[논문 리뷰] FETV: A Benchmark for Fine-Grained Evaluation of Open-Domain Text-to-Video Generation
FETV는 오픈 도메인 텍스트-투-비디오 생성에 대한 세밀한 다면적 및 시계열 인식 벤치마크를 도입하고 자동 메트릭의 신뢰성을 인간 판단과 대조 분석하며, UMT를 기반으로 향상된 메트릭을 제안합니다.
Recently, open-domain text-to-video (T2V) generation models have made remarkable progress. However, the promising results are mainly shown by the qualitative cases of generated videos, while the quantitative evaluation of T2V models still faces two critical problems. Firstly, existing studies lack fine-grained evaluation of T2V models on different categories of text prompts. Although some benchmarks have categorized the prompts, their categorization either only focuses on a single aspect or fails to consider the temporal information in video generation. Secondly, it is unclear whether the automatic evaluation metrics are consistent with human standards. To address these problems, we propose FETV, a benchmark for Fine-grained Evaluation of Text-to-Video generation. FETV is multi-aspect, categorizing the prompts based on three orthogonal aspects: the major content, the attributes to control and the prompt complexity. FETV is also temporal-aware, which introduces several temporal categories tailored for video generation. Based on FETV, we conduct comprehensive manual evaluations of four representative T2V models, revealing their pros and cons on different categories of prompts from different aspects. We also extend FETV as a testbed to evaluate the reliability of automatic T2V metrics. The multi-aspect categorization of FETV enables fine-grained analysis of the metrics' reliability in different scenarios. We find that existing automatic metrics (e.g., CLIPScore and FVD) correlate poorly with human evaluation. To address this problem, we explore several solutions to improve CLIPScore and FVD, and develop two automatic metrics that exhibit significant higher correlation with humans than existing metrics. Benchmark page: https://github.com/llyx97/FETV.
연구 동기 및 목표
- 다양한 프롬프트 카테고리에 걸쳐 오픈 도메인 T2V 모델에 대한 세밀한 평가 프레임워크를 제공합니다.
- T2V 생성에서 영상 특유의 도전을 포착하기 위해 시간적 인식을 도입합니다.
- 기존 자동 평가 메트릭의 신뢰성을 인간 판단과 비교해 평가합니다.
- 고급 비전-언어 모델을 사용한 인간 평가와 일치하는 향상된 자동 메트릭을 제안합니다.
제안 방법
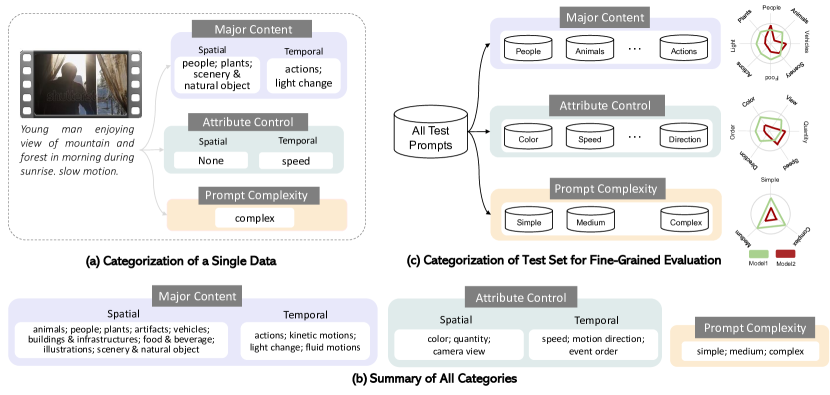
- 주요 내용별로 분류된 프롬프트(내용, 속성 제어, 프롬프트 복잡성)와 영상 생성을 위한 시간적 범주를 포함한 FETV 벤치마크를 제안합니다.
- MSR-VTT, WebVid에서 619개의 분류된 프롬프트를 수집하고 수동으로 작성된 비정상 프롬프트를 적용한 후 범주에 대해 자동 레이블링을 한 뒤 수동 레이블링을 수행합니다.
- 4개의 오픈 T2V 모델을 네 가지 관점(정적 품질, 시간적 품질, 전반적 정렬, 세밀한 정렬)으로 각 비디오당 3명의 인간 채점자와 함께 평가합니다.
실험 결과
연구 질문
- RQ1오픈 도메인 T2V 모델이 콘텐츠의 세부 범주, 속성, 복잡성에 따라 어떻게 수행되는가?
- RQ2시간적 콘텐츠가 영상 품질과 프롬프트에 대한 정합성에 어떤 영향을 미치는가?
- RQ3자동 T2V 메트릭은 인간 판단과 얼마나 상관관계가 있으며 이를 개선할 수 있는가?
- RQ4고급 비전-언어 모델을 기반으로 한 새로운 메트릭이 카테고리 전반에 걸쳐 인간 평가와 더 잘 일치하는가?
- RQ5다양한 프롈프트 하에서 대표적인 오픈 T2V 모델의 강점과 약점은 무엇인가?
주요 결과
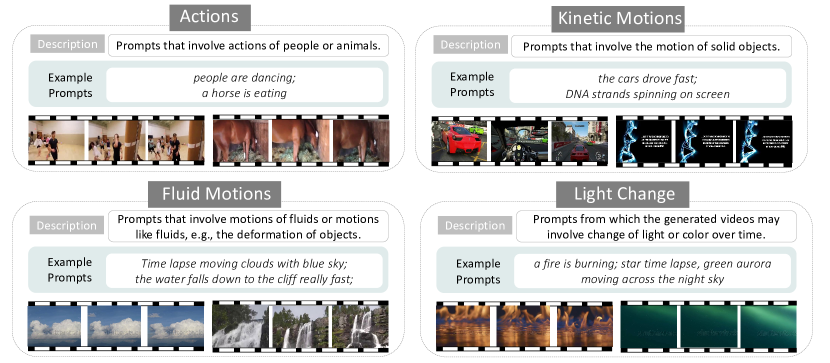
- 동작/운동의 움직임이 있을 때와 공간적 콘텐츠에서 사람이나 동물이 등장하는 경우 영상 품질이 더 저하된다.
- 모델의 수량 제어, 운동 방향, 사건 순서에 대한 능력이 다르며 현 모델은 이러한 속성에서 어려움을 겪는다.
- 자동 메트릭 CLIPScore와 FVD는 인간 평가와의 상관관계가 낮은 반면, UMTScore와 FVD-UMT는 인간과의 상관관계가 더 높다.
- 미세 조정되거나 고급 VLM 기반 메트릭(UMTScore, FVD-UMT)은 전통적 메트릭보다 인간 랭킹과 더 잘 정렬된다.
- 수동 평가를 통해 CogVideo, Text2Video-zero, ModelScopeT2V, ZeroScope의 카테고리별 실제 장단점이 드러난다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.