[논문 리뷰] Learning from models beyond fine-tuning
A comprehensive survey introducing the Learn From Model (LFM) paradigm, categorizing FM-based methods into model tuning, distillation, reuse, meta-learning, and editing, to enable learning from models rather than from data.
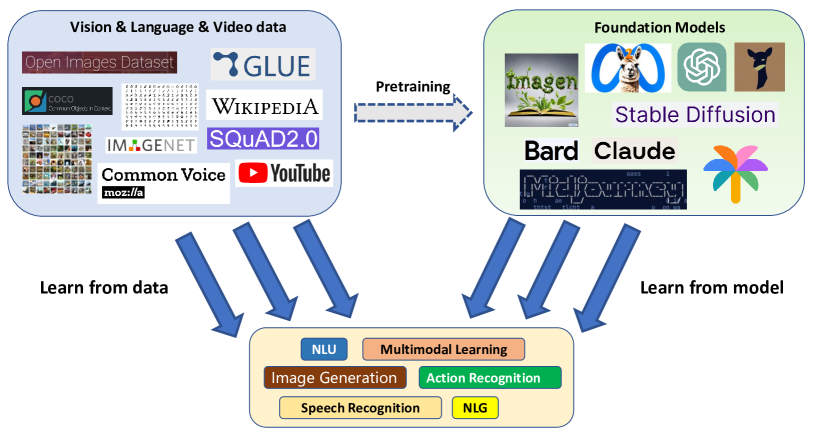
Foundation models (FM) have demonstrated remarkable performance across a wide range of tasks (especially in the fields of natural language processing and computer vision), primarily attributed to their ability to comprehend instructions and access extensive, high-quality data. This not only showcases their current effectiveness but also sets a promising trajectory towards the development of artificial general intelligence. Unfortunately, due to multiple constraints, the raw data of the model used for large model training are often inaccessible, so the use of end-to-end models for downstream tasks has become a new research trend, which we call Learn From Model (LFM) in this article. LFM focuses on the research, modification, and design of FM based on the model interface, so as to better understand the model structure and weights (in a black box environment), and to generalize the model to downstream tasks. The study of LFM techniques can be broadly categorized into five major areas: model tuning, model distillation, model reuse, meta learning and model editing. Each category encompasses a repertoire of methods and strategies that aim to enhance the capabilities and performance of FM. This paper gives a comprehensive review of the current methods based on FM from the perspective of LFM, in order to help readers better understand the current research status and ideas. To conclude, we summarize the survey by highlighting several critical areas for future exploration and addressing open issues that require further attention from the research community. The relevant papers we investigated in this article can be accessed at https://github.com/ruthless-man/Awesome-Learn-from-Model
연구 동기 및 목표
- Define the Learn From Model (LFM) paradigm and its motivation.
- Catalog and analyze FM-based methods under LFM across five areas (tuning, distillation, reuse, meta-learning, editing).
- Highlight advantages, limitations, and practical considerations of LFM for downstream tasks.
- Identify future directions and open issues in LFM to guide research and practice.
