[논문 리뷰] Frontier AI Regulation: Managing Emerging Risks to Public Safety
논문은 위험하고 새롭게 나타날 수 있는 능력을 가진 프런티어 AI 모델에 대한 적극적 거버넌스를 촉진한다.
Advanced AI models hold the promise of tremendous benefits for humanity, but society needs to proactively manage the accompanying risks. In this paper, we focus on what we term "frontier AI" models: highly capable foundation models that could possess dangerous capabilities sufficient to pose severe risks to public safety. Frontier AI models pose a distinct regulatory challenge: dangerous capabilities can arise unexpectedly; it is difficult to robustly prevent a deployed model from being misused; and, it is difficult to stop a model's capabilities from proliferating broadly. To address these challenges, at least three building blocks for the regulation of frontier models are needed: (1) standard-setting processes to identify appropriate requirements for frontier AI developers, (2) registration and reporting requirements to provide regulators with visibility into frontier AI development processes, and (3) mechanisms to ensure compliance with safety standards for the development and deployment of frontier AI models. Industry self-regulation is an important first step. However, wider societal discussions and government intervention will be needed to create standards and to ensure compliance with them. We consider several options to this end, including granting enforcement powers to supervisory authorities and licensure regimes for frontier AI models. Finally, we propose an initial set of safety standards. These include conducting pre-deployment risk assessments; external scrutiny of model behavior; using risk assessments