[논문 리뷰] DiverseVul: A New Vulnerable Source Code Dataset for Deep Learning Based Vulnerability Detection
DiverseVul은 18,945개의 취약한 함수와 150개의 CWE에 걸친 797개 프로젝트에 걸쳐 7,514 커밋에서 취약한 함수 18,945개와 비취약한 함수 330,492개를 제공하며, 네 가지 계열의 11개 DL 아키텍처를 분석하여 데이터 규모와 코드 특화 사전학습이 취약점 탐지 성능의 핵심 요인임을 강조합니다.
We propose and release a new vulnerable source code dataset. We curate the dataset by crawling security issue websites, extracting vulnerability-fixing commits and source codes from the corresponding projects. Our new dataset contains 18,945 vulnerable functions spanning 150 CWEs and 330,492 non-vulnerable functions extracted from 7,514 commits. Our dataset covers 295 more projects than all previous datasets combined. Combining our new dataset with previous datasets, we present an analysis of the challenges and promising research directions of using deep learning for detecting software vulnerabilities. We study 11 model architectures belonging to 4 families. Our results show that deep learning is still not ready for vulnerability detection, due to high false positive rate, low F1 score, and difficulty of detecting hard CWEs. In particular, we demonstrate an important generalization challenge for the deployment of deep learning-based models. We show that increasing the volume of training data may not further improve the performance of deep learning models for vulnerability detection, but might be useful to improve the generalization ability to unseen projects. We also identify hopeful future research directions. We demonstrate that large language models (LLMs) are a promising research direction for ML-based vulnerability detection, outperforming Graph Neural Networks (GNNs) with code-structure features in our experiments. Moreover, developing source code specific pre-training objectives is a promising research direction to improve the vulnerability detection performance.
