[논문 리뷰] HuBERT: Self-Supervised Speech Representation Learning by Masked Prediction of Hidden Units
HuBERT는 마스크 처리된 음성 특징에서 K-means 군집화된 단위를 예측하는 자기지도 학습 방식의 음성 표현 학습 방법을 제안한다. 사전에 수행되는 클러스터링 단계를 통해 가짜 레이블을 생성하며, 예측 손실을 마스크된 영역에만 적용함으로써 강력한 음성 및 언어 표현을 학습한다. 1B 파라미터 모델을 사용하여 Librispeech dev-other에서 최대 19%의 WER 감소와 test-other에서 13%의 WER 감소를 달성하여 최신 기준 성능을 확보한다.
Self-supervised approaches for speech representation learning are challenged by three unique problems: (1) there are multiple sound units in each input utterance, (2) there is no lexicon of input sound units during the pre-training phase, and (3) sound units have variable lengths with no explicit segmentation. To deal with these three problems, we propose the Hidden-Unit BERT (HuBERT) approach for self-supervised speech representation learning, which utilizes an offline clustering step to provide aligned target labels for a BERT-like prediction loss. A key ingredient of our approach is applying the prediction loss over the masked regions only, which forces the model to learn a combined acoustic and language model over the continuous inputs. HuBERT relies primarily on the consistency of the unsupervised clustering step rather than the intrinsic quality of the assigned cluster labels. Starting with a simple k-means teacher of 100 clusters, and using two iterations of clustering, the HuBERT model either matches or improves upon the state-of-the-art wav2vec 2.0 performance on the Librispeech (960h) and Libri-light (60,000h) benchmarks with 10min, 1h, 10h, 100h, and 960h fine-tuning subsets. Using a 1B parameter model, HuBERT shows up to 19% and 13% relative WER reduction on the more challenging dev-other and test-other evaluation subsets.
연구 동기 및 목표
- 자기지도 학습 음성 표현 학습의 과제를 해결하기 위해: 다중 중첩 음성 단위, 사전 정의된 어휘 없음, 가변 길이의 단위.
- 사전 훈련 중 언어학적 태그에 의존하지 않고도 강력한 표현을 학습하는 방법을 개발하기 위해.
- 지속적인 음성 특징에 BERT 유사 마스크 예측 목표를 적용하여, 후속 ASR 작업의 일반화 및 성능을 향상시키기 위해.
- 클러스터링 품질, 하이퍼파라미터 및 앙상블 방법이 모델 성능에 미치는 영향을 조사하기 위해.
제안 방법
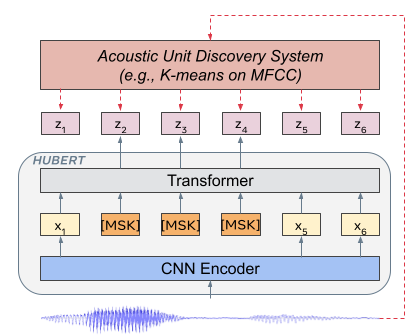
- MFCC 또는 HuBERT 특징에 대해 사전에 K-means 군집화를 적용하여 마스크된 예측을 위한 이산 타겟 단위를 생성한다.
- 모델은 마스크된 음성 프레임에 대한 군집 할당을 예측하기 위해 BERT 유사 트랜스포머 아키텍처를 사용하며, 손실은 마스크된 영역에서만 계산된다.
- 예측 작업은 마스크된 단위를 비마스크된 컨텍스트를 사용해 재구성함으로써 모델이 문맥 기반 표현을 학습하도록 강제한다.
- 이전 모델 반복의 잠재 표현을 사용하여 군집 할당을 반복적으로 개선함으로써 타겟 품질을 향상시킨다.
- 반복 과정에서 점차 정확도가 향상된 군집 타겟을 사용하는 다단계 훈련 과정을 통해 표현 품질을 향상시킨다.
- 일반화와 수렴 최적화를 위해 효과적 배치 크기와 마스크 확률을 조정한다.
실험 결과
연구 질문
- RQ1모든 또는 비마스크된 프레임을 예측하는 것과 비교해, 마스크된 프레임만 예측하는 것이 자기지도 학습 음성 표현 학습에 어떤 영향을 미치는가?
- RQ2클러스터링 품질이 모델 성능에 미치는 영향은 무엇이며, 특히 노이즈가 많거나 저품질의 군집 할당을 사용할 경우 어떻게 되는가?
- RQ3다양한 특징 유형이나 설정에서 훈련된 여러 K-means 모델의 앙상블을 사용할 경우 표현 품질에 어떤 영향을 미치는가?
- RQ4마스크 확률 및 배치 크기와 같은 하이퍼파라미터 중 HuBERT의 성능에 가장 크게 영향을 미치는 것은 무엇인가?
- RQ5군집 할당의 반복적 개선이 다양한 사전 훈련 데이터 스케일에서 일관된 성능 향상을 이끌 수 있는가?
주요 결과
- HuBERT는 모든 미세조정 서브셋(10분에서 960시간)에 대해 Librispeech(960시간) 및 Libri-light(60,000시간)에서 wav2vec 2.0의 최신 기준 성능을 matching하거나 초월한다.
- 1B 파라미터 모델을 사용하여, 더 도전적인 Librispeech dev-other 세트에서 19%의 상대적 WER 감소와 test-other에서 13%의 WER 감소를 달성한다.
- 마스크된 프레임만 예측하는 것이 모든 또는 비마스크된 프레임을 예측하는 것보다 유의미하게 성능이 뛰어나며, 특히 군집 품질이 낮을 경우 더욱 두드러진다.
- 장기간 훈련(최대 800,000 스텝)을 수행할수록 성능이 지속적으로 향상되며, 10시간 분량의 Libri-light 분할에서 최고의 WER 11.68%를 기록한다.
- 다양한 K-means 모델을 앙상블하는 것(예: 제품 양자화를 적용한 스플리스 MFCC에 대해)은 단일 클러스터링 설정보다 더 뛰어난 성능을 낳는다.
- 최적의 마스크 확률은 8%이며, 배치 크기를 늘리면 모델의 일반화 능력이 크게 향상된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.