[논문 리뷰] EEGFormer: Towards Transferable and Interpretable Large-Scale EEG Foundation Model
EEGFormer는 1.7TB의 대규모 비라벨 EEG 데이터에 대해 이산 벡터 양자화 Transformer를 사전 학습하여 해석 가능한 코드북 토큰으로 보편적이고 이전 가능한 표현을 학습하고, 다운스트림 성능과 신생아 발작 탐지로의 전이성을 강하게 입증한다.
Self-supervised learning has emerged as a highly effective approach in the fields of natural language processing and computer vision. It is also applicable to brain signals such as electroencephalography (EEG) data, given the abundance of available unlabeled data that exist in a wide spectrum of real-world medical applications ranging from seizure detection to wave analysis. The existing works leveraging self-supervised learning on EEG modeling mainly focus on pretraining upon each individual dataset corresponding to a single downstream task, which cannot leverage the power of abundant data, and they may derive sub-optimal solutions with a lack of generalization. Moreover, these methods rely on end-to-end model learning which is not easy for humans to understand. In this paper, we present a novel EEG foundation model, namely EEGFormer, pretrained on large-scale compound EEG data. The pretrained model cannot only learn universal representations on EEG signals with adaptable performance on various downstream tasks but also provide interpretable outcomes of the useful patterns within the data. To validate the effectiveness of our model, we extensively evaluate it on various downstream tasks and assess the performance under different transfer settings. Furthermore, we demonstrate how the learned model exhibits transferable anomaly detection performance and provides valuable interpretability of the acquired patterns via self-supervised learning.
