[논문 리뷰] In-Context Learning for Extreme Multi-Label Classification
논문은 고정된 검색기(frozen retriever)와 두 개의 in-context LM 모듈을 결합한 모듈형 in-context 학습 프로그램인 Infer--Retrieve--Rank를 제안하여 파인튜닝 없이도 극한 다중 레이블 분류를 다루고, 여러 벤치마크에서 최첨단 성능을 달성합니다. 최적화는 DSPy를 사용하여 소수의 라벨링 예제만으로 프롬프트를 부트스트래핑합니다.
Multi-label classification problems with thousands of classes are hard to solve with in-context learning alone, as language models (LMs) might lack prior knowledge about the precise classes or how to assign them, and it is generally infeasible to demonstrate every class in a prompt. We propose a general program, $ exttt{Infer--Retrieve--Rank}$, that defines multi-step interactions between LMs and retrievers to efficiently tackle such problems. We implement this program using the $ exttt{DSPy}$ programming model, which specifies in-context systems in a declarative manner, and use $ exttt{DSPy}$ optimizers to tune it towards specific datasets by bootstrapping only tens of few-shot examples. Our primary extreme classification program, optimized separately for each task, attains state-of-the-art results across three benchmarks (HOUSE, TECH, TECHWOLF). We apply the same program to a benchmark with vastly different characteristics and attain competitive performance as well (BioDEX). Unlike prior work, our proposed solution requires no finetuning, is easily applicable to new tasks, alleviates prompt engineering, and requires only tens of labeled examples. Our code is public at https://github.com/KarelDO/xmc.dspy.
연구 동기 및 목표
- 파인튜닝 없이도 수천 개의 클래스가 있는 극한 다중 레이블 분류(XMC)의 도전을 인-context 학습만으로 해결할 수 있는지 확인한다.
- 고정된 구성 요소와 최소한의 감독으로 강력한 성능에 도달하기 위해 모듈식 파이프라인(Infer--Retrieve--Rank)을 제안한다.
- 다양한 데이터셋에 맞게 파인튜닝 없이도 DSPy 프로그래밍 모델을 통해 프롬프트 부트스트래핑과 최적화를 자동화한다.
