[논문 리뷰] HuatuoGPT, towards Taming Language Model to Be a Doctor
HuatuoGPT는 ChatGPT에서 증류된 데이터와 실제 의사 데이터를 결합하고 AI 피드백으로부터의 RL을 사용하여 중국어 의학 LLM을 만들어 공개 소스 경쟁자들을 능가하고 의료 상담에서 종종 ChatGPT를 상회합니다.
In this paper, we present HuatuoGPT, a large language model (LLM) for medical consultation. The core recipe of HuatuoGPT is to leverage both extit{distilled data from ChatGPT} and extit{real-world data from doctors} in the supervised fine-tuned stage. The responses of ChatGPT are usually detailed, well-presented and informative while it cannot perform like a doctor in many aspects, e.g. for integrative diagnosis. We argue that real-world data from doctors would be complementary to distilled data in the sense the former could tame a distilled language model to perform like doctors. To better leverage the strengths of both data, we train a reward model to align the language model with the merits that both data bring, following an RLAIF (reinforced learning from AI feedback) fashion. To evaluate and benchmark the models, we propose a comprehensive evaluation scheme (including automatic and manual metrics). Experimental results demonstrate that HuatuoGPT achieves state-of-the-art results in performing medical consultation among open-source LLMs in GPT-4 evaluation, human evaluation, and medical benchmark datasets. It is worth noting that by using additional real-world data and RLAIF, the distilled language model (i.e., HuatuoGPT) outperforms its teacher model ChatGPT in most cases. Our code, data, and models are publicly available at \url{https://github.com/FreedomIntelligence/HuatuoGPT}. The online demo is available at \url{https://www.HuatuoGPT.cn/}.
연구 동기 및 목표
- 전 세계 의료 접근 격차를 줄이기 위해 오픈소스, 개인 배포 의료 LLM을 촉진한다.
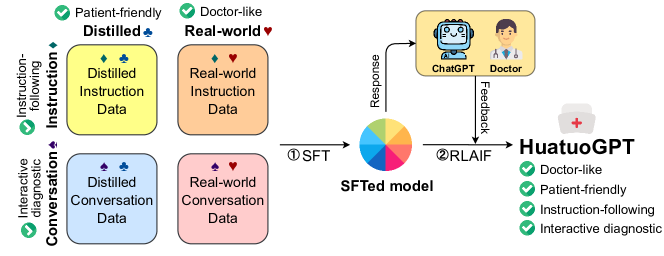
- 증류된 ChatGPT 데이터와 실제 의사의 데이터를 혼합하는 두 단계 학습 파이프라인을 제안한다.
- 출력물을 지시 이행과 의사와 같은 추론 사이에 정렬하기 위해 RL from AI Feedback (RLAIF)을 도입한다.
- 다양한 의료 데이터셋에서 자동 및 인간 평가를 결합한 포괄적 평가 체계를 구축한다.
제안 방법
- Hybrid data SFT: 지시 데이터와 실제 의사 대화를 통해 의사 같은 행동과 환자 친화적 행동을 구현한다.
- Distilled data incorporation: ChatGPT가 생성한 의료 지시 및 대화를 활용하여 지시 이행과 유창성을 개선한다.
- Reward model: 정보성, 일관성, 사실 정확성을 포착하기 위해 대형 언어 모델의 점수로 보상 모델을 훈련한다.
- Reinforcement learning from AI feedback (RLAIF): KL-penalized 정책 업데이트로 모델을 최적화하여 ChatGPT와 의사 자격 모두에 정렬한다.
- Base model and setup: BLOOMZ-7b1-mt 백본; 8개의 A100 GPU로 다단계 학습, 특정 LR/배치/맥락 설정, 일반 대화 능력을 위한 추가 중국어 데이터 포함
실험 결과
연구 질문
- RQ1실제 의사 데이터와 증류된 ChatGPT 데이터를 결합하면 의사 같은 진단 및 환자 대상 의사소통이 향상되는가?
- RQ2RLAIF가 순수 SFT보다 의료 LLM 출력의 전문 진단 품질과 환자 안전에 더 잘 정렬되는가?
- RQ3HuatuoGPT가 중국어 의료 벤치마크 및 GPT-4 평가 단일 턴 및 다중 턴 시나리오에서 기저 모델과 비교해 어떤 성능을 보이는가?
- RQ4실제 데이터로 보완될 때 HuatuoGPT가 많은 의료 상담 작업에서 교사 모델인 ChatGPT를 능가할 수 있는가?
주요 결과
| Dataset(데이터셋) | Model(모델) | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | GLEU | ROUGE-1 | ROUGE-2 | ROUGE-L | Distinct-1 | Distinct-2 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| cMedQA2 | HuatuoGPT | 25.37 | 13.16 | 7.39 | 4.25 | 8.30 | 27.75 | 7.31 | 17.36 | 0.74 | 0.93 |
| webMedQA | HuatuoGPT | 24.61 | 12.84 | 7.23 | 4.19 | 7.73 | 27.38 | 7.09 | 17.66 | 0.71 | 0.93 |
| Huatuo-26M | HuatuoGPT | 25.16 | 13.21 | 7.54 | 4.40 | 8.37 | 27.76 | 7.45 | 17.99 | 0.73 | 0.93 |
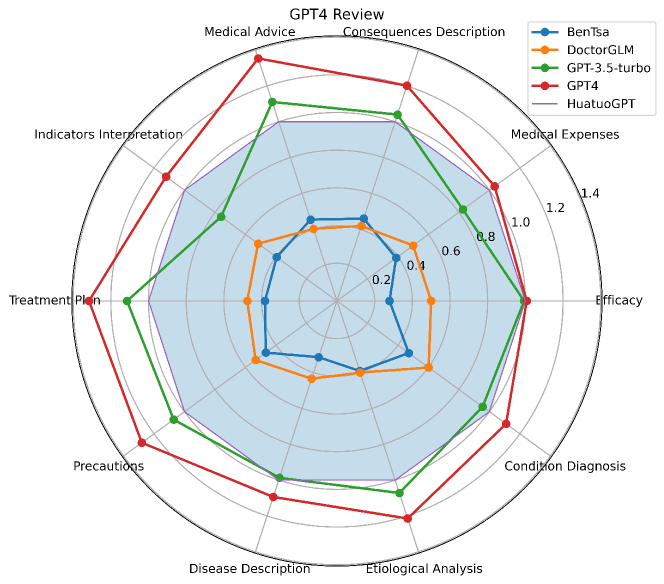
- HuatuoGPT는 중국어 의료 분야의 GPT-4, 인간 평가 및 의료 벤치마크에서 공개 소스 LLM 중 최첨단(results)을 달성한다.
- 실제 데이터와 RLAIF를 활용한 경우 HuatuoGPT가 교사 모델 ChatGPT를 능가하는 경우가 많다.
- HuatuoGPT는 cMedQA2, webMedQA, Huatuo-26M 벤치마크에서 SOTA 성능을 달성한다.
- 자동(GPT-4) 및 인간 평가 모두 HuatuoGPT의 의사 같은 정확도, 상호 작용적 질문 형성, 환자 친화적 응답을 확인한다.
- 모델은 단일 턴 및 다중 턴 평가에서 여러 부문에 대해 BenTsao, DoctorGLM, GPT-3.5-turbo를 지속적으로 능가한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.