연구 동기 및 목표
- 대규모 unlabeled 데이터에서 보편적인 EEG 표현 학습을 데이터셋 특정 사전 학습이 아니라 촉진한다.
- EEG 신호를 위한 이산 표현(벡터 양자화) 사전 학습 프레임워크를 개발한다.
- EEG 파운데이션 모델의 다수의 다운스트림 태스크 및 데이터세트로의 전이 가능성을 조사한다.
- 학습된 이산 코드북과 토큰을 분석하여 해석 가능한 통찰을 제공한다.
- TUH 기반 다운스트림 태스크에서의 성능을 평가하고 신생아 발작 탐지로의 전이를 평가한다.
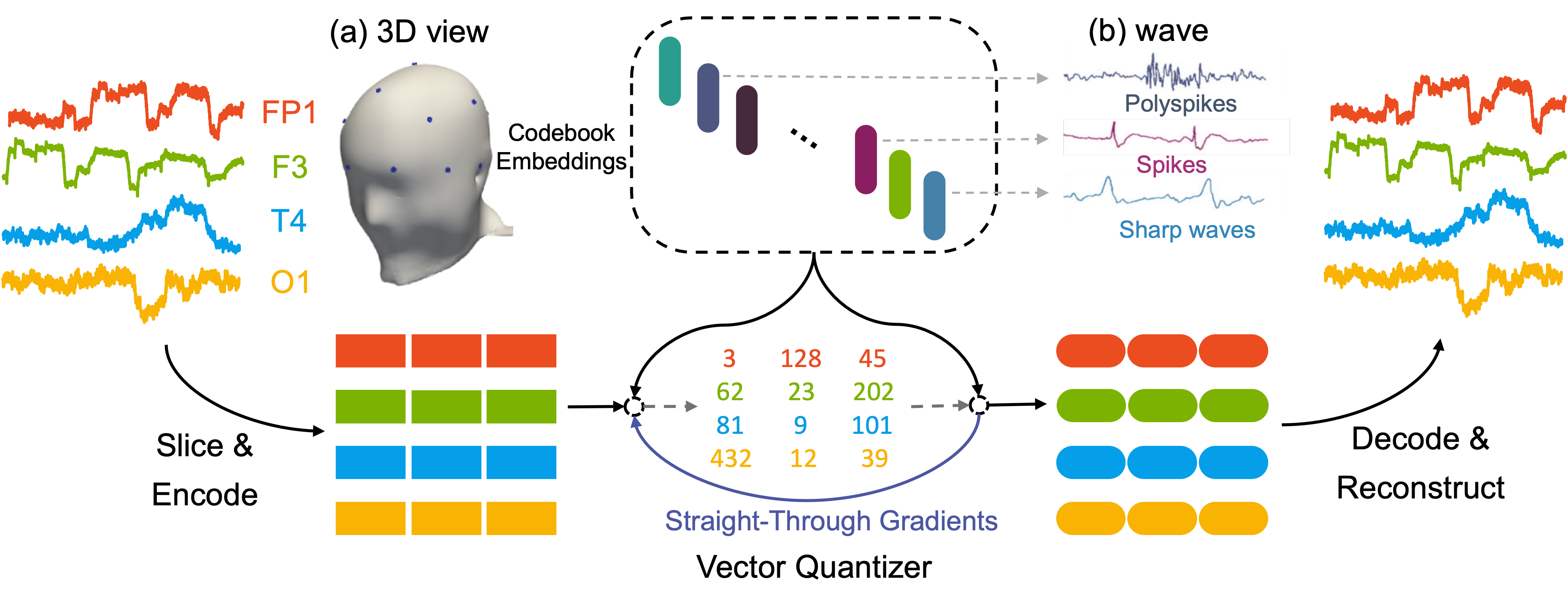
제안 방법
- EEG를 다변량 시계열로 표현하고 패치를 분할한다.
- 포지션 임베딩을 사용하여 채널별로 Transformer 인코더로 패치를 인코딩한다.
- 인코더 출력을 벡터 양자화 코드북으로 양자화하여 이산 토큰을 얻는다.
- 이산 토큰은 얕은 Transformer 디코더로 디코딩하여 입력을 재구성한다(재구성 손실+VQ 페널티).
- 재구성 오차와 벡터 양자화 손실(코드북 사용 및 약정 terms)을 결합한 공동 목적어로 학습한다.
- 다운스트림 태스크를 위해 사전 학습된 인코더/디코더(또는 선택적으로 코드북)를 미세조정한다.
실험 결과
연구 질문
- RQ1대규모 EEG 데이터에 대한 벡터 양자화, Transformer 기반의 사전 학습이 여러 EEG 태스크에 걸쳐 보편적 표현으로의 전이를 이끌 수 있는가?
- RQ2이산 표현 학습이 End-to-end 방법과 비교하여 EEG 모델의 해석 가능성을 향상시키는가?
- RQ3EEGFormer가 TUH 코퍼스 외의 데이터셋(예: 신생아 발작 탐지)으로 얼마나 잘 전이되는가?
주요 결과
| 모델 | 사전학습 | 지표 | TUAB | TUAR | TUSL | TUSZ | 신생아 |
|---|---|---|---|---|---|---|---|
| EEGNet | ✗ | AUROC | 0.841 ± .011 | 0.752 ± .006 | 0.635 ± .015 | 0.820 ± .030 | 0.793 ± .019 |
| EEGNet | ✗ | AUPRC | 0.832 ± .011 | 0.433 ± .025 | 0.351 ± .006 | 0.470 ± .017 | 0.499 ± .044 |
| TCN | ✗ | AUROC | 0.841 ± .004 | 0.687 ± .011 | 0.545 ± .009 | 0.817 ± .004 | 0.731 ± .020 |
| TCN | ✗ | AUPRC | 0.831 ± .002 | 0.408 ± .009 | 0.344 ± .001 | 0.383 ± .010 | 0.398 ± .025 |
| EEG-GNN | ✗ | AUROC | 0.840 ± .005 | 0.837 ± .022 | 0.721 ± .009 | 0.780 ± .006 | 0.760 ± .010 |
