[논문 리뷰] Large Language Models are Edge-Case Fuzzers: Testing Deep Learning Libraries via FuzzGPT
FuzzGPT는 LLM을 프라이밍하여 비정상적이고 엣지 케이스의 Python 코드 스니펫을 생성해 DL 라이브러리를 퍼징하고, in-context 학습과 파인튜닝을 통해 과거 버그 데이터를 활용함으로써 TitanFuzz를 능가합니다.
Deep Learning (DL) library bugs affect downstream DL applications, emphasizing the need for reliable systems. Generating valid input programs for fuzzing DL libraries is challenging due to the need for satisfying both language syntax/semantics and constraints for constructing valid computational graphs. Recently, the TitanFuzz work demonstrates that modern Large Language Models (LLMs) can be directly leveraged to implicitly learn all the constraints to generate valid DL programs for fuzzing. However, LLMs tend to generate ordinary programs following similar patterns seen in their massive training corpora, while fuzzing favors unusual inputs that cover edge cases or are unlikely to be manually produced. To fill this gap, this paper proposes FuzzGPT, the first technique to prime LLMs to synthesize unusual programs for fuzzing. FuzzGPT is built on the well-known hypothesis that historical bug-triggering programs may include rare/valuable code ingredients important for bug finding. Traditional techniques leveraging such historical information require intensive human efforts to design dedicated generators and ensure the validity of generated programs. FuzzGPT demonstrates that this process can be fully automated via the intrinsic capabilities of LLMs (including fine-tuning and in-context learning), while being generalizable and applicable to challenging domains. While FuzzGPT can be applied with different LLMs, this paper focuses on the powerful GPT-style models: Codex and CodeGen. Moreover, FuzzGPT also shows the potential of directly leveraging the instruct-following capability of the recent ChatGPT for effective fuzzing. Evaluation on two popular DL libraries (PyTorch and TensorFlow) shows that FuzzGPT can substantially outperform TitanFuzz, detecting 76 bugs, with 49 already confirmed as previously unknown bugs, including 11 high-priority bugs or security vulnerabilities.
연구 동기 및 목표
- DL 라이브러리의 downstream 영향이 넓은 버그의 robust한 테스트를 촉진한다.
- LLMs를 활용해 과거 버그 유발 코드를 활용하여 비정상적인 입력 프로그램을 생성하도록 FuzzGPT를 제안한다.
- 컨텍스트 내 학습과 파인튜닝을 통해 버그를 유발하는 코드를 자동으로 생성한다.
- PyTorch와 TensorFlow에서 FuzzGPT를 평가하고 TitanFuzz와 비교한다.
- 자동화된 퍼징을 통해 새로운 버그와 잠재적 취약점의 발견을 Demonstrate한다.
제안 방법
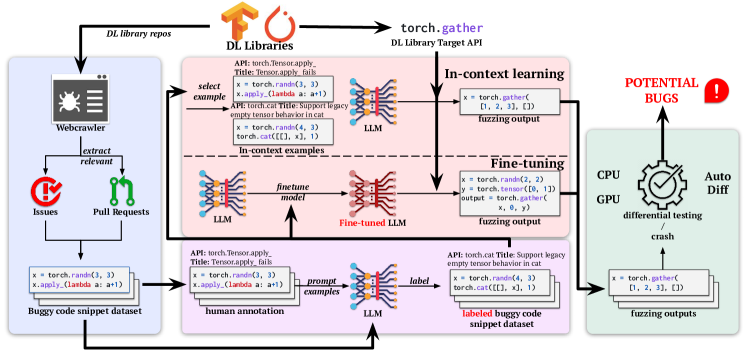
- 대상 DL 라이브러리에 대한 GitHub 이슈 및 PR에서 과거 버그를 유발하는 코드 스니펫을 발굴한다.
- Few manual labels를 사용한 self-training LLM 접근법으로 각 코드 스니펫의 버그 API를 주석 처리한다.
- 비정상적인 엣지 케이스 퍼징 코드를 생성하기 위해 세 가지 학습 전략을 적용한다: few-shot in-context learning, zero-shot completion/editing, 그리고 버그를 유발하는 코드에 대한 파인튜닝.
- 생성된 프로그램을 크래시, CPU/GPU 일관성, 자동 미분(AD) 오라클로 실행하여 버그를 탐지한다.
- PyTorch와 TensorFlow 라이브러리에서 Codex와 CodeGen LLM, zero-shot ChatGPT 변형을 사용하여 평가한다.

실험 결과
연구 질문
- RQ1RQ1: 서로 다른 FuzzGPT 학습 패러다임(few-shot, zero-shot, fine-tuning)은 효과성 면에서 어떻게 비교되는가?
- RQ2RQ2: FuzzGPT는 TitanFuzz와 같은 기존 퍼거와 비교하여 어떻게 수행하는가?
- RQ3RQ3: FuzzGPT의 핵심 구성 요소가 효과성에 어떻게 기여하는가?
- RQ4RQ4: FuzzGPT가 실제 DL 라이브러리에서 새로운 버그를 탐지할 수 있는가?
주요 결과
- FuzzGPT 변형은 PyTorch/TensorFlow에서 TitanFuzz보다 커버리지가 각각 60.70%/36.03% 더 높게 나타났다.
- FuzzGPT는 최신 PyTorch 및 TensorFlow 버전에서 76개의 버그를 발견했다.
- 이들 버그 중 49개는 새롭게 식별되었으며, 그중 11개는 고우선순위 또는 보안 관련으로 분류되었다.
- 연구는 GitHub에서 발굴된 PyTorch 1,750개 및 TensorFlow 633개의 버그-유발 스니펫을 사용했다.
- FuzzGPT는 Codex, CodeGen, ChatGPT 기반의 zero-shot 변형에서 효과를 입증한다.
- 이 접근법은 완전 자동화되어 있으며 DL 라이브러리 외의 다른 도메인에도 일반화 가능하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.