[논문 리뷰] Direct speech-to-speech translation with a sequence-to-sequence model
이 논문은 중간 텍스트 표현 없이 한 언어의 음성에서 다른 언어의 음성으로 직접 번역하는 엔드 투 엔드 시퀀스 투 시퀀스 모델인 Translatotron을 제안한다. 학습을 안정화시키기 위해 학습 중에 음성에서 텍스트로의 번역 헤드를 활용하는 다중 작업 학습을 도입하면서도, 원본 화자 음성의 특성을 출력에 유지하는 음성 이동 기능을 제공한다. 비록 성능은 계단식 시스템에 뒤지지만, 엔드 투 엔드 학습과 화자 신원 유지가 가능한 직접 음성에서 음성으로의 번역의 가능성을 입증한다.
We present an attention-based sequence-to-sequence neural network which can directly translate speech from one language into speech in another language, without relying on an intermediate text representation. The network is trained end-to-end, learning to map speech spectrograms into target spectrograms in another language, corresponding to the translated content (in a different canonical voice). We further demonstrate the ability to synthesize translated speech using the voice of the source speaker. We conduct experiments on two Spanish-to-English speech translation datasets, and find that the proposed model slightly underperforms a baseline cascade of a direct speech-to-text translation model and a text-to-speech synthesis model, demonstrating the feasibility of the approach on this very challenging task.
연구 동기 및 목표
- 중간 텍스트 표현을 생략하는 직접적인 엔드 투 엔드 음성에서 음성으로의 번역 시스템을 개발하기 위해.
- 직접 S2ST를 위한 학습을 안정화시키기 위해 음성에서 텍스트로의 번역 헤드를 활용한 다중 작업 학습이 엔드 투 엔드 추론에 영향을 주지 않도록 하는지 조사하기 위해.
- 번역된 출력 음성에서 원본 화자의 음성을 유지하는 음성 이동을 가능하게 하기 위해.
- 실세계 스페인어에서 영어로의 음성 번역 데이터셋에서 모델의 성능을 평가하고, 계단식 기반 모델과 비교하기 위해.
- 통합된 엔드 투 엔드 프레임워크 내에서 다국어 억양과 화자 신원 이동을 학습할 수 있는지의 가능성 탐색하기 위해.
제안 방법
- 입력 음성 스펙트로그램과 화자 임베딩을 처리하기 위해 어텐션 메커니즘을 갖춘 8층 양방향 LSTM 인코더 스택을 사용한다.
- 이중 스트림 디코더를 적용한다: 하나는 목표 스펙트로그램 생성을 위해, 다른 하나는 자소음 예측을 위해 사용하여 보조 번역 작업을 통한 다중 작업 학습을 가능하게 한다.
- 화자 인코더는 기준 발화에서 화자 임베딩을 추출하며, 이는 학습 중 음성 이동 과정을 조절하는 데 사용된다.
- 합성 타겟과 실제 음성 데이터의 조합을 사용하여 엔드 투 엔드로 학습하며, 번역, 자소음 인식, 음성 이동에 대한 손실 함수를 사용한다.
- 원본 음성과 목표 화자에서의 화자 임베딩을 디코더에 조건으로 주어, 원본 화자 음성으로의 합성 구현을 달성한다.
- 예측된 스펙트로그램을 웨이브폼 출력으로 변환하기 위해 보코더를 사용한다.
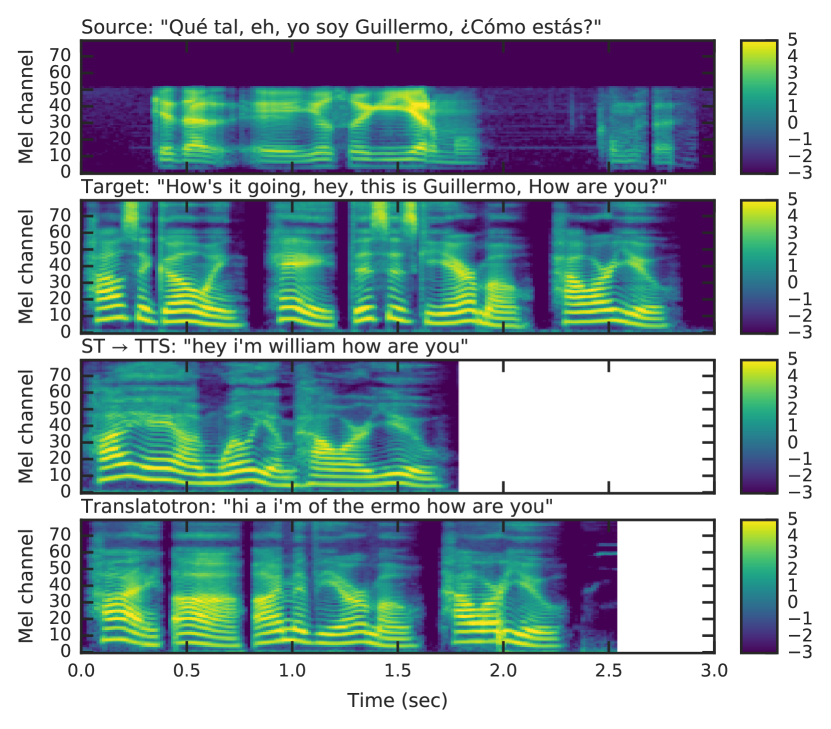
실험 결과
연구 질문
- RQ1엔드 투 엔드 시퀀스 투 시퀀스 모델이 중간 텍스트 표현 없이 직접 음성에서 음성으로의 번역을 달성할 수 있는가?
- RQ2보조 음성에서 텍스트로의 번역 헤드를 활용한 다중 작업 학습이 직접 S2ST를 위한 학습 안정화에 얼마나 효과적인가?
- RQ3모델이 번역된 출력 음성에서 원본 화자의 음성을 어느 정도 유지할 수 있는가?
- RQ4직접 S2ST 모델의 성능은 음성에서 텍스트 번역과 텍스트에서 음성 합성의 계단식 시스템과 비교해 어떻게 되는가?
- RQ5특히 정렬 문제와 데이터 부족 문제를 고려할 때, 직접 S2ST 모델을 학습하는 데 주요 과제는 무엇인가?
주요 결과
- 원본 화자 음성 조건에서 모델은 BLEU 점수 33.6을 기록했으며, 정답 목표 화자 임베딩을 사용할 경우 36.2로 높아진다.
- 모델의 번역 품질은 계단식 ST+TTS 기반 모델보다 略로 낮아, 다중 작업 감독에도 불구하고 직접 학습이 여전히 도전적임을 시사한다.
- 원본 화자로 조건을 주었을 경우 음성 이동 성능은 크게 떨어지며(MOS-similarity: 1.85), 정답 목표 화자 사용 시(MOS-similarity: 3.30)보다 낮아, 언어 간 화자 임베딩의 일반화 능력이 열악함을 시사한다.
- 무작위 목표 발화로 조건을 주었을 경우 BLEU 점수(35.4)와 MOS 점수(3.08)가 원본 화자 조건과 유사하여, 화자 임베딩에서 내용 유출이 유의미하게 발생하지 않음을 나타낸다.
- 모델은 공통어와 고유명사(예: 'Guillermo'가 'William'로 번역되지 않고 그대로 유지됨)를 성공적으로 유지하며, 직접적인 발음 유지 경향을 보임을 시사한다.
- 보조 번역 작업을 통한 엔드 투 엔드 학습이 제한된 병렬 음성 데이터로도 직접 S2ST에 대한 안정적인 학습을 가능하게 함을 입증한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.