[논문 리뷰] FedMKT: Federated Mutual Knowledge Transfer for Large and Small Language Models
FedMKT는 서버 측 LLM과 다수의 클라이언트 측 SLM들 간의 연합된 상호 지식 이전 프레임워크를 제안하며, 토큰 정렬(token alignment)과 선택적 증류를 통해 서버와 클라이언트 모델을 함께 향상시킨다.
Recent research in federated large language models (LLMs) has primarily focused on enabling clients to fine-tune their locally deployed homogeneous LLMs collaboratively or on transferring knowledge from server-based LLMs to small language models (SLMs) at downstream clients. However, a significant gap remains in the simultaneous mutual enhancement of both the server's LLM and clients' SLMs. To bridge this gap, we propose FedMKT, a parameter-efficient federated mutual knowledge transfer framework for large and small language models. This framework is designed to adaptively transfer knowledge from the server's LLM to clients' SLMs while concurrently enriching the LLM with clients' unique domain insights. We facilitate token alignment using minimum edit distance (MinED) and then selective mutual knowledge transfer between client-side SLMs and a server-side LLM, aiming to collectively enhance their performance. Through extensive experiments across three distinct scenarios, we evaluate the effectiveness of FedMKT using various public LLMs and SLMs on a range of NLP text generation tasks. Empirical results demonstrate that FedMKT simultaneously boosts the performance of both LLMs and SLMs.
연구 동기 및 목표
