[논문 리뷰] Large Language Model Alignment: A Survey
LLM 정렬에 대한 포괄적 조사로, 외부 정렬과 내부 정렬, 해석 가능성, 취약점, 평가 벤치마크, 향후 방향을 자세히 다룬다.
Recent years have witnessed remarkable progress made in large language models (LLMs). Such advancements, while garnering significant attention, have concurrently elicited various concerns. The potential of these models is undeniably vast; however, they may yield texts that are imprecise, misleading, or even detrimental. Consequently, it becomes paramount to employ alignment techniques to ensure these models to exhibit behaviors consistent with human values. This survey endeavors to furnish an extensive exploration of alignment methodologies designed for LLMs, in conjunction with the extant capability research in this domain. Adopting the lens of AI alignment, we categorize the prevailing methods and emergent proposals for the alignment of LLMs into outer and inner alignment. We also probe into salient issues including the models' interpretability, and potential vulnerabilities to adversarial attacks. To assess LLM alignment, we present a wide variety of benchmarks and evaluation methodologies. After discussing the state of alignment research for LLMs, we finally cast a vision toward the future, contemplating the promising avenues of research that lie ahead. Our aspiration for this survey extends beyond merely spurring research interests in this realm. We also envision bridging the gap between the AI alignment research community and the researchers engrossed in the capability exploration of LLMs for both capable and safe LLMs.
연구 동기 및 목표
- LLM 정렬의 필요성을 자극하여 바람직하지 않거나 오해를 불러일으키거나 해로운 출력을 억제한다.
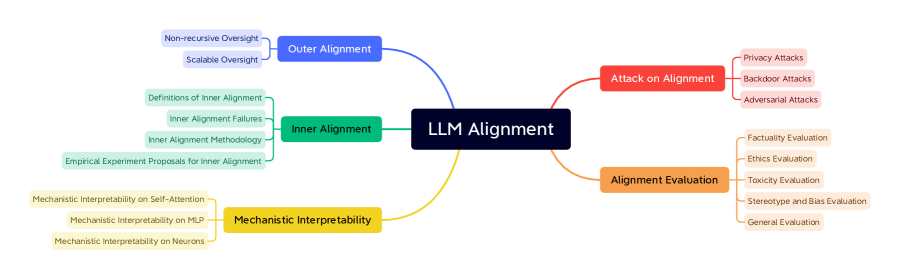
- AI 정렬에서 영감을 받은 전체적 분류 체계(외부 정렬, 내부 정렬, 해석 가능성)를 제공한다.
- 주요 외부 및 내부 정렬 방법, 기계적 해석 가능성, 평가 벤치마크를 요약한다.
- AI 정렬과 LLM 능력 커뮤니티를 연결하기 위한 취약점 및 향후 연구 방향을 식별한다.
제안 방법
- LLM 정렬 방법을 외부 정렬, 내부 정렬 및 기계적 해석 가능성으로 분류한다.
- 외부 정렬을 위한 비재귀적이고 확장 가능한 감독 접근법을 검토한다.
- 정렬된 LLM에 대한 취약점 및 공격적 공격을 논의한다.
- 사실성, 윤리, 독성, 편향 및 일반 정렬을 위한 평가 벤치마크를 조사한다.
- 향후 연구 방향과 현장 구축을 위한 고려사항을 제안한다.
실험 결과
연구 질문
- RQ1LLM의 외부 정렬의 주요 구성 요소와 접근 방법은 무엇인가?
- RQ2LLM 맥락에서 내부 정렬은 어떻게 정의되고 다루어지며, 그 도전과제는 무엇인가?
- RQ3기계적 해석 가능성은 LLM 정렬과 안전에서 어떤 역할을 하는가?
- RQ4LLM 정렬을 위한 벤치마크와 평가 방법론은 무엇이 있으며, 무엇을 평가하는가?
- RQ5LLM 정렬 연구 및 현장 협력을 촉진할 수 있는 향후 방향과 경로는 무엇인가?
주요 결과
- 외부 정렬은 비재귀적이고 확장 가능한 감독을 통해 추구되며, 확장 가능한 방법이 능력 있는 모델을 인간 가치에 맞추는 데 가장 유망한 것으로 간주된다.
- 내부 정렬과 해석 가능성은 의도된 목표를 따르고 이해될 수 있도록 외부 정렬과 함께 필수 구성 요소이다.
- LLM 정렬과 관련된 식별된 공격 벡터(프라이버시, 백도어, 적대적 공격)와 평가 체계(사실성, 윤리, 독성, 편향)가 있다.
- 본 조사는 이론적 연구, 자동화된 정렬, 투명성, 현장 구축을 포함한 향후 방향을 제시하여 LLM과 AI 정렬 커뮤니티를 연결한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.