[논문 리뷰] DoctorGLM: Fine-tuning your Chinese Doctor is not a Herculean Task
본 논문은 이중 언어의 중국어 의료 대화 모델(ChatGLM-6B)을 LoRA 및 기타 효율성 기법을 사용해 DoctorGLM으로 미세조정하는 것을 시연하고, 보급형 하드웨어에서 의료 도메인에 대한 비용 효율적인 미세조정을 달성한다. 다국어 의료 LLM들을 위한 저비용 파이프라인을 제공하고 실용적인 결과와 한계를 공유한다.
The recent progress of large language models (LLMs), including ChatGPT and GPT-4, in comprehending and responding to human instructions has been remarkable. Nevertheless, these models typically perform better in English and have not been explicitly trained for the medical domain, resulting in suboptimal precision in diagnoses, drug recommendations, and other medical advice. Additionally, training and deploying a dialogue model is still believed to be impossible for hospitals, hindering the promotion of LLMs. To tackle these challenges, we have collected databases of medical dialogues in Chinese with ChatGPT's help and adopted several techniques to train an easy-deploy LLM. Remarkably, we were able to fine-tune the ChatGLM-6B on a single A100 80G in 13 hours, which means having a healthcare-purpose LLM can be very affordable. DoctorGLM is currently an early-stage engineering attempt and contain various mistakes. We are sharing it with the broader community to invite feedback and suggestions to improve its healthcare-focused capabilities: https://github.com/xionghonglin/DoctorGLM.
