파편화와 비교하고, 희석이 유리한 설정을 개략한다.
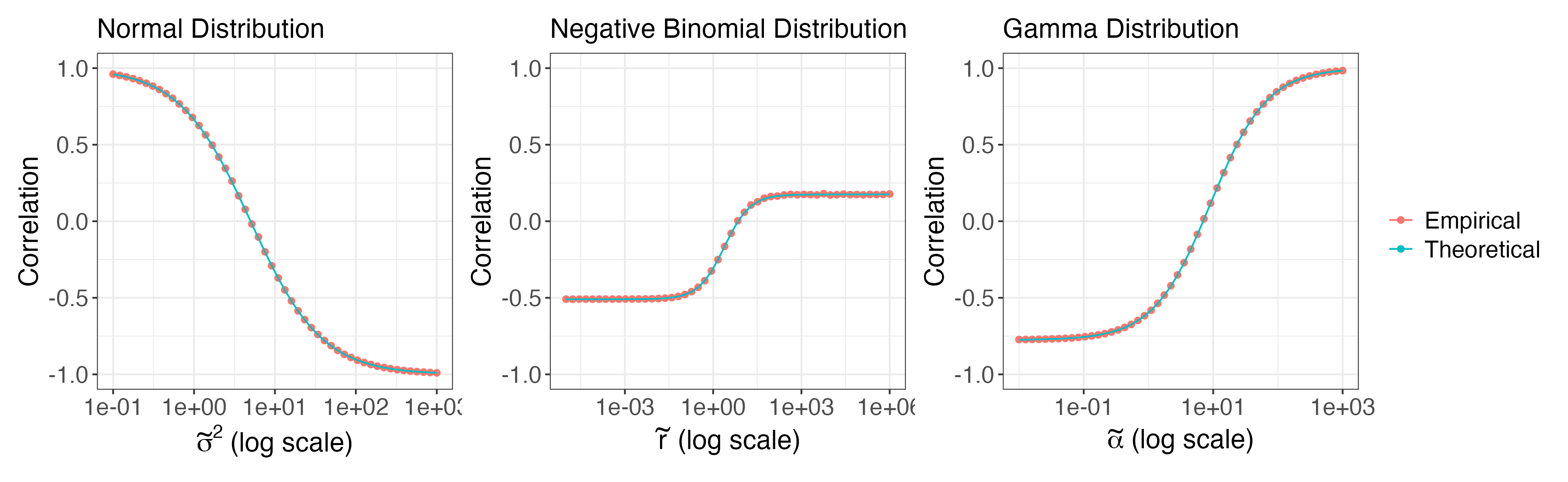
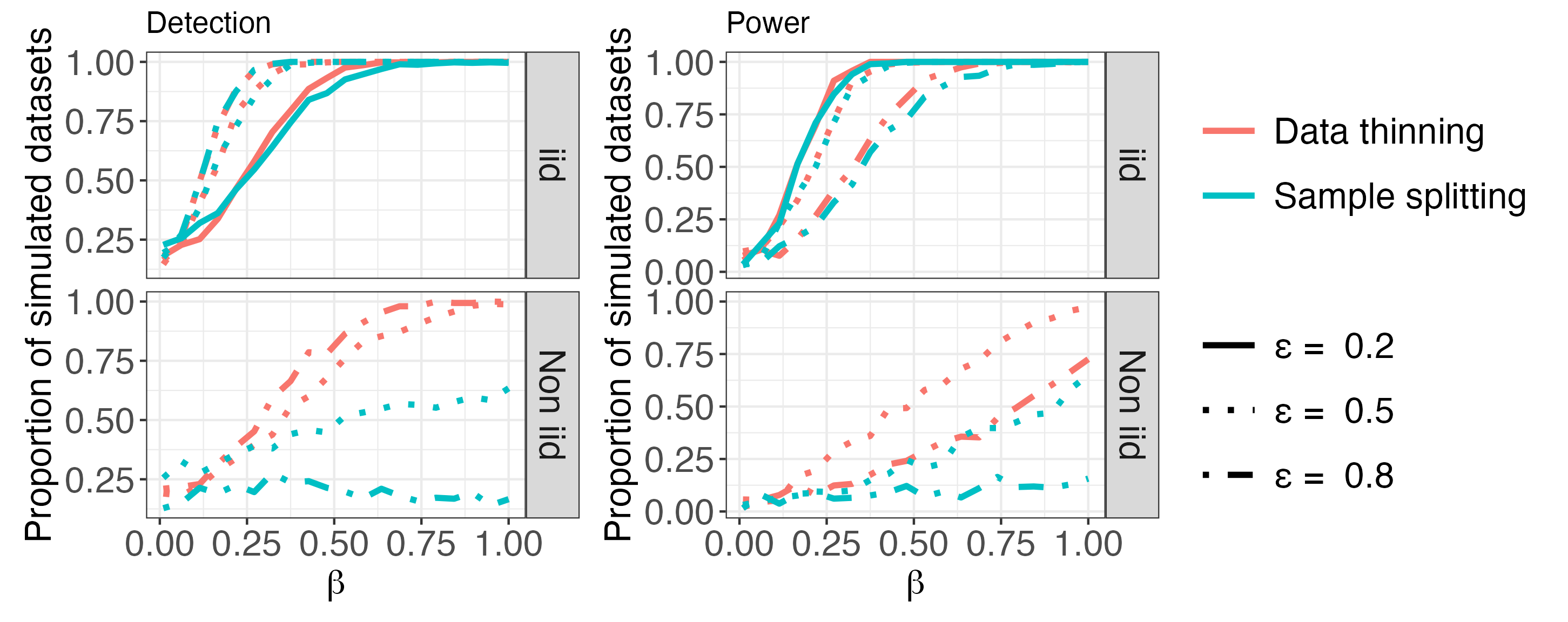
실험 결과
연구 질문
- RQ1합성(closed) 분포에서 하나의 관찰이 독립적인 부분으로 분해되어 원래 분포를 매개변수 스케일링까지 재현할 수 있는가?
- RQ2두 부분에서 다중 폴드로 확장하면서 독립성과 주변 분포를 보존할 수 있는가?
- RQ3데이터 희석이 모델 검증 및 추론을 위한 샘플 분할의 실용적 대안을 제공하는 시나리오는 무엇인가?
- RQ4알려지지 않은 nuisance 매개변수의 영향은 무엇이며, 이러한 잘못된 설정에 대해 희석은 얼마나 강건한가?
- RQ5희석이 클러스터링, 저랭크 매트릭스 근사, 단일세포 RNA 시퀀싱 분석의 검증에 어떻게 작용하는가?
주요 결과
- 데이터 희석은 X^(1)와 X^(2)라는 두 독립 구성요소를 생성하며 X = X^(1) + X^(2)이고 X^(1) ~ F_{ελ}, X^(2) ~ F_{(1-ε)λ}를 만족한다.
- 기본 분포가 선형 기댓값 속성을 만족하면, E[X^(1)] = ε E[X] 및 E[X^(2)] = (1-ε) E[X]를 얻는다.
- 다중 폴드 희석은 임의의 M에 대해 X^(m) ~ F_{ε_m λ}이고 폴드 간 독립성을 유지하며 합이 X가 되도록 일반화된다.
- 본 프레임워크는 가우시안, 푸아송을 넘어 γ, 음이항, 이항, 다항 분포 계열 등 넓은 합성 닫힌 분포에 적용된다.
- 전통적인 샘플 분할 없이 교차 검증과 같은 평가를 가능하게 하며, 시뮬레이션 및 단일세포 RNA 시퀀싱 데이터 검증 시나리오에서 시연된다.
- 본 논문은 nuisance 매개변수의 잘못된 설정이 희석에 미치는 영향을 분석하고, 정보 분배를 위한 ε 선택에 대한 지침을 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.