[논문 리뷰] Decoder-Only or Encoder-Decoder? Interpreting Language Model as a Regularized Encoder-Decoder
본 논문은 Regularized Encoder-Decoder (RED) 프레임워크를 통해 디코더-전용 언어 모델을 이용한 순차-투-순차(seq2seq) 태스크를 분석하고, 주의(attention) 저하를 식별하며, 번역, 요약, 데이터-투-텍스트 작업에서 성능을 개선하기 위한 Partial Attention Language Model (PALM)을 제안한다.
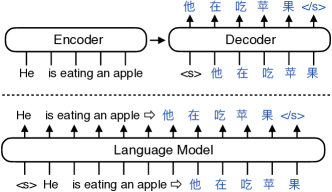
The sequence-to-sequence (seq2seq) task aims at generating the target sequence based on the given input source sequence. Traditionally, most of the seq2seq task is resolved by the Encoder-Decoder framework which requires an encoder to encode the source sequence and a decoder to generate the target text. Recently, a bunch of new approaches have emerged that apply decoder-only language models directly to the seq2seq task. Despite the significant advancements in applying language models to the seq2seq task, there is still a lack of thorough analysis on the effectiveness of the decoder-only language model architecture. This paper aims to address this gap by conducting a detailed comparison between the encoder-decoder architecture and the decoder-only language model framework through the analysis of a regularized encoder-decoder structure. This structure is designed to replicate all behaviors in the classical decoder-only language model but has an encoder and a decoder making it easier to be compared with the classical encoder-decoder structure. Based on the analysis, we unveil the attention degeneration problem in the language model, namely, as the generation step number grows, less and less attention is focused on the source sequence. To give a quantitative understanding of this problem, we conduct a theoretical sensitivity analysis of the attention output with respect to the source input. Grounded on our analysis, we propose a novel partial attention language model to solve the attention degeneration problem. Experimental results on machine translation, summarization, and data-to-text generation tasks support our analysis and demonstrate the effectiveness of our proposed model.
연구 동기 및 목표
- seq2seq 태스크에서 인코더-디코더 아키텍처와 디코더-전용 언어 모델 간의 철저한 비교를 자극한다.
- 디코더-전용 모델에서의 주의 저하 문제와 이것이 소스 주의에 미치는 영향을 특징짓는다.
- 공정한 비교를 촉진하기 위한 정규화된 인코더-디코더 (RED) 프레임워크를 개발하고 구성 요소를 분석한다.
- LM의 이점을 활용하면서 저하를 완화하기 위한 Partial Attention Language Model (PALM)을 제안한다.
- 기계 번역, 요약 및 데이터-투-텍스트 생성 데이터셋에서 PALM을 실증적으로 검증한다.
제안 방법
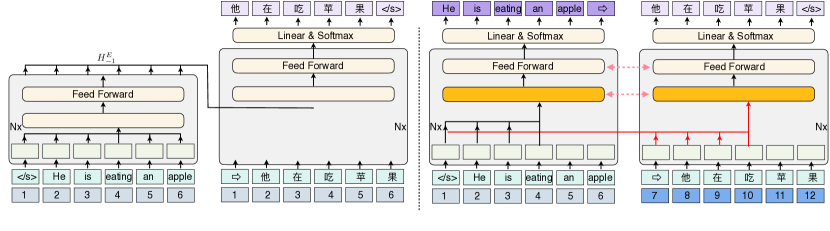
- ED와의 공정한 비교를 위해 인코더와 디코더로 LM의 동작을 재현하는 Regularized Encoder-Decoder (RED) 프레임워크를 정의한다.
- RED 내에서 LM 동작을 모방하기 위해 단방향 크로스 어텐션, Source Auto-Encoder(SAE), 파라미터 공유, 층별 협력, 연속 위치 인코딩을 도입한다.
- 단방향 크로스 어텐션에서 주의 저하를 설명하기 위한 주의 민감도(야코비안 경계)의 이론적 분석을 수행한다.
- 소스에 초점을 맞춘 PA 어텐션 가지를 더하고, 양방향 소스 어텐션과 별도 위치 인코딩, 언어 임베딩을 사용하는 PALM을 제안한다.
- 구성 요소의 효과를 분리하기 위해 PALM 변형 및 체계적 제거 실험들(PALM w/o SAE 등)을 제시한다.
