[논문 리뷰] Improving Multimodal Datasets with Image Captioning
이 논문은 이미지 캡션 모델이 생성한 합성 캡션을 웹에서 수집한 이미지-텍스트 데이터에 추가하는 것이 CLIP 학습을 개선하고, 작은 및 중간 규모에서 강력한 원시 데이터 필터링 baselines를 능가하며, 캡션 품질, 다양성 및 스케일링 효과에 대한 통찰을 제공한다.
Massive web datasets play a key role in the success of large vision-language models like CLIP and Flamingo. However, the raw web data is noisy, and existing filtering methods to reduce noise often come at the expense of data diversity. Our work focuses on caption quality as one major source of noise, and studies how generated captions can increase the utility of web-scraped datapoints with nondescript text. Through exploring different mixing strategies for raw and generated captions, we outperform the best filtering method proposed by the DataComp benchmark by 2% on ImageNet and 4% on average across 38 tasks, given a candidate pool of 128M image-text pairs. Our best approach is also 2x better at Flickr and MS-COCO retrieval. We then analyze what makes synthetic captions an effective source of text supervision. In experimenting with different image captioning models, we also demonstrate that the performance of a model on standard image captioning benchmarks (e.g., NoCaps CIDEr) is not a reliable indicator of the utility of the captions it generates for multimodal training. Finally, our experiments with using generated captions at DataComp's large scale (1.28B image-text pairs) offer insights into the limitations of synthetic text, as well as the importance of image curation with increasing training data quantity. The synthetic captions used in our experiments are now available on HuggingFace.
연구 동기 및 목표
- 노이즈가 많은 웹 스케일 이미지-텍스트 데이터셋의 품질 향상에 초점을 맞춰 동기를 부여한다.
- BLIP2 및 유사 모델에서 나온 합성 캡션이 다중 모달 사전 학습에 미치는 영향을 평가한다.
- 원시 캡션과 합성 캡션의 혼합 전략을 전통적인 필터링과 비교한다.
- 노이즈, 다양성, 이미지-텍스트 정렬과 같은 캡션 품질 요소가 성능 향상을 설명하는지 분석한다.
제안 방법
- 캡션 모델(BLIP, BLIP2, OpenCLIP-CoCa)을 사용하여 웹 수집 이미지-텍스트 쌍에 대해 top-K 샘플링으로 합성 캡션을 생성한다.
- 합성 캡션을 포함한 이미지-텍스트 쌍으로 CLIP 모델을 소형, 중형, 대형 후보 풀(12.8M, 128M, 1.28B)에서 학습한다.
- 제로샷 ImageNet, 38개 작업 평균 정확도, 그리고 Flickr30K 및 MS-COCO에서의 검색(리트리벌)을 평가한다.
- 합성 캡션의 다운스트림 CLIP 성능에 대한 영향을 평가하기 위해 MS-COCO에서 미세조정 여부에 따라 캡션 모델을 비교한다.
- 필터링 없는 데이터 혼합, CLIP-점수 필터링, 합성 캡션과 원시 캡션의 혼합 등 코사인 유사도 임계값 하에 데이터 혼합 전략을 실험한다.

실험 결과
연구 질문
- RQ1합성 캡션이 원시 웹 데이터만 필터링하는 것과 비교해 CLIP 훈련을 개선하는가?
- RQ2다양한 캡션 모델과 그 학습(미세조정 여부)이 다중모달 학습 효과에 어떤 영향을 주는가?
- RQ3데이터 규모에 따라 원시 캡션과 합성 캡션의 어떤 혼합 전략이 성능을 극대화하는가?
- RQ4노이즈, 다양성, 정렬성 같은 캡션의 어떤 속성이 다운스트림 작업의 성능 향상을 이끄는가?
- RQ5합성 캡션의 이점이 소규모에서 초대형 데이터 풀로 확장될 때 어떻게 달라지는가?
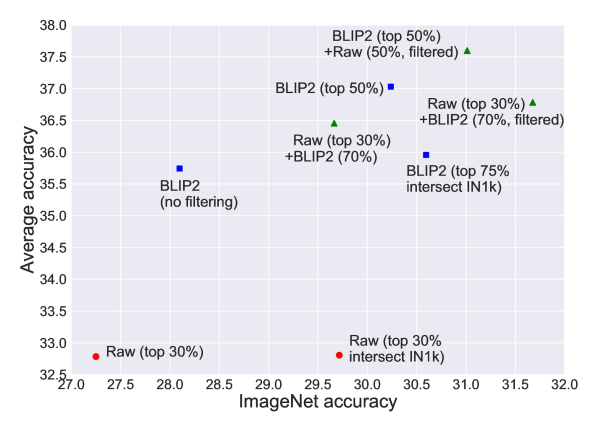
주요 결과
| 방법 | Avg Retrieval (MS-COCO & Flickr) |
|---|---|
| 원시 (필터링 없음) | 13.2 |
| 원시 (상위 30% IN1k 교차) | 18.2 |
| 원시 (상위 30%) | 19.7 |
| 원시 (상위 30%) + BLIP2 (70%, 필터링) | 38.0 |
| BLIP2 (상위 75% 교차 IN1k) | 38.9 |
| BLIP2 (상위 50%) | 40.1 |
| 원시 (상위 30%) + BLIP2 (70%) | 40.5 |
| BLIP2 (필터링 없음) | 41.7 |
- 캡션 생성 목적에 대해 미세조정되지 않은 캡션 모델이 ImageNet 및 검색 성능에서 미세조정 캡션 생성 모델보다 더 나은 전반적인 CLIP 성능을 내는 경향이 있는데, 이는 텍스트 다양성이 더 높기 때문이다.
- 합성 캡션은 일반적으로 원시 캡션보다 이미지-텍스트 정렬이 더 높고(노이즈가 더 낮음), 반면 원시 캡션은 더 높은 다양성을 제공한다; 두 가지를 코사인 임계값 아래에서 결합하면 더 좋은 결과를 얻는다.
- 중간 규모(128M)에서 원시 캡션과 합성 캡션을 코사인 임계값으로 혼합하면 ImageNet 및 평균 38개 작업 성능이 원시 데이터의 최상 baselines보다 대략 2% 더 나은, 작업 평균은 약 4%.
- BLIP2로 생성된 캡션은 원시 캡션만 사용할 때보다 Flickr 및 MS-COCO 검색에서 상당히 향상되며(2배 이상 증가).
- 대규모(400M–1.28B)에서 이미지 콘텐츠 큐레이션 및 텍스트 다양성을 다루지 않으면 ImageNet의 이점은 감소하지만 합성 캡션으로 인한 검색 성능 증가가 규모에 걸쳐 지속된다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.