to inform deployment decisions; and monitoring and responding to new information about model capabilities and uses post-deployment. We hope this discussion contributes to the broader conversation on how to balance public safety risks and innovation benefits from advances at the frontier of AI development.
연구 동기 및 목표
- 위험하고 새롭게 나타날 수 있는 능력을 가진 프런티어 AI 모델에 대한 선제적 거버넌스를 촉진한다.
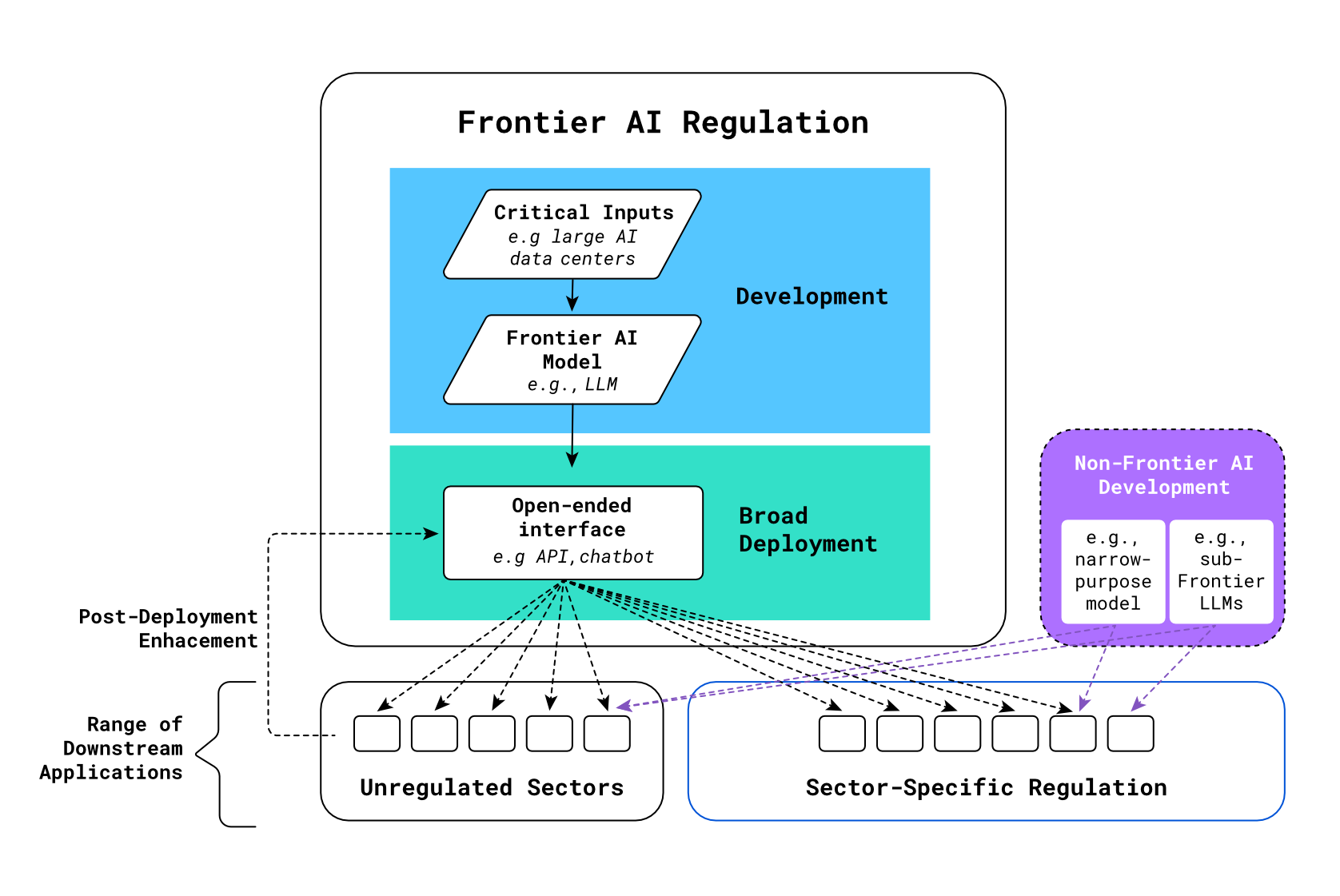
- 세 가지 핵심 규제 도전과제를 식별한다: 예기치 않은 능력, 배치 안전성, 그리고 빠른 확산.
- 안전 표준 개발, 규제 가시성, 그리고 준수 메커니즘으로 구성된 삼자 규제 프레임워크를 제안한다.
- 다중 이해관계자 프로세스와 잠재적 정부 개입을 통해 혁신과 안전의 균형을 조언한다.
제안 방법
- 프런티어 AI 모델을 잠재적으로 위험한 능력을 가진 고도로 능력 있는 기초 모델로 정의한다.
- 세 가지 규제 도전과제를 개요한다: 예기치 않은 능력, 배치 안전성, 그리고 확산.
- 구축 요소를 제안한다: 안전 표준의 제도화, 규제 가시성의 제고, 준수 보장(자율규제, 집행, 면허 부여).
- 초기 안전 표준의 집합을 제안한다: 위험 평가, 외부 심사, 위험에 기반한 배치 프로토콜, 배포 후 모니터링.
실험 결과
연구 질문
- RQ1위험한 능력을 가진 프런티어 AI 모델을 다스리기 위해 어떤 규제 전략이 필요한가?
- RQ2빠르게 움직이는 프런티어 AI 맥락에서 안전 표준은 어떻게 개발되고 업데이트될 수 있는가?
- RQ3규제 당국이 프런티어 AI 개발 및 배치에 대한 가시성을 확보할 수 있는 메커니즘은 무엇인가?
- RQ4프런티어 AI에 적합한 준수 접근 방식(자율규제, 감독, 면허)은 무엇인가?
주요 결과
- 자체 규제만으로는 프런티어 AI 리스크를 충분히 관리할 수 없으며, 정부 개입이 필요할 가능성이 높다.
- 안전 표준 개발, 개발 과정에 대한 가시성, 그리고 시행/준수 메커니즘의 삼중 규제가 제안된다.
- 위험 평가, 외부 심사, 위험에 기반한 배치 프로토콜, 배포 후 모니터링을 포함한 초기 안전 표준이 제시된다.
- 규제는 공공 안전을 보호하는 동시에 혁신을 저해하지 않도록 균형을 유지하고, 급속한 AI 진전에 적응할 수 있어야 한다.
- 프런티어 AI 규제는 AI 리스크와 이점을 다루는 보다 포괄적인 정책 포트폴리오의 일부가 되어야 한다.
![Figure 2: Certain capabilities seem to emerge suddenly 22 22 22 Chart from [ 63 ] . But see [ 67 ] for a skeptical view on emergence. For a response to the skeptical view, see [ 66 ] and Appendix B.](https://ar5iv.labs.arxiv.org/html/2307.03718/assets/emerge.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.