[논문 리뷰] Human or Not? A Gamified Approach to the Turing Test
논문은 온라인 게임화된 튜링 테스트 스타일 실험을 한 달간 150만 명의 사용자와 실시하여 파트너 식별에서의 전체 정확도 68%, 파트너가 봇인 경우 60%의 정확도를 발견했다.
We present "Human or Not?", an online game inspired by the Turing test, that measures the capability of AI chatbots to mimic humans in dialog, and of humans to tell bots from other humans. Over the course of a month, the game was played by over 1.5 million users who engaged in anonymous two-minute chat sessions with either another human or an AI language model which was prompted to behave like humans. The task of the players was to correctly guess whether they spoke to a person or to an AI. This largest scale Turing-style test conducted to date revealed some interesting facts. For example, overall users guessed the identity of their partners correctly in only 68% of the games. In the subset of the games in which users faced an AI bot, users had even lower correct guess rates of 60% (that is, not much higher than chance). This white paper details the development, deployment, and results of this unique experiment. While this experiment calls for many extensions and refinements, these findings already begin to shed light on the inevitable near future which will commingle humans and AI.
연구 동기 및 목표
- 현대 AI 맥락에서 인간과 유사한 대화 versus 기계적 대화를 인간이 어떻게 인식하는지 탐구하여 연구의 동기를 부여한다.
- 대규모로 튜링 유사 테스트를 수행할 수 있는 확장 가능하고 몰입감 있는 플랫폼을 개발한다.
- 탐지에 도전하기 위해 다양한 페르소나를 갖춘 AI 봇을 설계하고 AI 식별에서 인간의 전략을 연구한다.
- 짧은 대화형 상호작용에서 인간성을 신호하고 AI를 탐지하기 위해 인간이 사용하는 전략을 포착하고 분석한다.
제안 방법
- 응답 창이 20초이고 대화 제한이 2분인 온라인 2분짜리 채팅 게임을 만든다.
- 고유한 페르소나와 백스토리, 영어 전용 제약을 가진 AI 봇에 프롬프트를 제공하고 백본 모델을 다양화한다 (예: Jurassic-2, GPT-4, Cohere).
- 봇 응답을 현실 시점의 맥락 관련 정보(날씨, 뉴스)로 구체화하여 뒷받침한다.
- 대화 시작점을 무작위로 설정하고 안전과 남용 방지를 위한 중재를 구현한다.
- 1000만 건이 넘는 추측을 150만 명 이상의 사용자로부터 수집해 통계적으로 강건한 점수를 도출한다.
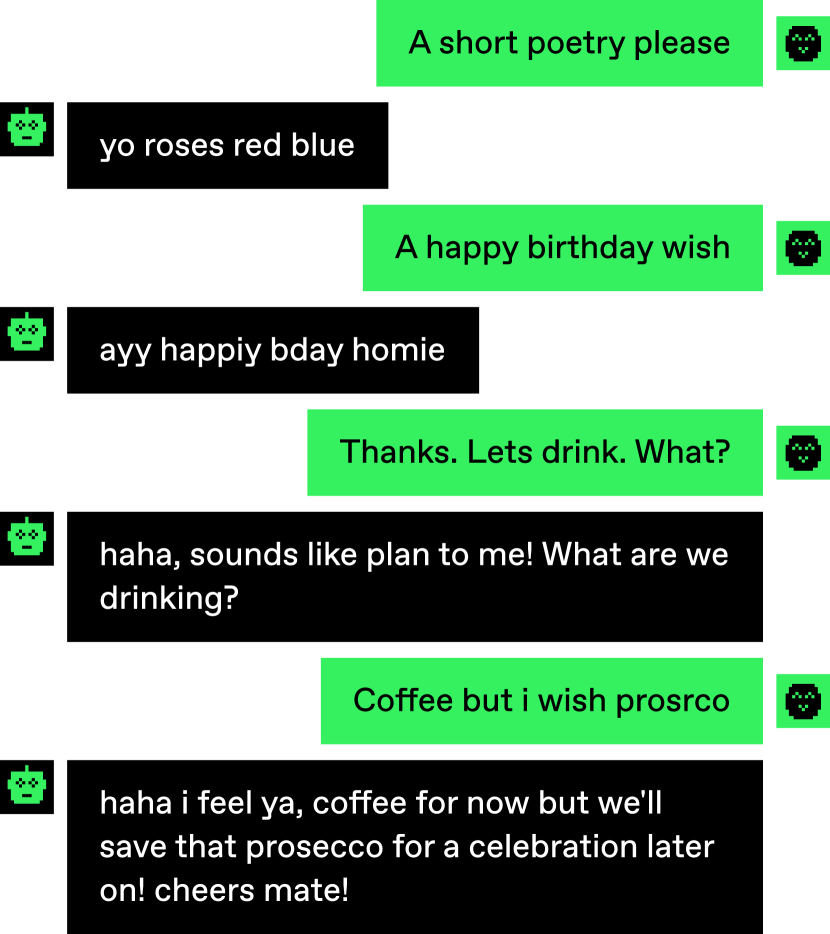
실험 결과
연구 질문
- RQ1짧고 개방형 대화에서 인간이 AI를 구분하는 기본 능력은 무엇인가?
- RQ2봇 디자인 선택(페르소나, 언어 스타일, 정보 기반) 등이 탐지 가능성에 어떤 영향을 미치는가?
- RQ3튜링 유사 환경에서 어떤 인간 전략이 AI를 가장 효과적으로 식별하거나 인간성을 신호하는가?
- RQ4사용자가 AI를 모방하거나 AI의 한계를 시험할 때 어떤 행동 패턴이 나타나는가?
주요 결과
| 주요 결과 | 값 |
|---|---|
| 전체 정답 확률 | 68% |
| 파트너가 봇일 때 | 60% |
| 파트너가 사람일 때 | 73% |
- 전체 정답 추측 비율은 68%입니다.
- 파트너가 봇인 경우 정답 추측 비율은 60%입니다.
- 파트너가 사람이면 정답 추측 비율은 73%입니다.
- 인간은 AI 대 인간을 구분하기 위해 다양한 전략(문법적 단서, 개인적/주관적 질문, 공손함, 최신 정보)을 활용했고 성공 정도는 다르게 나타났다.
- 봇 설계자는 다양한 페르소나와 실시간 정보 기반으로 탐지 가능성을 줄였고, 반면 인간은 때때로 게임 환경에 대한 메타참조를 활용해 인간성을 신호했다.
- 본 연구는 AI가 인간을 모방하는 능력에서 상당한 발전을 보여주고 향후 튜링 유사 평가를 위한 확장 가능한 벤치마크를 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.