[논문 리뷰] GPTs are GPTs: An Early Look at the Labor Market Impact Potential of Large Language Models
이 논문은 O*NET 작업 데이터에 적용된 새로운 노출 루브릭을 인간과 GPT-4 분류와 함께 사용하여 LLM이 미국의 작업 작업(Task)과 직업에 어떤 영향을 미칠 수 있는지 추정합니다. LLM 기반 소프트웨어를 사용할 때 널리 퍼진 노출과 상당한 이득을 발견합니다.
We investigate the potential implications of large language models (LLMs), such as Generative Pre-trained Transformers (GPTs), on the U.S. labor market, focusing on the increased capabilities arising from LLM-powered software compared to LLMs on their own. Using a new rubric, we assess occupations based on their alignment with LLM capabilities, integrating both human expertise and GPT-4 classifications. Our findings reveal that around 80% of the U.S. workforce could have at least 10% of their work tasks affected by the introduction of LLMs, while approximately 19% of workers may see at least 50% of their tasks impacted. We do not make predictions about the development or adoption timeline of such LLMs. The projected effects span all wage levels, with higher-income jobs potentially facing greater exposure to LLM capabilities and LLM-powered software. Significantly, these impacts are not restricted to industries with higher recent productivity growth. Our analysis suggests that, with access to an LLM, about 15% of all worker tasks in the US could be completed significantly faster at the same level of quality. When incorporating software and tooling built on top of LLMs, this share increases to between 47 and 56% of all tasks. This finding implies that LLM-powered software will have a substantial effect on scaling the economic impacts of the underlying models. We conclude that LLMs such as GPTs exhibit traits of general-purpose technologies, indicating that they could have considerable economic, social, and policy implications.
