[논문 리뷰] Is ChatGPT a Highly Fluent Grammatical Error Correction System? A Comprehensive Evaluation
본 논문은 ChatGPT (gpt-3.5-turbo)를 다국어 및 문서 수준 작업에서의 문법 오류 수정(GEC)에 대해 평가하고, 제로샷 및 파샷 체인오브생각(CoT) 프롬팅을 사용하며, SOTA 모델 및 Grammarly와 비교한다.
ChatGPT, a large-scale language model based on the advanced GPT-3.5 architecture, has shown remarkable potential in various Natural Language Processing (NLP) tasks. However, there is currently a dearth of comprehensive study exploring its potential in the area of Grammatical Error Correction (GEC). To showcase its capabilities in GEC, we design zero-shot chain-of-thought (CoT) and few-shot CoT settings using in-context learning for ChatGPT. Our evaluation involves assessing ChatGPT's performance on five official test sets in three different languages, along with three document-level GEC test sets in English. Our experimental results and human evaluations demonstrate that ChatGPT has excellent error detection capabilities and can freely correct errors to make the corrected sentences very fluent, possibly due to its over-correction tendencies and not adhering to the principle of minimal edits. Additionally, its performance in non-English and low-resource settings highlights its potential in multilingual GEC tasks. However, further analysis of various types of errors at the document-level has shown that ChatGPT cannot effectively correct agreement, coreference, tense errors across sentences, and cross-sentence boundary errors.
연구 동기 및 목표
- 다양한 공식 테스트 세트를 사용하여 English, German, Chinese에서 ChatGPT의 문장 수준 GEC 능력을 평가한다.
- GEC를 위한 체인-오브-생각(CoT) 프롬트에서 제로샷 및 파샷 인-context 학습을 조사한다.
- English의 문서 수준 GEC에서 ChatGPT의 성능을 평가하고 오류 유형을 분석한다.
- 자동 평가와 수동 인간 평가를 수행하여 자연스러움과 편집 행태를 이해한다.
- 비영어 및 저자원 GEC 성능을 검토하고 강점과 한계를 식별한다.
제안 방법
- 문장 구조를 보존하면서 문법 오류를 식별하고 수정하기 위해 ChatGPT용 제로샷 및 제로샷 CoT 프롬트를 설계한다.
- 여러 데이터세트에 걸쳐 무작위로 선택된 인-컨텍스트 예제를 포함한 파샷 CoT 프롬트를 개발한다.
- 영어, 독일어, 중국어의 다섯 개 문장 수준 테스트 세트와 영어 문서 수준 세트 세 개를 자동 메트릭과 인간 평가를 사용하여 평가한다.
- 적합한 경우 M2 Scorer, ERRANT, GLUE 기반 메트릭을 사용하여 Transformer-base, GECToR, T5-large, Grammarly과 ChatGPT를 비교한다.
- ERRANT를 사용한 문서 수준 GEC의 수동 오류 유형 분석을 수행하여 문장 간 오류 패턴과 한계를 식별한다.

실험 결과
연구 질문
- RQ1제로샷 및 파샷 CoT 프롬프트를 사용할 때 ChatGPT의 영어, 독일어, 중국어 문장 수준 GEC 성능은 어떠한가?
- RQ2체인오브생각 프롬프트가 표준 프롬프트보다 ChatGPT의 GEC 성능을 향상시키는가?
- RQ3표준 벤치마크 및 유창성 중심 지표에서 ChatGPT가 SOTA GEC 시스템 및 Grammarly와 어떻게 비교되는가?
- RQ4문서 수준 GEC에서 ChatGPT의 강점과 한계는 무엇이며 어떤 오류 유형에서 어려움을 겪는가?
- RQ5비영어 및 저자원 GEC 환경에서 ChatGPT는 효과적인가?
주요 결과
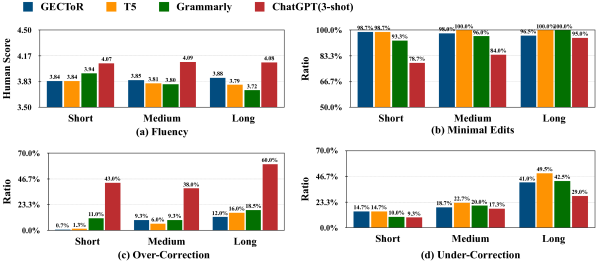
- 문장 수준 작업에서 ChatGPT는 높은 재현율과 강한 유창성을 달성하지만 SOTA 모델에 비해 정밀도와 F0.5가 낮다.
- 파샷 CoT 프롬프팅은 일반적으로 제로샷 CoT보다 성능을 향상시키며, 3샷이 종종 최상위에 속한다; 다섯 샷 이상은 성능을 저하시킬 수 있다.
- JFLEG의 유창성 중심 측정에서 ChatGPT의 3-shot CoT는 SOTA에 거의 근접하고 T5-large를 능가할 수 있어 강한 유창성 교정임을 시사한다.
- 비영어 및 저자원 언어에서 ChatGPT는 재현율은 우수하나 정밀도와 F0.5에서 종종 뒤처지며 언어에 따라 성능이 다르다.
- 문서 수준 GEC는 ChatGPT의 높은 재현율과 유창성을 보여주지만 문장 간 일치, 지칭, 시제 등의 오류 수정 및 문장 경계 간 처리에서 미흡함을 드러낸다.
- 자동 및 인간 평가에서 ChatGPT가 일부 설정에서 인간 수준의 유창성에 접근하거나 이를 초과할 수 있음을 보이지만 최소 편집 제약 하에서는 여전히 참조 교정과 차이가 있을 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.