연구 동기 및 목표
- 의료 분야 및 비영어권 언어에 맞춘 언어 모델 개발을 촉진한다.
- 중국어 의료 대화 모델을 미세조정하기 위한 저비용의 엔드투엔드 파이프라인을 설명한다.
- 저렴한 하드웨어에서 의료 중심 LLM을 가능하게 하는 기법들을 선보인다.
제안 방법
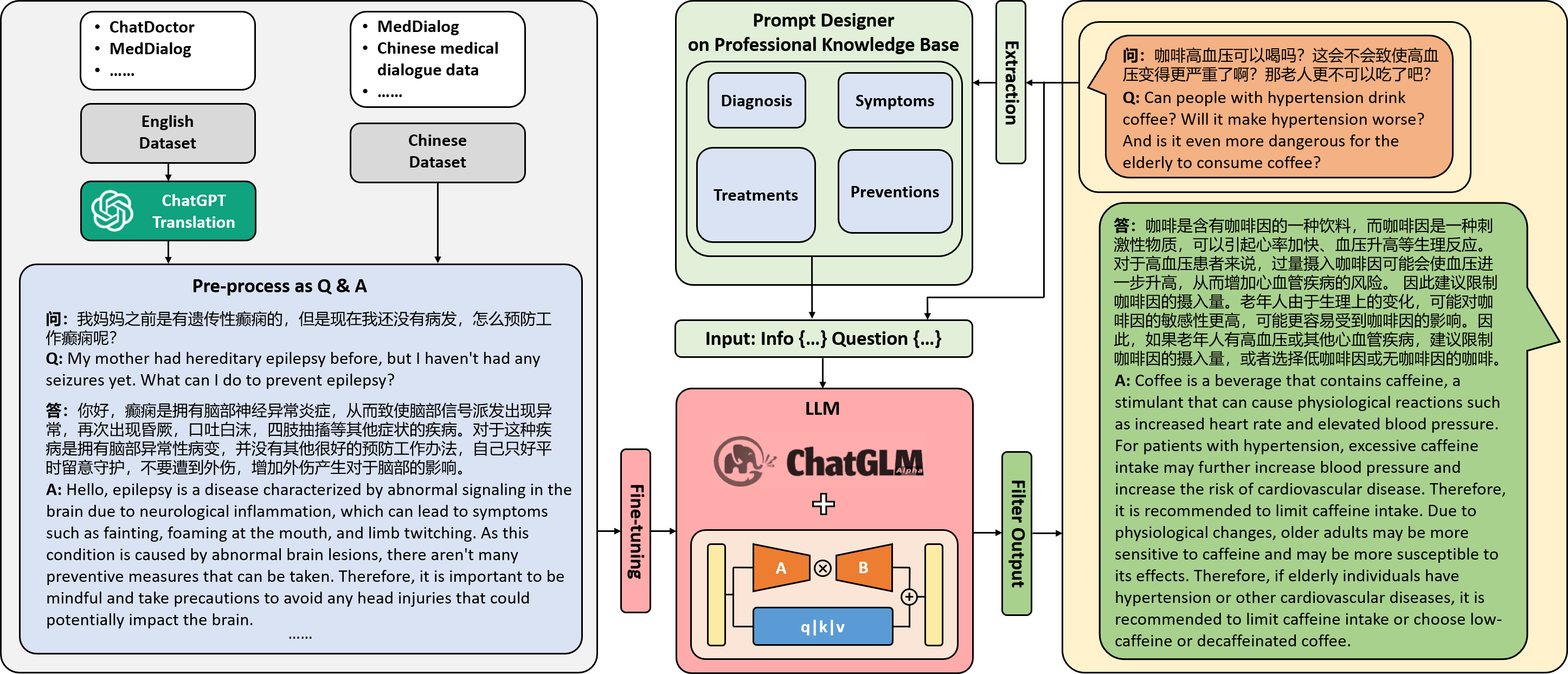
- A100 80G GPU를 사용하여 중국어 의료 대화 데이터에 LoRA로 ChatGLM-6B를 미세조정한다.
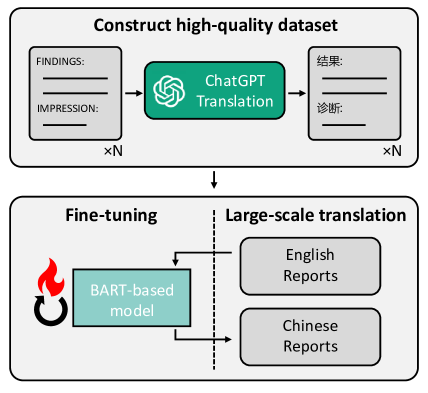
- 영어 의료 데이터셋을 ChatGPT를 통해 중국어로 번역하고 BART 기반 모델로 증류한다.
- 질병 지식(Merck Manual-derived)을 활용한 프롬프트 설계 모듈을 도입하여 응답을 안내한다.
- 매개변수 효율적인 미세조정을 위한 LoRA와 P-tuning V2를 비교한다.
- 출력 다양성을 관리하기 위해 top-p와 temperature 설정으로 생성 품질을 평가한다.
실험 결과
연구 질문
- RQ1의료 중심 LLM을 자원 효율적인 방법으로 중국어에서 효과적으로 미세조정할 수 있는가?
- RQ2사내 데이터로 중국어 의료 대화 모델을 학습하는 데 필요한 하드웨어 및 시간 비용은 어느 정도인가?
- RQ3의료 분야에서 미세조정 효율성과 성능 측면에서 LoRA와 P-tuning V2의 비교는 어떠한가?
- RQ4프롬프트 설계 모듈이 의료 응답의 신뢰성과 정확도 향상에 어떤 역할을 하는가?
- RQ5이러한 모델의 병원 규모 사용에 대한 실용적 한계와 배포 고려사항은 무엇인가?
주요 결과
- LoRA를 사용하여 중국어 의료 대화에 대해 DoctorGLM를 단일 A100 80G GPU에서 13시간에 미세조정하는 것이 가능하다.
- 설명된 설정에서 100,000 QA 쌍에 대한 미세조정 비용은 약 18.75 USD로 보고된다.
- 추론은 약 13 GB 메모리의 일반 소비자용 GPU에서 수행할 수 있지만 배포 제약이 있다.
- LoRA와 P-tuning V2는 매개변수 효율성 측면에서 서로 다른 트레이드오프를 가진 유사한 성능을 제공한다.
- 저자들은 다수의 기술적 한계를 인정하고 이를 초기 단계의 엔지니어링 노력으로 강조한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.