- 서버 측 LLM과 클라이언트 측 SLM 간의 간극을 메우기 위해 상호 지식 이전을 가능하게 한다.
- 통신 및 연산 비용을 줄이기 위해 LoRA 어댑터를 활용한 매개변수 효율적인 방법을 개발한다.
- 토큰 정렬과 선택적 지식 이전으로 모델 이질성을 해결하여 양측의 성능 향상을 보장한다.
- 공개 LLM/SLM을 사용한 다양한 NLP 태스크에서 이질적, 동형적, 일대일 설정에 걸쳐 FedMKT를 평가한다.
제안 방법
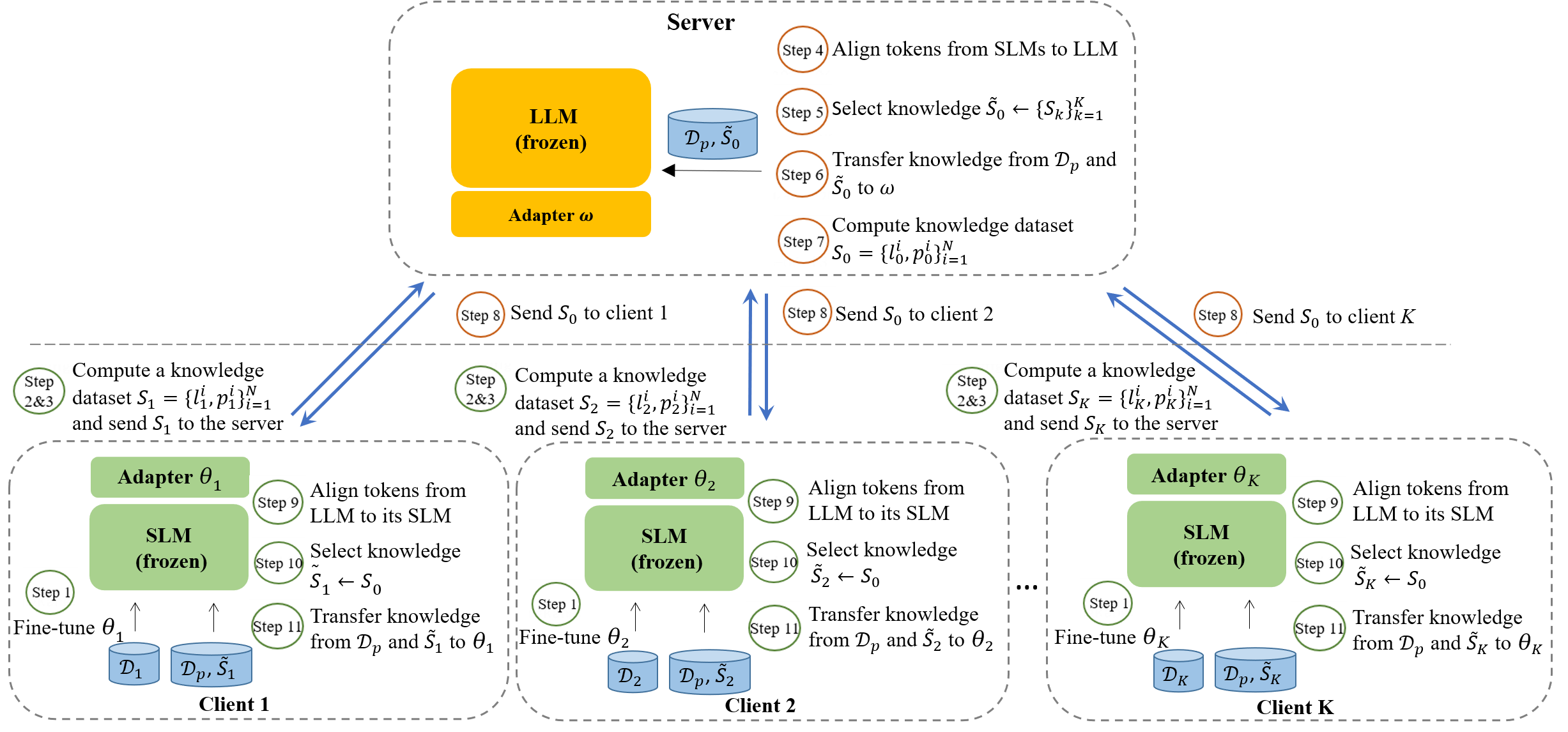
- 두 가지 핵심 모듈: 양방향 토큰 정렬(Bidirectional Token Alignment)과 선택적 상호 지식 이전(Selective Mutual Knowledge Transfer).
- LLM과 SLM 어휘 간의 로짓을 정렬하기 위해 최소 편집 거리(MinED) 기반의 토큰 매핑을 사용한다.
- 서버(omega)와 클라이언트(theta) 모두에 대해 LoRA 어댑터를 사용하여 매개변수 효율적인 업데이트를 가능하게 한다.
- 중앙집중식 공개 데이터셋 기반의 이중 증류 목표(DualMinCE)로 상호 전이를 위한 양의 지식을 선택한다.
- 교대 학습: 클라이언트가 사적 데이터로 로컬 미세조정을 수행한 후 공개 데이터에서 로짓을 교환한다; 서버는 클라이언트 로짓에서 증류하고 이를 클라이언트에 재분배한다.
- 목적 용어 L2와 L3는 미세조정 손실과 증류 손실을 균형 매개변수 lambda와 함께 결합한다.
실험 결과
연구 질문
- RQ1연합 학습 환경에서 서버 LLM과 이질적인 클라이언트 SLM 간의 효과적인 상호 지식 이전을 어떻게 가능하게 할 수 있을까?
- RQ2로짓 기반 지식 이전 중에 MinED를 통한 토큰 정렬이 토크나이저의 이질성을 완화할 수 있을까?
- RQ3선택적 상호 지식 이전이 이질적, 동형적 및 일대일 설정에서 기준 및 other baselines에 비해 서버 LLM과 클라이언트 SLM 모두의 성능을 향상시키는가?
주요 결과
- FedMKT는 이질적 설정에서 여덟 개의 태스크에 걸쳐 클라이언트 SLM에 대해 제로샷 및 독립 베이스라인을 일관되게 능가한다.
- FedMKT가 적용된 서버 LLM은 여러 태스크에서 중앙집중형 파인튜닝 성능에 근접하며, 한 시나리오에서 RTE에서 중앙집중 성능의 약 96%에 도달했다.
- 동형 설정에서 FedMKT은 제로샷에 비해 서버 LLM의 이득이 우수하고 중앙집중 대비 경쟁력 있는 결과를 보이며, 동시에 SLM도 향상시킨다.
- 일대일 설정에서 FedMKT은 서버 LLM의 제로샷을 능가하고 중앙집중 성능에 필적하며, LLM의 가이드로 SLM 성능을 향상시킨다.
- 실험은 여러 모델 페어(서버 LLM과 다양한 클라이언트 SLM)와 세 가지 설정을 다루며 프레임워크의 일반성을 입증한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.