| EEG-GNN | ✗ | AUPRC | 0.832 ± .004 | 0.488 ± .015 | 0.381 ± .004 | 0.388 ± .023 | 0.419 ± .021 |
| GraphS4mer | ✗ | AUROC | 0.864 ± .006 | 0.833 ± .006 | 0.632 ± .017 | 0.822 ± .034 | 0.719 ± .007 |
| GraphS4mer | ✗ | AUPRC | 0.862 ± .008 | 0.461 ± .024 | 0.359 ± .001 | 0.491 ± .001 | 0.374 ± .013 |
| BrainBERT | ✓ | AUROC | 0.853 ± .002 | 0.753 ± .012 | 0.588 ± .013 | 0.814 ± .009 | 0.734 ± .019 |
| BrainBERT | ✓ | AUPRC | 0.846 ± .003 | 0.350 ± .014 | 0.352 ± .003 | 0.386 ± .018 | 0.398 ± .027 |
| EEGFormer s | ✓ | AUROC | 0.862 ± .007 | 0.847 ± .013 | 0.683 ± .018 | 0.875 ± .004 | 0.842 ± .008 |
| EEGFormer s | ✓ | AUPRC | 0.862 ± .005 | 0.488 ± .012 | 0.397 ± .011 | 0.553 ± .014 | 0.578 ± .023 |
| EEGFormer b | ✓ | AUROC | 0.865 ± .001 | 0.847 ± .014 | 0.713 ± .010 | 0.878 ± .006 | 0.842 ± .014 |
| EEGFormer b | ✓ | AUPRC | 0.867 ± .002 | 0.483 ± .026 | 0.393 ± .003 | 0.560 ± .010 | 0.568 ± .036 |
| EEGFormer l | ✓ | AUROC | 0.876 ± .003 | 0.852 ± .004 | 0.679 ± .013 | 0.883 ± .005 | 0.833 ± .017 |
| EEGFormer l | ✓ | AUPRC | 0.872 ± .001 | 0.483 ± .014 | 0.389 ± .003 | 0.556 ± .008 | 0.544 ± .026 |
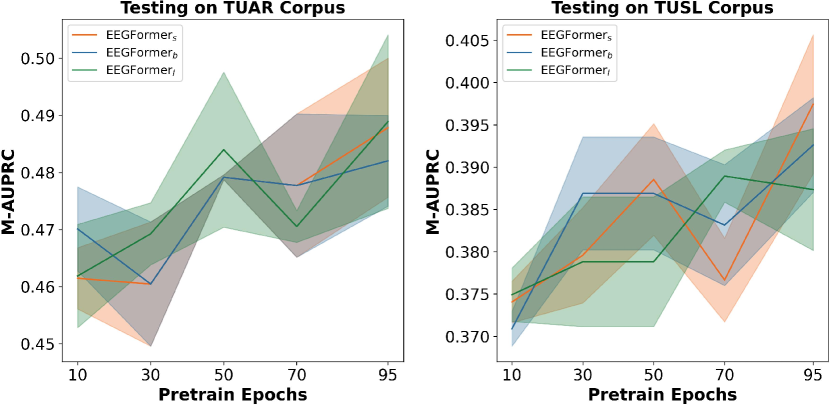
- EEGFormer 변형들이 AUROC와 AUPRC 지표에서 TUH 다운스트림 태스크의 여러 베이스라인을 능가한다.
- 사전 학습 에포크 수가 다운스트림 성능에 긍정적으로 영향을 준다.
- 선형 탐색에서 EEGFormer는 이미 일부 감독 베이스라인에 필적하고, 엔드-투-엔드 미세조정이 최상의 결과를 낳는다.
- 이산 코드북은 해석 가능성을 가능하게 하며 학습된 인덱스에 대한 n-gram 분석은 미세조정 없이도 발작 패턴을 국소화할 수 있다.
- Neonate 및 TUSZ 데이터셋에서 EEGFormer가 베이스라인에 비해 AUPRC와 AUROC에서 상당한 이점을 달성한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.