[논문 리뷰] Distilled Feature Fields Enable Few-Shot Language-Guided Manipulation
두 번역된 텍스트의 핵심 요약을 한국어로 제공합니다. 논문은 Distilled Feature Fields (DFFs)를 제시하여 2D 비전-언어 프라이어와 3D 기하학을 NeRFs를 통해 융합하고, 파인튜닝 없이도 Few-shot 및 언어 지시가 있는 6-DOF 로봇 조작을 가능하게 합니다. CLIP/DINO 특성을 3D 특징 필드로 증류하여 오픈 세트 물체 그립 및 언어 기반 작업을 시연합니다.
Self-supervised and language-supervised image models contain rich knowledge of the world that is important for generalization. Many robotic tasks, however, require a detailed understanding of 3D geometry, which is often lacking in 2D image features. This work bridges this 2D-to-3D gap for robotic manipulation by leveraging distilled feature fields to combine accurate 3D geometry with rich semantics from 2D foundation models. We present a few-shot learning method for 6-DOF grasping and placing that harnesses these strong spatial and semantic priors to achieve in-the-wild generalization to unseen objects. Using features distilled from a vision-language model, CLIP, we present a way to designate novel objects for manipulation via free-text natural language, and demonstrate its ability to generalize to unseen expressions and novel categories of objects.
연구 동기 및 목표
- 비우주적이고 어수분한 환경에서 3D 기하학과 2D 시각 언어 프리어를 결합하여 로봇 조작의 강건성을 달성한다.
- 사전 학습된 2D 모델에서 추출한 증류된 3D 특징 필드를 활용하여 Few-shot 그리핑/배치를 가능하게 한다.
- task-specific한 파인튜닝 없이 자유 텍스트 언어 지시로 새로운 물체를 선택하고 조작할 수 있도록 한다.
제안 방법
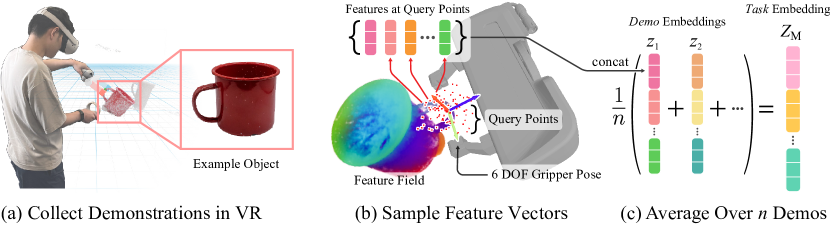
- 시각 기반 기초 모델에서 얻은 조밀한 2D 특징을 NeRF 스타일의 3D 부피로 증류하여 Distilled Feature Field (DFF)를 구축한다.
- 3D 증류를 위해 CLIP의 언어 공간에 맞춘 patch 수준의 조밀한 특징을 얻기 위해 MaskCLIP를 사용한다.
- 그리퍼 프레임에서 쿼리 포인트 세트를 샘플링하고 장면의 특징 필드에서 알파 가중치를 받는 특징을 집계하여 6-DOF 그리핑/배치 자세를 표현한다.
- 작업 임베딩 Z_M(데모에서 평균화)와 변환된 포인트에서 질의된 특징 필드 사이의 코사인 유사도를 통해 후보 그리핑을 추론하고, 자세 최적화 및 충돌 필터링을 수행한다.
- CLIP 임베딩을 통해 언어 쿼리와 가장 근접한 데모를 검색하고 언어 가이드 항을 자세 목표에 추가하여 재학습 없이 자유 텍스트 지시로의 조작을 가능하게 한다.

실험 결과
연구 질문
- RQ1Distilled Feature Fields가 2D 비전-언어 프라이어와 3D 기하를 융합하여 복잡한 장면에서 열린 형태의 Few-shot 조작을 가능하게 하는가?
- RQ2언어 설명이 보이지 않는 물체 범주와 표현으로 일반화하도록 조작을 가이드하는 정도는 어느 정도인가?
- RQ3DFF가 DINO 및 CLIP 특성에서 증류된 6-DOF 그리핑/배치의 성능은 기준치와 비교하여 어떤가?
- RQ4새로운 물체 범주에서 파인튜닝 없이 제로샷으로 언어 조건 조작 파이프라인의 효과는 어느 정도인가?
주요 결과
- DFF를 통해 보이지 않는 물체 시나리오에서 6-DOF 그리핑 및 배치에 대한 열린 엔드 시맨틱 이해를 가능하게 한다.
- DINO ViT와 CLIP 기반 특징의 융합은 기하학적 및 의미적 프라이어를 보완적으로 제공하며, 밀도, 색상 또는 중간 NeRF 특징에 의존하는 baselines보다 조작 성공률을 향상시킨다.
- CLIP 정렬 특성 필드를 사용하는 언어 지향 조작은 자유 텍스트 질의를 통해 물체를 선택하고 조작하는 것을 가능하게 하며, 배포 범위 밖의 신규 범주에 대한 일반화를 가능하게 한다.
- 시스템은 여러 작업과 물체에서 혼잡한 환경에서 성공적인 그립 및 배치를 시연하지만, 일부 실패는 그립 회전 정확도와 관계/서술적 언어 세부 정보를 CLIP이 포착하는 데 한계 때문인 것으로 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.