[논문 리뷰] Large Legal Fictions: Profiling Legal Hallucinations in Large Language Models
이 논문은 Open-domain의 일련의 케이스-법 연구 QA 작업을 적용하여 LLM의 법적 환각을 분석하고, 높은 환각 비율과 잘못된 법적 내용을 탐지하거나 수정하는 데 한계가 있음을 밝힙니다.
Do large language models (LLMs) know the law? These models are increasingly being used to augment legal practice, education, and research, yet their revolutionary potential is threatened by the presence of hallucinations -- textual output that is not consistent with legal facts. We present the first systematic evidence of these hallucinations, documenting LLMs' varying performance across jurisdictions, courts, time periods, and cases. Our work makes four key contributions. First, we develop a typology of legal hallucinations, providing a conceptual framework for future research in this area. Second, we find that legal hallucinations are alarmingly prevalent, occurring between 58% of the time with ChatGPT 4 and 88% with Llama 2, when these models are asked specific, verifiable questions about random federal court cases. Third, we illustrate that LLMs often fail to correct a user's incorrect legal assumptions in a contra-factual question setup. Fourth, we provide evidence that LLMs cannot always predict, or do not always know, when they are producing legal hallucinations. Taken together, our findings caution against the rapid and unsupervised integration of popular LLMs into legal tasks. Even experienced lawyers must remain wary of legal hallucinations, and the risks are highest for those who stand to benefit from LLMs the most -- pro se litigants or those without access to traditional legal resources.
연구 동기 및 목표
- 향후 연구의 프레이밍을 위한 법적 환각의 유형학을 개발한다.
- 확인 가능한 법률 질문에 대한 LLM 응답에서 사실상의 부정확성의 유병률을 정량화한다.
- contra-factual 전제를 다루는 능력과 답변에 대한 자신의 확신을 평가하는 능력을 평가한다.
- 모델 성능이 사례의 연령, 두드러짐, 법원 수준에 따라 어떻게 달라지는지 조사하여 법적 추론의 모노컬처 가능성을 식별한다.
제안 방법
- 복잡도가 증가하는 14개의 법학 연구 과제를 고유하게 생성한다(존재, 법원, 인용, 저자, 처분, 인용문, 권위, 폐지 연도, 교리적 합의, 사실 배경, 절차적 위치, 이후 이력, 핵심 법적 쟁점, 중심 판결)
- Caselaw Access Project, Supreme Court Database 및 기타 출처의 기준용 메타데이터를 바탕으로 참조 기반 질의와 ground-truth를 사용하여 모집단 환각률을 계산한다
- 두 가지 질의 paradigms를 적용한다: 참조 기반(ground-truth 답변) 및 참조 비 기반(대조 기반으로 GPT-4 판단)
- 네 가지 과제 범주(낮음, 중간, 높은 복잡도) 하에서 제로샷 및 소수샷 프롬프트로 세 가지 LLM(ChatGPT 3.5, PaLM 2, Llama 2)을 평가한다
- 참조 기반 과제의 ground-truth에 대한 잘못된 출력 비율로 환각률을 계산하고, 참조 비 기반의 대조를 통해 얻은 하한값으로 측정한다.
실험 결과
연구 질문
- RQ1사례에 관한 확인 가능한 법적 질문에 답할 때 LLM의 사실상(open-domain) 환각의 유병률은 어떠한가?
- RQ2과제의 복잡도, 법원 수준, 관할권, 사례의 두드러짐, 연도에 따라 서로 다른 LLM에서 환각률은 어떻게 달라지는가?
- RQ3LLMs는 contra-factual 편향에 취약한가, 그리고 법적 답변에 대한 자신의 확신을 신뢰성 있게 평가할 수 있는가?
- RQ4온도 설정이 높고 비-탐욕적(prompts) 프롬프트가 더 많은 모순을 만들어 사실이 아닌 출력으로 이어지는가?
주요 결과
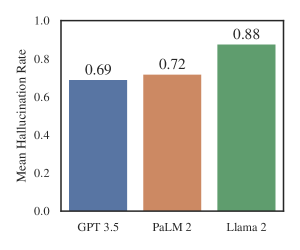
- 환각은 광범위하며, ChatGPT 3.5의 확인 가능한 연방 사건 질문에서 69%, Llama 2에서는 88%의 질의에서 관찰되었다.
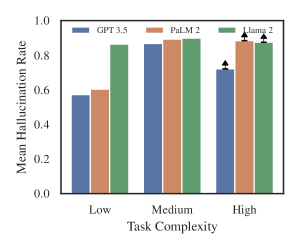
- 과제의 복잡도가 증가할수록 환각률이 상승하며, 새로운, 더 두드러지고 더 중요한 관할에서 더 낮다.
- 대조-factual 질문에 대해 LLM이 자주 잘못된 답을 제시하고 포스트-결정 재교정을 거치지 않으면 자신의 확신을 판단하기 어렵다.
- 참조 비 기반 방법은 환각률의 하한값을 제시하며, 핵심 법적 쟁점과 중심 판결과 같은 고복잡도 과제에서 비사실적 출력이 상당히 나타난다.
- 일반적으로 단순한 과제와 더 고품질이거나 더 두드러진 사례에서 성능이 더 우수하며, LLM의 법적 모노컬처 효과를 시사한다.
- 전반적으로 현재의 LLM은 필수적인 법적 과제에 대해 신뢰할 수 있는 판단을 제공하기 어렵고, 특히 프로 세 litigants와 같은 취약 사용자를 대상으로 사용할 때 주의가 필요하다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.