연구 동기 및 목표
- LLMs(GPTs)가 모델 능력 자체를 넘어서 노동시장에 어떠한 영향을 미칠 수 있는지 이해를 자극합니다.
- 인간 및 GPT-4 분류를 사용하여 LLM에 의한 작업 노출을 측정하기 위한 루브릭을 개발하고 적용합니다.
- 작업 수준의 노출을 직업 및 산업 수준의 통찰로 집계합니다.
- 보완 기술과 LLM 기반 소프트웨어가 경제적 영향의 규모화에 기여하는 역할을 강조합니다.
제안 방법
- O*NET DWA와 작업(19,265개 작업; 2,087개 DWA)을 사용하여 작업-및 직업 수준의 노출 측정치를 구성합니다.
- 50% 시간 절감 루브릭 하에서 인간 판단 및 GPT-4 분류로 노출을 주석합니다.
- 노출 측정치를 세 가지 정의합니다: alpha (E1), beta (E1 + 0.5*E2), and zeta (E1 + E2).
- 핵심 작업은 보조 작업에 비해 이중 가중치를 두고 작업 노출을 직업으로 집계합니다.
- 인간 주석과 GPT-4 분류를 비교하고 직업 수준 전체에서 동의도와 상관관계를 평가합니다.
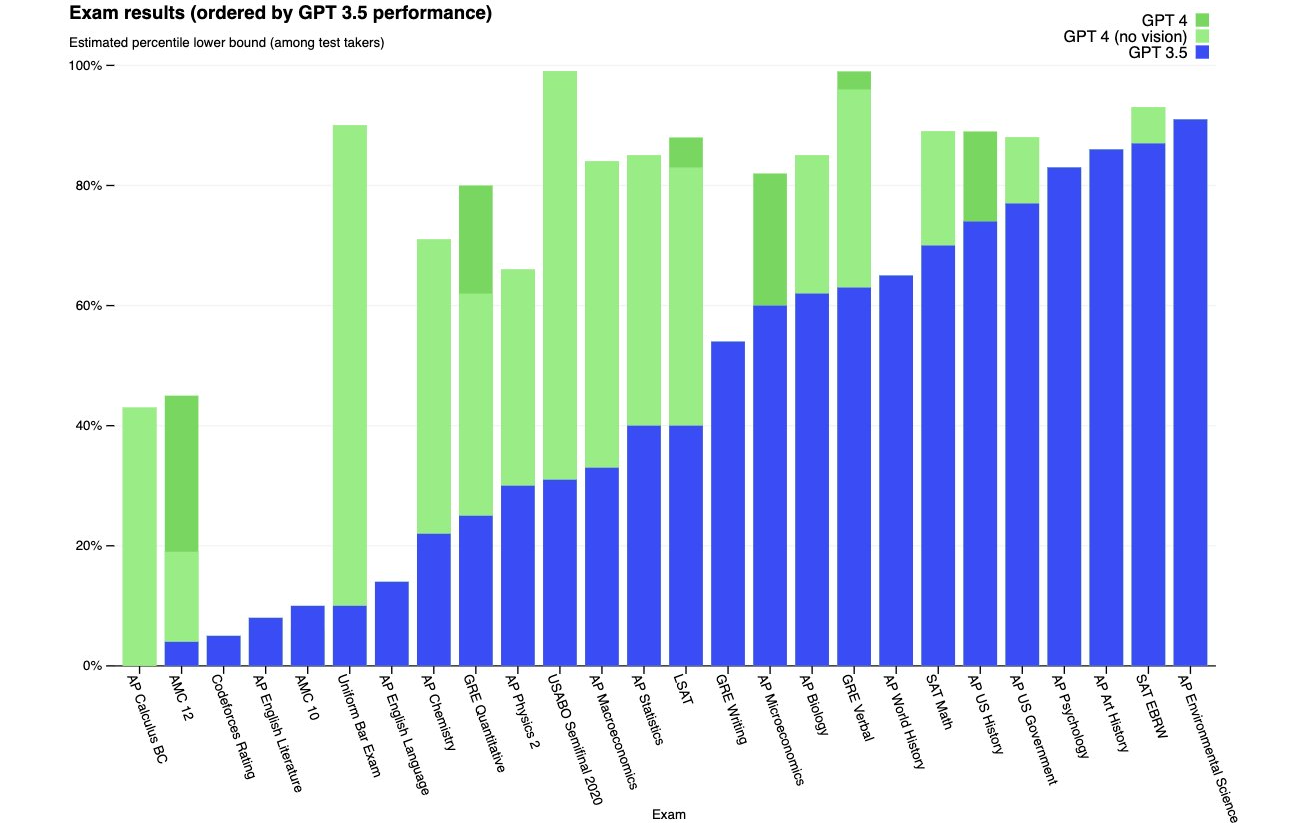
실험 결과
연구 질문
- RQ1미국의 직업 중 어느 비율이 작업 수준에서 LLM에 노출되어 있습니까?
- RQ2노출 추정치가 인간 평가자와 GPT-4 분류 간에 어떻게 다릅니까?
- RQ3LLMs만의 영향과 LLM 기반 소프트웨어의 영향이 작업 완료 시간에 미치는 차이는 무엇입니까?
- RQ4노출 패턴은 직업, 임금 수준, 산업에 따라 어떻게 달라집니까?
주요 결과
- 약 80%의 노동자가 직업 중 최소 10%의 작업이 LLM에 노출된다고 하는 직업에 속합니다(베타 측정치).
- 약 19%의 노동자가 직업 중 최소 50%의 작업이 LLM에 노출된다고 하는 직업에 속합니다(베타 측정치).
- 평균적으로 모든 노동자 작업 중 약 15%가 LLM만으로도 상당히 더 빠르게 완료될 수 있습니다; LLM 기반 소프트웨어를 사용하면 이 수치가 47–56%로 증가합니다.
- 직업 수준의 평균 alpha 값은 대략 0.14–0.15; beta는 인간 기준 약 0.30, GPT-4 기준 0.34; zeta는 더 높아 직업 전반에서 상당한 노출 가능성을 시사합니다.
- 노출은 고임금 직업 및 정보처리 산업에서 더 높은 경향이 있으며, 노출은 프로그래밍 및 작문 기술과 양의 상관, 과학/비판적 사고 기술과는 음의 상관이 있습니다.
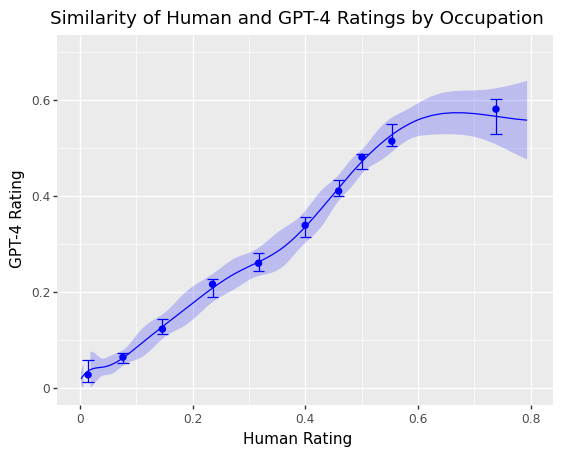
- LLM 시스템에 대한 노출과 관련하여 직업 수준에서 인간과 GPT-4 주석 간에 상당한 일치가 있습니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.