[논문 리뷰] Jump to Conclusions: Short-Cutting Transformers With Linear Transformations
이 논문은 계층-대-계층 선형 매핑을 학습하여 숨겨진 트랜스포머 표현을 바꿔 최종 레이어 출력에 대한 더 나은 근사를 가능하게 하고 초기 종료 및 모듈 선형 근사에서 효율성을 향상시킨다.
Transformer-based language models create hidden representations of their inputs at every layer, but only use final-layer representations for prediction. This obscures the internal decision-making process of the model and the utility of its intermediate representations. One way to elucidate this is to cast the hidden representations as final representations, bypassing the transformer computation in-between. In this work, we suggest a simple method for such casting, using linear transformations. This approximation far exceeds the prevailing practice of inspecting hidden representations from all layers, in the space of the final layer. Moreover, in the context of language modeling, our method produces more accurate predictions from hidden layers, across various model scales, architectures, and data distributions. This allows "peeking" into intermediate representations, showing that GPT-2 and BERT often predict the final output already in early layers. We then demonstrate the practicality of our method to recent early exit strategies, showing that when aiming, for example, at retention of 95% accuracy, our approach saves additional 7.9% layers for GPT-2 and 5.4% layers for BERT. Last, we extend our method to linearly approximate sub-modules, finding that attention is most tolerant to this change. Our code and learned mappings are publicly available at https://github.com/sashayd/mat.
연구 동기 및 목표
- 중간 트랜스포머 표현을 이용하는 해석 가능성과 효율성 향상이 최종 레이어 표현만 사용하는 것보다 더 큰 이점을 주는지 동기 부여한다.
- 어떤 초기 레이어의 숨겨진 상태를 나중의 레이어로 변환하기 위한 가벼운 선형 매핑(mat)을 제안한다.
- 여러 데이터 소스에서 GPT-2와 BERT에 대해 mat이 최종 레이어 표현과 예측을 얼마나 잘 근사하는지 평가한다.
- 조기 종료 및 어텐션, FFN, 레이어 정규화와 같은 서브 모듈을 선형 근사로 대체했을 때의 실용적 이점을 입증한다.
제안 방법
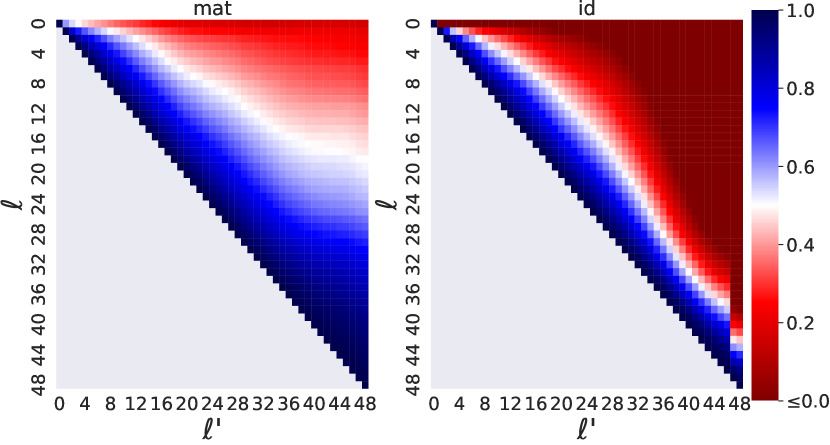
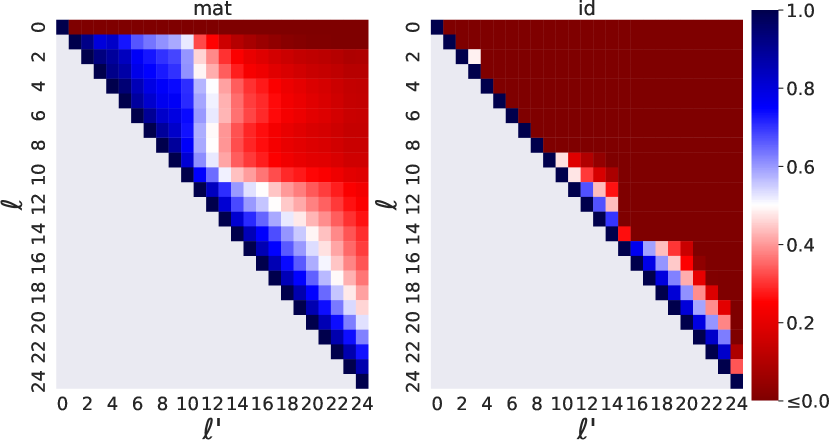
- 어떤 계층 쌍 ell < ell'에 대해 숨겨진 상태 쌍을 시스템을 통해 모델을 실행하며 수집한 회귀 손실을 최소화하여 d_h x d_h 매트릭스 A_{ell',ell}를 학습한다.
