[논문 리뷰] Language Agents with Reinforcement Learning for Strategic Play in the Werewolf Game
이 논문은 대형 언어 모델과 강화 학습을 결합한 프레임워크를 제안하여 Werewolf를 위한 전략적 언어 에이전트를 구축하고 내재적 편향 및 숨겨진 정보 추론 문제를 다루며, 인간 수준의 플레이를 포함한 baselines보다 우수한 성능을 보임을 시사합니다.
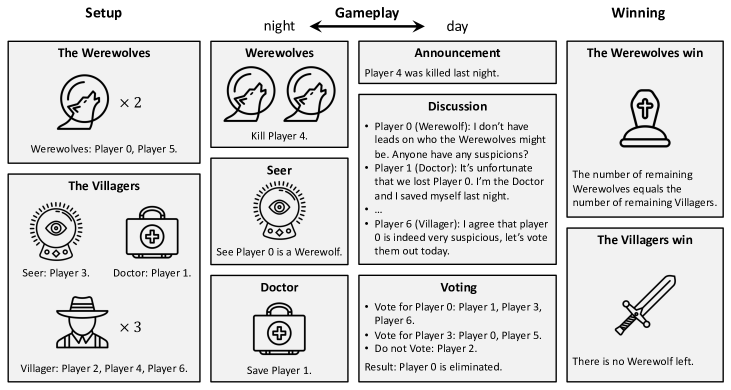
Agents built with large language models (LLMs) have shown great potential across a wide range of domains. However, in complex decision-making tasks, pure LLM-based agents tend to exhibit intrinsic bias in their choice of actions, which is inherited from the model's training data and results in suboptimal performance. To develop strategic language agents, i.e., agents that generate flexible language actions and possess strong decision-making abilities, we propose a novel framework that powers LLM-based agents with reinforcement learning (RL). We consider Werewolf, a popular social deduction game, as a challenging testbed that emphasizes versatile communication and strategic gameplay. To mitigate the intrinsic bias in language actions, our agents use an LLM to perform deductive reasoning and generate a diverse set of action candidates. Then an RL policy trained to optimize the decision-making ability chooses an action from the candidates to play in the game. Extensive experiments show that our agents overcome the intrinsic bias and outperform existing LLM-based agents in the Werewolf game. We also conduct human-agent experiments and find that our agents achieve human-level performance and demonstrate strong strategic play.
연구 동기 및 목표
- 사회적 추리 게임에서 복잡한 의사결정을 수행할 수 있는 전략적 언어 에이전트의 개발을 촉진한다.
- 다양한 행동 생성과 강화 학습을 통해 순수 LLM 기반 에이전트의 내재적 편향을 해결한다.
- 속임수 정보의 처리를 위한 숨겨진 역할 추론을 가능하게 하여 후속 의사결정을 개선한다.
제안 방법
- 숨겨진 역할 추론: 관찰을 정리하고 진실과 속임수를 분류하며 속성(역할, 신뢰성, 추론, 증거)을 생성하기 위해 LLM을 사용합니다.
- 다양한 행동 생성: 배치 프롬프트나 반복 프롬프트를 통해 여러 후보 행동(N)을 생성하여 행동 편향을 줄이고 전략적 다양성을 높입니다.
- 개체군 기반 RL 학습: LLM의 임베딩에서 입력된 자신감 기반 네트워크를 사용하여 언어 행동 후보 중에서 선택하는 가벼운 정책을 학습합니다; 다양한 에이전트의 개체군과 함께 학습하여 강건성을 높입니다.
- 행동 선택: LLM 임베딩 API를 사용하여 관찰과 후보를 벡터화하고 잔차 자체 주의 인코더를 사용하여 관찰과 후보 임베딩 간의 스케일링된 닷 프로덕트에 비례하는 확률을 계산합니다.

실험 결과
연구 질문
- RQ1복잡한 언어 기반 게임을 플레이할 때 순수 LLM 기반 에이전트의 내재적 편향을 어떻게 극복할 수 있을까?
- RQ2LLM의 추론과 학습된 RL 정책을 결합하면 Werewolf의 전략적 의사결정이 개선될까?
- RQ3다양한 언어 행동 후보를 생성하고 개체군 기반 학습을 적용하면 다양한 상대에 대해 더 강건한 정책이 나올까?
주요 결과
- 제안된 RL 프레임워크를 가진 에이전트는 내재적 편향을 극복하고 순수 LLM 기반 에이전트보다 더 균질하고 전략적인 행동 분포를 보입니다.
- 라운드 로빈 토너먼트에서 전략적 언어 에이전트는 여러 베이스라인에 대해 Villagers와 Werewolves 모두에서 가장 높은 승률을 달성합니다.
- 인간-에이전트 실험에서 에이전트는 인간과 비슷한 승률에 도달하고 일부 설정에서는 인간 성능을 능가합니다.
- 제거(Ablation) 결과, 숨겨진 역할 추론, 다양한 행동 생성, 개체군 기반 RL의 세 가지 구성요소 모두 성능에 기여하며, 특히 편향 극복을 위해 RL 정책이 필수적임을 보여줍니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.