[논문 리뷰] HyperCLOVA X Technical Report
HyperCLOVA X는 한국어에 초점을 맞춘 대형 언어 모델 계열(HCX-L 및 HCX-S)로, 한국어, 영어, 코드 데이터를 기반으로 학습되고 지시 학습(SFT) 및 RLHF를 포함합니다. 이는 한국어 능력이 강하고 영어 성능이 경쟁적이며 다국어 번역 및 신중한 안전 평가를 보입니다.
We introduce HyperCLOVA X, a family of large language models (LLMs) tailored to the Korean language and culture, along with competitive capabilities in English, math, and coding. HyperCLOVA X was trained on a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines reflecting our commitment to responsible AI. The model is evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. HyperCLOVA X exhibits strong reasoning capabilities in Korean backed by a deep understanding of the language and cultural nuances. Further analysis of the inherent bilingual nature and its extension to multilingualism highlights the model's cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks. We believe that HyperCLOVA X can provide helpful guidance for regions or countries in developing their sovereign LLMs.
연구 동기 및 목표
- 한국어와 문화에 맞춘 한국어 중심 LLM 계열을 개발하면서도 영어 및 코드 능력을 유지합니다.
- 균형 잡힌 한국어-영어-코드 데이터에 대해 사전 학습하고 지시 학습(SFT) 및 RLHF를 적용하여 정렬시키고자 합니다.
- 한국어와 영어의 포괄적 벤치마크에서 평가하여 이중 언어 숙련도, 다국어 일반화 및 안전 준수를 입증합니다.
- 교차 언어 추론 및 머신 번역을 포함한 다국어 능력을 아시아 언어 간으로 확장하여 시연합니다.
- 주권 LLM 개발 관점에서 안전, 레드팀, 책임 있는 AI 고려 사항을 논의합니다.
제안 방법
- 로테리 위치 임베딩과 프리노멀라이제이션을 갖춘 트랜스포머 디코더 아키텍처.
- 한국어에 최적화된 100,000 어휘 크기의 형태소 인식 바이트-레벨 BPE 토크나이저.
- In-filling 능력을 가능하게 하는 공동 PSM & SPM 프리트레이닝.
- 다양한 도메인에서 지시 이행을 개선하기 위한 지도학습 미세조정(SFT).
- 사람의 피드백에서 얻은 강화 학습(RLHF)을 PPO로 수행하며 보상 모델 및 KL 페널티를 사용하여 인간 선호에 정렬.
- 반복 억제 및 비동기적 이벤트 기반 정렬 파이프라인(NSML 상의 CLOps 및 MLflow)으로 시퀀스 수준의 비가능성 학습을 통합.
실험 결과
연구 질문
- RQ1HyperCLOVA X가 한국어 특정 벤치마크에서 영어 벤치마크 및 다국어 기준선과 비교하여 어떤 성능을 보이나요?
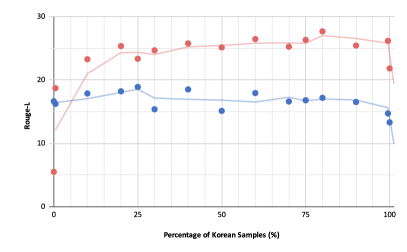
- RQ2한국어와 다른 언어 간의 교차 언어 능력 및 번역 성능은 어떠한가요?
- RQ3한 언어에서의 지시 학습이 다른 언어에서의 지시 수행 능력을 가져올 수 있나요(교차 언어 이전)?
- RQ4안전성과 정렬 절차가 유용성을 보존하면서 해로운 콘텐츠를 완화하는 데 얼마나 효과적인가요?
- RQ5이중언어/다국어 평가에서 얻은 통찰이 주권 LLM 개발 및 지역 AI 정책에 어떤 시사점을 제공하나요?
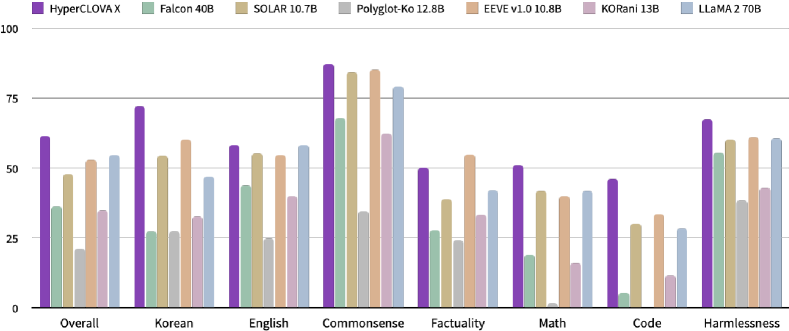
주요 결과
| 모델 | 한국어 | 영어 | CS | 사실 | 수학 | 코드 | 무해성 | 종합 |
|---|---|---|---|---|---|---|---|---|
| HCX-S | 61.73 | 47.08 | 76.56 | 46.88 | 39.04 | 37.71 | 62.08 | 53.01 |
| HCX-L | 72.07 | 58.25 | 87.26 | 56.83 | 50.91 | 46.10 | 67.32 | 62.68 |
- HCX-L은 한국어에 초점을 둔 벤치마크 대비 한국어 중심 벤치마크에서 선두 성능을 달성합니다.
- HCX-L은 영어 벤치마크에서 가장 큰 LLaMA 2 모델과 견줄 만한 영어 작업 성능을 달성합니다.
- HCX 모델은 강력한 교차 언어 전이 및 우수한 한국어-영어 이중언어 능력을 보입니다.
- 한국어와 일본어, 중국어 등 비표적 언어 간의 교차 언어 번역이 최신 수준에 도달합니다.
- 안전성 평가 및 레드팀 활동은 SFT/RLHF 및 강화 기법과 결합되어 주권 맥락에서 책임 있는 AI 배치를 지원합니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.