[논문 리뷰] Foundational Models Defining a New Era in Vision: A Survey and Outlook
비전-언어 기초 모델에 대한 포괄적 고찰로, 아키텍처, 학습 목표, 데이터, 미세 조정, 프롬프트 설계 및 도전 과제를 자세히 설명하고 향후 방향을 제시한다.
Vision systems to see and reason about the compositional nature of visual scenes are fundamental to understanding our world. The complex relations between objects and their locations, ambiguities, and variations in the real-world environment can be better described in human language, naturally governed by grammatical rules and other modalities such as audio and depth. The models learned to bridge the gap between such modalities coupled with large-scale training data facilitate contextual reasoning, generalization, and prompt capabilities at test time. These models are referred to as foundational models. The output of such models can be modified through human-provided prompts without retraining, e.g., segmenting a particular object by providing a bounding box, having interactive dialogues by asking questions about an image or video scene or manipulating the robot's behavior through language instructions. In this survey, we provide a comprehensive review of such emerging foundational models, including typical architecture designs to combine different modalities (vision, text, audio, etc), training objectives (contrastive, generative), pre-training datasets, fine-tuning mechanisms, and the common prompting patterns; textual, visual, and heterogeneous. We discuss the open challenges and research directions for foundational models in computer vision, including difficulties in their evaluations and benchmarking, gaps in their real-world understanding, limitations of their contextual understanding, biases, vulnerability to adversarial attacks, and interpretability issues. We review recent developments in this field, covering a wide range of applications of foundation models systematically and comprehensively. A comprehensive list of foundational models studied in this work is available at \url{https://github.com/awaisrauf/Awesome-CV-Foundational-Models}.
연구 동기 및 목표
- 비전의 기초 모델을 정의하고 다중모달 이해를 위한 그 중요성을 설명한다.
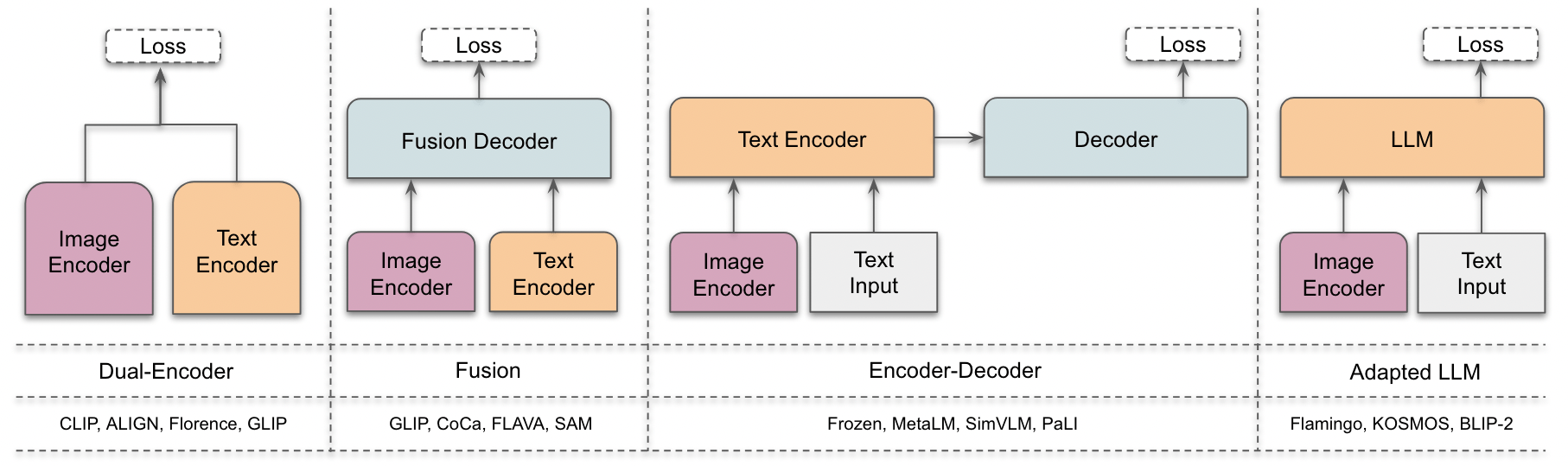
- 아키텍처 패밀리(dual-encoder, fusion, encoder-decoder, adapted-LLM)와 학습 목표(contrastive, generative, hybrid)를 조사한다.