- 표준 지표(BLEU, ROUGE, METEOR, CIDEr, NIST)를 사용하여 MT, 요약, 데이터-투-텍스트 태스크를 평가한다.
실험 결과
연구 질문
- RQ1디코더-전용 LM 아키텍처가 본질적으로 seq2seq 태스크에서 ED보다 성능이 떨어지는가, 아니면 정규화된 LM 유사 구조가 격차를 해소할 수 있는가?
- RQ2LM 기반 seq2seq 모델에서 주의 저하의 원인은 무엇이며, 이것이 생성 단계에 걸친 소스-주 의 민감도에 어떻게 영향을 미치는가?
- RQ3PALM 아키텍처가 LM의 이점을 보존하면서 주의 저하를 완화할 수 있는가?
- RQ4RED/PALM 변형들이 ED 및 LM 기준선에 비해 MT, 요약, 데이터-투-텍스트 벤치마크에서 어떤 성과를 보이는가?
주요 결과
| 모델 | De-En | En-De | It-En | En-It | En-Fr | Es-En | En-Es | Ru-En | En-Ru | He-En | En-He | Ro-En | En-Ro | 평균 | 파라미터 수 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ED | 34.18 | 28.00 | 31.96 | 29.42 | 40.86 | 40.99 | 37.53 | 23.09 | 18.20 | 38.09 | 25.41 | 38.14 | 28.30 | 31.86 | 47.1M |
| LM | 33.19 | 26.43 | 30.92 | 28.64 | 39.16 | 39.33 | 36.67 | 22.25 | 17.53 | 34.81 | 24.35 | 35.51 | 27.02 | 30.45 | 29.3M |
| LM-SPE | 33.35 | 27.35 | 31.36 | 28.87 | 39.93 | 39.69 | 36.99 | 21.89 | 17.98 | 34.89 | 24.80 | 35.19 | 27.72 | 30.77 | 29.3M |
| LM-LE | 33.58 | 27.46 | 31.38 | 29.03 | 40.14 | 39.87 | 37.05 | 22.24 | 18.08 | 34.80 | 24.31 | 35.76 | 27.96 | 30.90 | 29.3M |
| LM-PA | 34.54 | 28.35 | 32.01 | 29.70 | 40.15 | 40.58 | 37.24 | 22.98 | 18.45 | 35.64 | 25.37 | 37.35 | 28.02 | 31.57 | 35.6M |
| PreLM | 33.90 | 27.88 | 31.77 | 29.35 | 40.53 | 40.41 | 37.46 | 22.80 | 18.11 | 35.96 | 24.78 | 37.55 | 28.11 | 31.43 | 29.3M |
| PALM | 34.73 | 28.59 | 32.22 | 29.83 | 40.31 | 40.91 | 37.61 | 23.27 | 18.74 | 37.00 | 25.29 | 37.59 | 28.75 | 31.91 | 35.6M |
| PALM w/o SAE | 34.03 | 28.30 | 31.83 | 29.42 | 39.87 | 40.65 | 37.25 | 22.21 | 17.92 | 37.06 | 24.89 | 37.09 | 28.40 | 31.46 | 35.6M |
- 생성 단계가 진행될수록 소스에 대한 주의가 감소하는 등 주의 저하로 인해 LM은 여러 seq2seq 태스크에서 ED보다 성능이 떨어진다.
- 이론적 상한은 단방향 크로스 어텐션이 대상이 커질수록 소스 입력에 대한 민감도가 더 작아진다는 것을 보여 주어 저하를 설명한다.
- PALM은 생성 길이에 관계없이 고정된 PA 주의 경로를 추가하고 양방향 소스 주의와 별도 위치 인코딩을 사용하여 저하를 완화한다.
- PALM은 LM 및 LM 변형들보다 일관되게 우수하며 보고된 벤치마크에서 ED 성능에 접근하거나 능가한다.
- PALM은 IWSLT’14에서 평균 BLEU가 LM-PA 기반보다 높고 ED를 넘는다(표 1). 또한 WebNLG, E2E, XSUM 데이터셋에서 METEOR, ROUGE-L, CIDEr, NIST 점수가 우수하게 향상된다(표 4–6).
- 절단 실험은 SAE가 성능에 기여함을 보이고, PALM w/o SAE는 LM 수준으로 성능이 감소한다.
- 이 방법은 ED 및 LM 기준선에 비해 파라미터 수를 줄이면서도 우수하거나 경쟁력 있는 성능을 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.