- 여러 XMC 벤치마크(HOUSE, TECH, TECHWOLF, BioDEX)에서의 효과를 보여주고 비용 효율적인 배치를 입증한다.
제안 방법
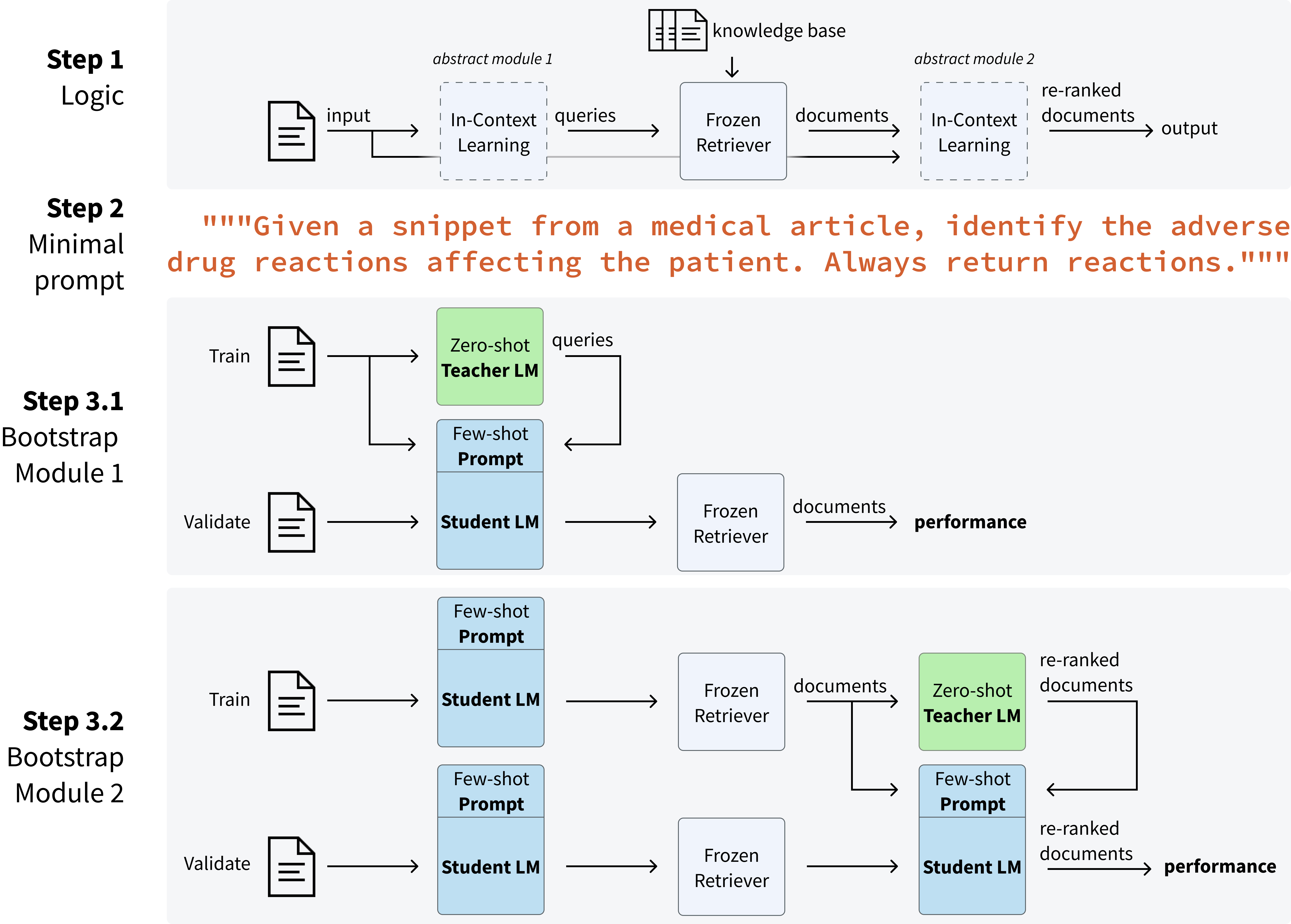
- Infer--Retrieve--Rank(IReRa)라는 세 단계 프로그램을 도입한다: Infer(입력으로부터 관련 레이블 질의를 LM이 예측), Retrieve(고정된 검색기가 질의 유사도에 따라 레이블을 순위화), Rank(LM이 검색된 레이블을 재정렬).
- DSPy 프레임워크를 사용하여 모듈을 선언적으로 지정하고 부트스트랩된 소수 샷 프롬프트로 작업별로 최적화한다.
- 두 LM 구성요소를 위한 소수 샷 프롬프트를 부트스트랩하기 위해 제로샷 교사 LM을 사용하고, 최적화는 약 50개의 라벨링된 검증 예제와 작업당 약 20명의 교사 + 1,500명의 학생 LM 호출에 의존한다.
- Infer를 Llama-2-7b-chat(학생)와 GPT-3.5(교사)로, Rank를 GPT-4로, Retrieve를 고정된 all-mpnet-base-v2/BioLORD-유사 검색기처럼 구현한다.
- 데이터셋별 모듈(Infer/Rank)의 인-컨텍스트 동작과 최소한의 제로샷 프롬프트를 정의하는 시드 프롬프트를 제공하고, DSPy가 부트스트래핑과 레이블 선택을 처리한다.
- 네 데이터셋에서 RP@5와 RP@10 메트릭을 평가하고 이전 벤치마크 및 파인튜닝 시스템과 비교한다.
실험 결과
연구 질문
- RQ1파인튜닝 없이도 모듈형 인-context 학습 파이프라인이 경쟁력 있거나 최첨단의 XMC 성능을 달성할 수 있는가?
- RQ2작업별로 performant한 IReRa 프로그램을 부트스트랩하는 데 필요한 라벨링 데이터 양과 LM 호출 수는 어느 정도인가?
- RQ3각 모듈(Infer, Retrieve, Rank)과 그 최적화가 XMC 성능에 어떤 영향을 미치는가?
- RQ4의료 생물학 데이터와 ESCO 직무 기술과 같은 서로 다른 특성을 가진 작업들 간에 이 접근법이 어떻게 일반화되는가?
주요 결과
| Dataset | RP@5 | RP@10 |
|---|---|---|
| HOUSE | 56.50 | 65.76 |
| TECH | 59.61 | 70.23 |
| TECHWOLF | 57.04 | 65.17 |
| BioDEX | 24.73 | 27.67 |
- IReRa는 파인튜닝 없이 HOUSE, TECH, TECHWOLF 데이터셋에서 RP@5 및 RP@10의 최첨단 성능을 달성하며 약 50개의 라벨링된 검증 예제에서 동작한다.
- BioDEX에서는 IReRa가 의미 있는 개선을 보이나 최상의 파인튜닝 시스템보다 엄밀히 우수하지는 않으며, Rank 모듈을 추가하거나 Infer를 더 최적화하면 결과가 개선된다.
- 최적 프로그램인 Infer--Retrieve--Rank는 하나의 고정된 검색기와 두 개의 LM 모듈을 사용하며, 부트스트래핑에 대해 작업당 약 20명의 교사 호출 및 1,500명의 학생 호출 수준의 비용이 들고, 새로운 입력마다 모듈당 대략 한 번의 LM 호출이 필요하다.
- 최적화 단계(Infer, Retrieve, Rank) 각각이 성능 향상에 기여하며, 더 간단한 Infer--Retrieve 설정조차도 단일 LM과 고정된 검색기로도 경쟁력 있는 결과를 낸다.
- 파인튜닝 시스템과 비교할 때 IReRa는 데이터 요구량이 낮고 광범위한 프롬프트 엔지니어링을 회피하는 한편, 최소한의 시드 프롬프트와 DSPy 기반 최적화를 통해 새로운 데이터셋에 적응할 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.