- 비전-언어 모델의 사전 학습 데이터 유형, 미세조정 전략, 프롬프트 엔지니어링을 분석한다.
- 평가, 편향성, 로버스트니스, 해석 가능성과 같은 열린 과제를 논의하고 향후 연구 방향을 제시한다.
제안 방법
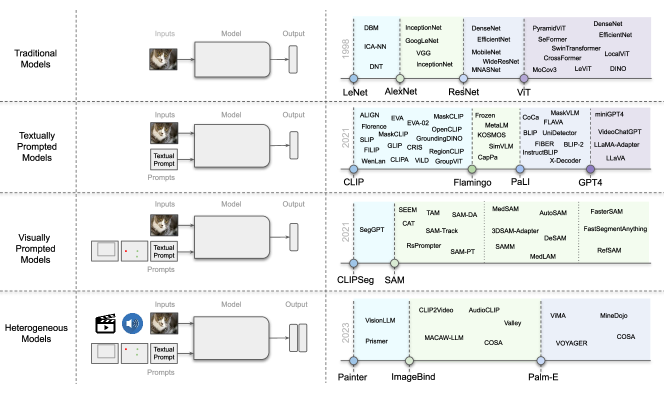
- 텍스트로 프롬프트된, 이미지로 프롬프트된, 이질적 모달리티 및 구현 차원의 카테고리를 아우르는 기초 비전 모델에 대한 체계적 고찰.
- 아키텍처를 dual-encoder, fusion, encoder-decoder, 및 adapted-LLM 디자인으로 분류하고 예시 모델을 제시한다.
- 대조적(contrastive), 생성적(generative), 하이브리드 손실을 포함한 학습 목표의 합성을 대표적 형태(예: ITC, MLM, LM)와 함께 제시한다.
- 대규모 사전 학습 데이터 소스(이미지-텍스트 데이터 세트, 부분적으로 합성 데이터, 그리고 조합) 및 프롬프트/미세 조정 패러다임에 대한 개요를 제공한다.
- 평가 도전과제, 편향, 적대적 취약성, 해석 가능성 이슈에 대한 논의를 포함한다.
- 커뮤니티 자원(GitHub)에서 최신의 기초 모델 목록을 정리한다.
실험 결과
연구 질문
- RQ1비전-언어 기초 모델이 사용하는 아키텍처 패턴은 무엇이며 프롬프트와 모달리티에 따라 어떻게 다른가?
- RQ2학습 목표와 데이터 유형이 비전-언어 모델의 일반화 및 다운스트림 태스크 성능에 어떤 영향을 미치는가?
- RQ3하류 비전 태스크에 기초 모델을 적응시키기 위한 일반적인 미세 조정 및 프롬프트 전략은 무엇인가?
- RQ4컴퓨터 비전에 대한 기초 모델의 주요 평가 도전과 열린 연구 방향은 무엇인가?
- RQ5현재의 기초 모델이 다중 모달 환경에서 편향, 강건성, 해석 가능성을 어떻게 다루는가?
주요 결과
- 기초 모델은 재학습 없이 프롬프트를 통해 광범위한 비전 태스크에 제로샷 및 퓨샷 이전을 가능하게 한다.
- 텍스트로 프롬프트된 모델은 대조적(contrastive), 생성적(generative), 하이브리드(hybrid) 접근으로 분류되며, CLIP 유사한 아키텍처가 기초적이다.
- 대규모 이미지-텍스트 데이터와 다양화된 사전 학습 목표가 모델 일반화 및 다운스트림 성능에 크게 영향을 준다.
- 프롬프트 엔지니어링 및 미세 조정 전략(지시 따르기, 근거 제시, 태스크 특화 적응)이 이러한 모델을 활용하는 데 필수적이다.
- 개방형 도전과제에는 평가의 어려움, 실제 세계 이해의 격차, 편향, 적대적 취약성 및 해석 가능성 우려가 포함된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.