제안 방법
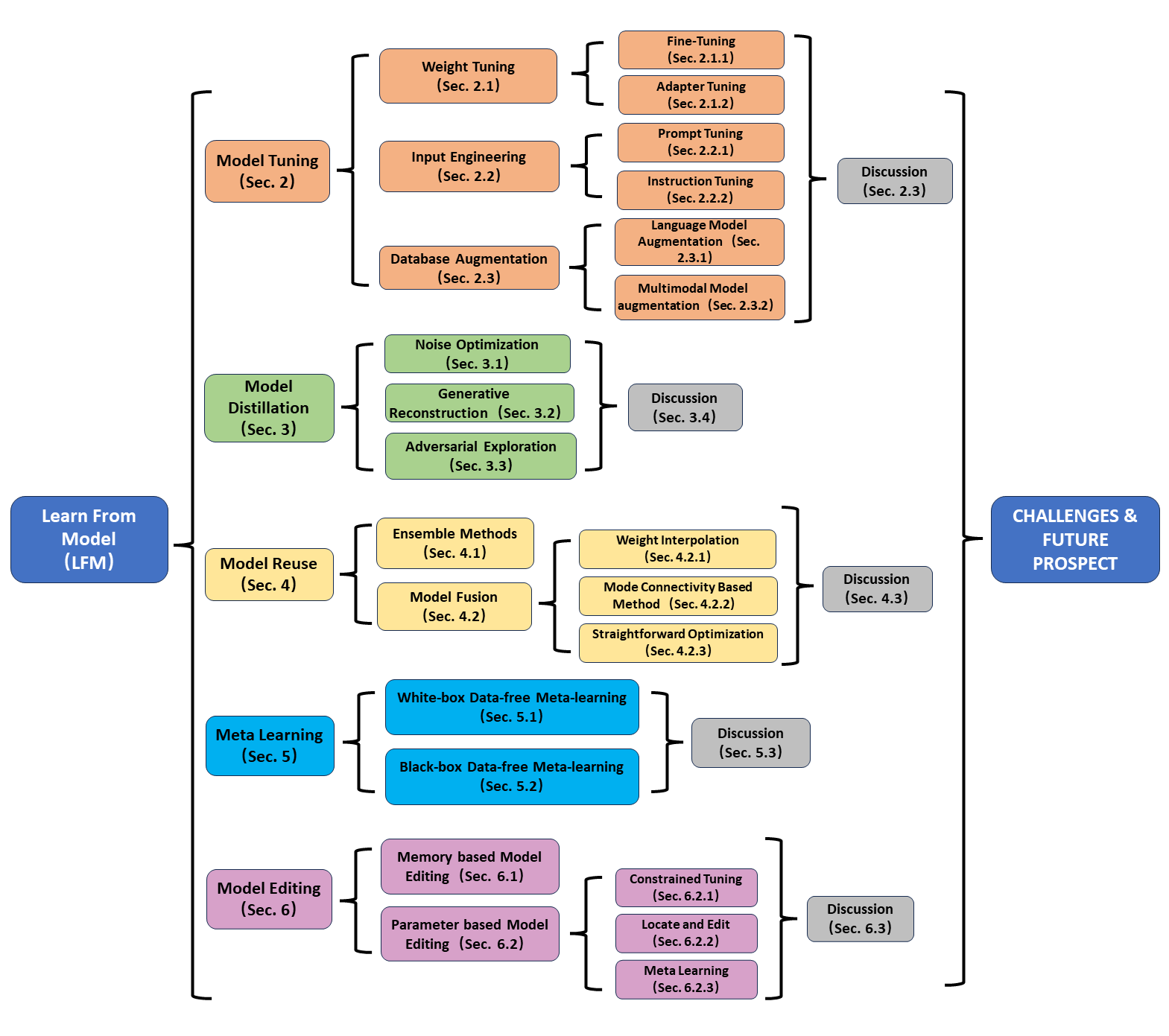
- Present a hierarchical taxonomy of LFM with five core areas: model tuning, model distillation, model reuse, meta-learning, and model editing.
- Summarize representative methods in each area (e.g., fine-tuning, adapters, prompt tuning, instruction tuning, retrieval/augmentation, data-free distillation, etc.).
- Contrast LFM with traditional learn-from-data, emphasizing data/privacy, cost, and knowledge transfer aspects.
- Discuss challenges such as data access limitations, computation, and model stability, and propose directions for loss design, memory-retrieval trade-offs, and tailored retrieval metrics.
- Synthesize a future-oriented outlook on LFM applications and open issues to spur further research.
실험 결과
연구 질문
- RQ1What constitutes Learn From Model and how does it differ from learning from data?
- RQ2What are the main categories of LFM methods and their respective trade-offs?
- RQ3What are the key open issues and future directions for LFM in foundation models?
주요 결과
- LFM offers a systematic framework to study foundation models via their interfaces, enabling adaptation with less data and computation than full retraining.
- The survey consolidates five LFM paradigms—model tuning, distillation, reuse, meta-learning, and editing—providing a comprehensive taxonomy and method overview.
- Adapter-based and prompt-based tuning can achieve competitive performance with fewer trainable parameters and reduced risk of overfitting.
- External knowledge via database augmentation and multimodal retrieval enhances model capabilities and up-to-date knowledge without full model retraining.
- The paper discusses future directions including loss function design, retrieval-memory vs. efficiency balance, and the need for tailored retrieval metrics.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.