- mat_{ell→ell'}를 표현을 변경 없이 전파하는 기준선 아이드 매핑과 비교한다.
- mat(h^{ell})와 실제 h^{ell'} 사이의 좌표별 결정계수(R^2)를 사용하여 근사 품질을 측정한다.
- 학습된 매핑을 다음 토큰 예측과 마스킹된 토큰 예측 작업에 적용하여 Precision@k와 surprisal을 통해 예측 정렬성을 평가한다.
- 선형 지름길을 확장하여 서브 모듈(어텐션, FFN, 레이어 정규화)을 선형 근사로 대체하고 예측 정확도에 대한 영향을 평가한다.
- 정체 매핑을 mat으로 대체하여 다이나믹 종료 결정에서의 조기 종료 유틸리티를 시연하고 컴퓨트 절감 효과를 비교한다.
실험 결과
연구 질문
- RQ1트랜스포머 계층 간의 간단한 선형 매핑이 일반적인 아이덴티티 전파보다 최종 레이어 표현의 더 정확한 대체를 제공할 수 있는가?
- RQ2이러한 매핑이 다음 토큰 및 마스킹된 토큰 작업에서 모델의 예측 토큰 분포를 얼마나 잘 보존하는가?
- RQ3선형 지름길이 조기 종료 및 어텐션, FFN, 레이어 정규화 같은 서브 모듈 대체에서 실질적인 효율성 향상을 가능하게 하는가?
주요 결과
- Mat은 GPT-2와 BERT 전반에서 아이덴티티 기반 기준선보다 일관되게 더 높은 R^2 점수를 보이며, 특히 BERT의 경우 아이덴티티가 계층 간 매핑에 실패하는 경우가 많다.
- 언어 모델링 작업에서 mat은 id에 비해 Prediction@k를 향상시키고 Surprisal을 낮추며, 특히 초기 레이어에서 큰 이점을 보인다(예: GPT-2의 레이어 44까지 상당한 정확도 향상).
- 조기 종료에 mat을 사용하면 이전 접근 방식보다 더 많은 레이어를 절약할 수 있는데, 예를 들어 GPT-2에서 7.9% 더 많은 레이어, BERT에서 5.4% 더 많은 레이어를 저장하여 95% 정확도에 도달한다.
- 초기 표현이 이미 최종 예측을 의미 있는 정도로 인코딩하는 경향이 있음을 보여주며, 초기 레이어에서 비트관계가 0.28–0.45 수준의 예측 정렬과 같은 비피해적인 정렬 정합성을 보인다.
- 서브 모듈을 선형 근사로 대체하는 것은 어텐션이 선형 대체에 가장 관용적이며, FFN 및 레이어 정규화는 더 민감하지만 여전히 많은 경우에 선형 근사 가능하다는 것을 보여준다.
- 일부 레이어에서 서브 모듈을 선형 지름길로 대체하는 것이 재앙적 손실 없이 가능하여 병렬식 계산 이점이 있을 수 있음을 시사한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.