[논문 리뷰] Instruction-Following Evaluation for Large Language Models
IFEval은 검증 가능한 지시사항에 대해 LLM을 평가하는 자동 벤치마크로, 인간 또는 모델 기반 판단에 대한 의존도를 줄입니다.
One core capability of Large Language Models (LLMs) is to follow natural language instructions. However, the evaluation of such abilities is not standardized: Human evaluations are expensive, slow, and not objectively reproducible, while LLM-based auto-evaluation is potentially biased or limited by the ability of the evaluator LLM. To overcome these issues, we introduce Instruction-Following Eval (IFEval) for large language models. IFEval is a straightforward and easy-to-reproduce evaluation benchmark. It focuses on a set of "verifiable instructions" such as "write in more than 400 words" and "mention the keyword of AI at least 3 times". We identified 25 types of those verifiable instructions and constructed around 500 prompts, with each prompt containing one or more verifiable instructions. We show evaluation results of two widely available LLMs on the market. Our code and data can be found at https://github.com/google-research/google-research/tree/master/instruction_following_eval
연구 동기 및 목표
- 안전성과 신뢰성을 위해 LLM의 지시 이행 표준화된 평가의 필요성을 제시한다.
- 객관적이고 자동화된 평가를 가능하게 하는 검증 가능한 지시를 도입한다.
- 검증 가능한 지시를 포함하는 프롬프트 데이터셋을 구성하고 널리 사용되는 모델들에 대한 기본 벤치마크 결과를 제공한다.
제안 방법
- 응답에서 객관적으로 검증될 수 있는 검증 가능한 지시를 정의한다.
- 대략 500개의 프롬프트를 만들되 각 프롬프트에는 하나 이상의 검증 가능한 지시가 포함되며 25가지 지시 유형이 있다.
- 검증 경계 케이스를 고려한 엄격한 및 느슨한 지시 이행 정확도 지표를 제안한다.
- 두 모델(GPT-4 및 PaLM 2 S)에 대한 프롬프트 수준 및 지시 수준 평가를 사용한다.
- 베이스 프롬프트, few-shot 선별, 재서술 단계를 포함한 프롬프트 합성 절차를 기술한다.

실험 결과
연구 질문
- RQ1검증 가능한 지시를 사용하여 지시 이행 정확도를 객관적으로 측정할 수 있는가?
- RQ2다양한 지시 카테고리가 모델의 지시 준수에 어떤 영향을 미치는가?
- RQ3검증 가능한 지시에서 널리 사용 가능한 LLM들의 기본 지시 이행 성능은 어떤가?
- RQ4실제로 엄격한 검증 기준과 느슨한 검증 기준은 어떻게 비교되는가?
주요 결과
| 모델 | 프롬프트 수준 엄격 정확도 (%) | 지시 수준 엄격 정확도 (%) | 프롬프트 수준 느슨 정확도 (%) | 지시 수준 느슨 정확도 (%) |
|---|---|---|---|---|
| GPT-4 | 76.89 | 83.57 | 79.30 | 85.37 |
| PaLM 2 S | 43.07 | 55.76 | 46.95 | 59.11 |
- IFEval은 광범위한 검증 가능한 프롬프트에 대한 지시 이행의 자동 검증을 가능하게 한다.
- GPT-4가 보고된 기본값에서 엄격 및 느슨한 지표 모두에서 PaLM 2 S보다 높은 정확도를 달성한다.
- 엄격한 정확도는 경계 케이스와 검증의 어려움으로 인해 느슨한 정확도보다 낮다.
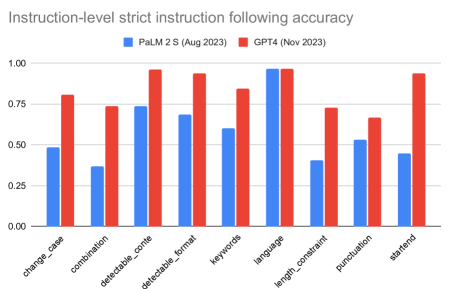
- 자세한 카테고리 분석에 나타나듯 지시 카테고리마다 지시 준수에 차이가 있다.
- 평가 프레임워크는 재현 가능하며 저자들은 코드와 프롬프트를 공개한다.
- 두 평가 지표(엄격하고 느슨한)는 검증에서 위양성 및 위음성을 균형 있게 다루는 데 도움을 준다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.