연구 동기 및 목표
- 현실 세계의 프로젝트와 보안 이슈로부터 취약한 함수와 비취약한 함수의 대규모이면서 다양한 공개 데이터셋을 생성한다.
- 이 데이터셋과 이전 데이터셋을 사용하여 취약점 탐지에 대한 광범위한 딥러닝 아키텍처를 벤치마크한다.
- 훈련 데이터 양, 모델 아키텍처, 사전학습 작업이 취약점 탐지 성능에 미치는 영향을 조사한다.
- 레이블 노이즈 및 일반화 문제를 평가하고, 보이지 않는 프로젝트에서의 성능을 포함한다.
- 대형 언어 모델과 코드 특화 사전학습을 이용한 ML 기반 취약점 탐지 발전을 위한 유망한 방향을 제시한다.
제안 방법
- 보안 이슈 사이트를 크롤링하여 취약점 보고서와 수정 커밋을 얻는다.
- 복제된 프로젝트에서 커밋 전 버전을 취약한 것으로 라벨링하고 커밋 후 버전을 비취약으로 라벨링하여 취약한 함수와 비취약한 함수를 추출한다.
- 가능하면 프로젝트 및 CWE 주석을 보존하면서 MD5로 함수를 중복 제거한다.
- GNNs 및 트랜스포머/LLMs를 포함한 4 계열의 11개 모델 아키텍처를 세 가지 데이터 설정(CVEFixes, Previous, Previous+DiverseVul)에서 평가한다.
- 수동 샘플링을 통한 레이블 노이즈를 점검하여 레이블 정확도를 추정한다(대략 DiverseVul의 경우 ~60%).
- 데이터 크기의 효과를 F1, TP 비율, FP 비율에 대해 연구하기 위해 DiverseVul의 포함 여부에 따른 모델 성능을 비교한다.
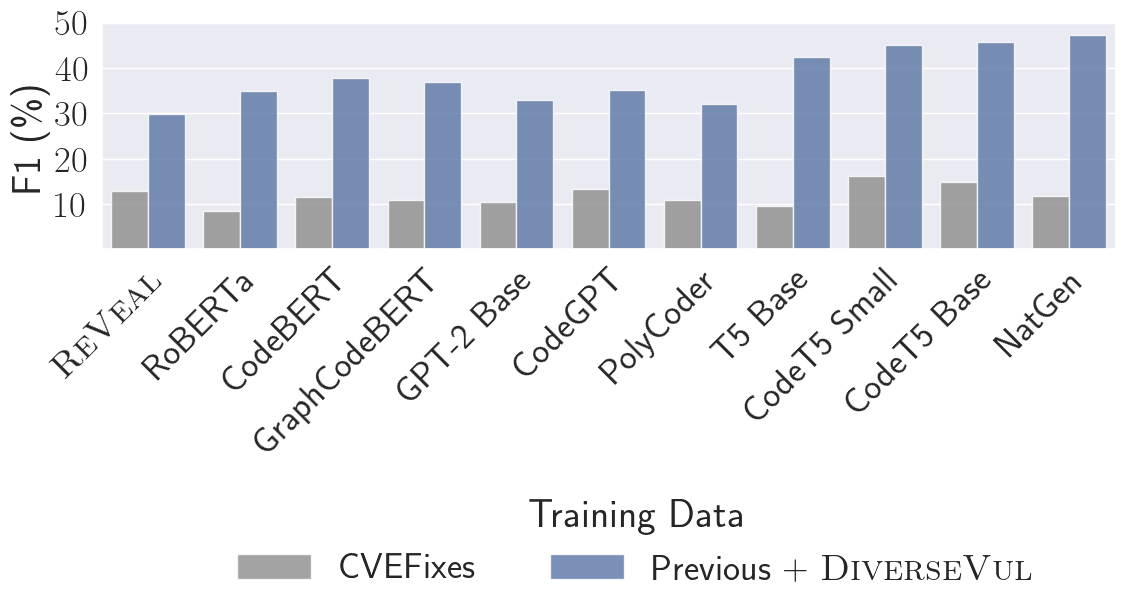
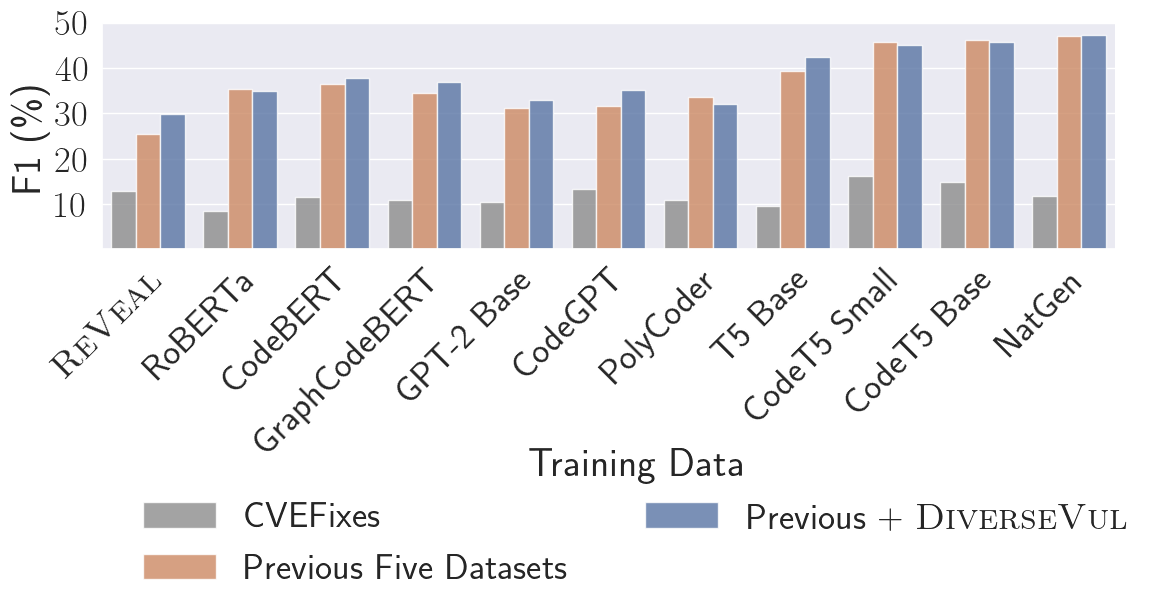
실험 결과
연구 질문
- RQ1훈련 데이터를 증가시키는 것이(DiverseVul 및 다른 데이터셋을 통해) 모델 계열 전반의 취약점 탐지 성능에 어떤 영향을 미치는가?
- RQ2대규모이고 다양한 취약점 데이터셋에서 학습될 때 대형 언어 모델이 그래프 기반 모델보다 우수한가?
- RQ3코드에 대해 취약점 탐지를 가장 잘 향상시키는 사전학습 목표는 무엇인가?
- RQ4모델이 보지 않은 프로젝트에 얼마나 잘 일반화되는가, 일반화 격차를 완화하는 기술은 무엇인가?
- RQ5취약점 데이터셋의 레이블 노이즈의 정도와 영향은 어느 정도이며, 이것이 모델 평가에 어떻게 영향을 미치는가?
주요 결과
- DiverseVul은 18,945개의 취약한 함수와 330,492개의 비취약한 함수를 7,514 커밋에서 추가하고, 150개의 CWE에 걸친 797개 프로젝트에 걸쳐 있습니다.
- CVEFixes만으로는 아키텍처 차이가 작지만, 더 큰 데이터셋에서 LLM이 GNN보다 현저하게 우수합니다.
- 결합된 Previous+DiverseVul 테스트 세트에서 가장 좋은 F1 점수는 47.2%, 43.3%의 진양성률과 3.5%의 위양성률을 보입니다.
- 코드 특화 작업으로 사전학습된 LLM들(예: CodeT5 Small/Base, NatGen)이 GNN보다 가장 큰 성능 향상을 가져옵니다.
- 보지 않은 프로젝트에서의 성능은 현저히 떨어지며(예: 보인 프로젝트에서의 F1이 49%에서 보이지 않는 프로젝트에서 9.4%로 하락), 일반화 문제를 강조합니다.
- 커밋 기반 신호를 통한 취약점 레이블의 정확도는 DiverseVul에서 약 60%로, 데이터셋 전반에 걸친 주목할 만한 레이블 노이즈를 시사합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.