[논문 리뷰] Learning gain differences between ChatGPT and human tutor generated algebra hints
본 연구는 ChatGPT가 생성한 대수 힌트와 인간 튜터가 제공한 힀트를 비교하여, 인간 힌트가 더 큰 학습 이득을 가져오고 약 30%의 ChatGPT 힌트가 품질 문제로 거부되었다고 밝혔습니다.
Large Language Models (LLMs), such as ChatGPT, are quickly advancing AI to the frontiers of practical consumer use and leading industries to re-evaluate how they allocate resources for content production. Authoring of open educational resources and hint content within adaptive tutoring systems is labor intensive. Should LLMs like ChatGPT produce educational content on par with human-authored content, the implications would be significant for further scaling of computer tutoring system approaches. In this paper, we conduct the first learning gain evaluation of ChatGPT by comparing the efficacy of its hints with hints authored by human tutors with 77 participants across two algebra topic areas, Elementary Algebra and Intermediate Algebra. We find that 70% of hints produced by ChatGPT passed our manual quality checks and that both human and ChatGPT conditions produced positive learning gains. However, gains were only statistically significant for human tutor created hints. Learning gains from human-created hints were substantially and statistically significantly higher than ChatGPT hints in both topic areas, though ChatGPT participants in the Intermediate Algebra experiment were near ceiling and not even with the control at pre-test. We discuss the limitations of our study and suggest several future directions for the field. Problem and hint content used in the experiment is provided for replicability.
연구 동기 및 목표
- ChatGPT가 생성한 힌트가 대수학에서 인간 튜터 힌트와 학습 이득 면에서 일치할 수 있는지 평가한다.
- 대수학 문제에 대한 ChatGPT 생성 힌트의 품질과 신뢰성을 평가한다.
- 향후 LLM 기반 튜터링 힌트를 위한 재현 가능한 콘텐츠 및 방법을 제공한다.
제안 방법
- 초등 및 중급 대수학 수업을 포함하는 2x2의 이원 대조 실험 설계.
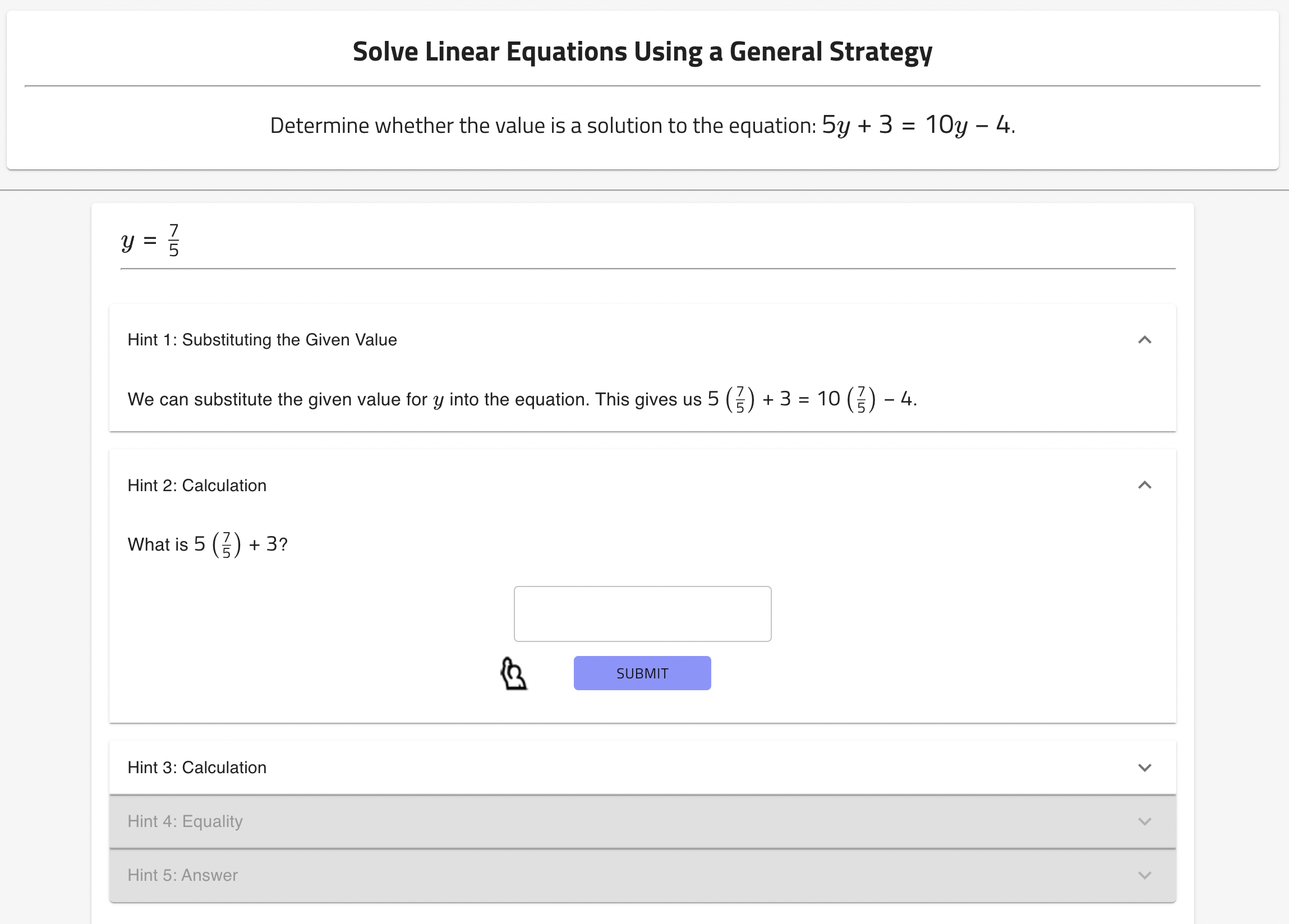
- OATutor 콘텐츠의 문제 프롬프트를 사용하여 2022년 12월 15일 모델로 생성된 ChatGPT-생성 힌트.
- OpenStax에서 파생된 콘텐츠를 활용한 대조 조건으로 수작업 인간 튜터 힌트를 사용.
- 참가자당 3항의 예비검사, 5항의 습득 단계, 3항의 사전/사후 검사를 실시(사전 및 사후에 동일한 항목).
- 품질 점검: 정답 여부, 올바른 풀이 과정 여부, 부적절한 언어 여부; 점검 중 하나라도 실패하면 실험에서 탈락.

실험 결과
연구 질문
- RQ1RQ1: ChatGPT가 낮은 품질의 힌트를 생성하는 경우가 얼마나 되는가?
- RQ2RQ2: ChatGPT 힌트가 학습 이득을 생성하는가?
- RQ3RQ3: 학습 이득 측면에서 ChatGPT 힌트와 인간 튜터 힌트의 차이가 있는가?
주요 결과
- 모든 조건에서 학습 이득이 나타났지만, 통계적으로 유의한 차이는 수동 힌트 조건에서만 관찰되었다.
- 초등 및 중급 대수학에서 인간 힌트가 ChatGPT 힌트보다 더 큰 학습 이득을 유도했다.
- 중급 대수학에서 ChatGPT 참가자는 사전 검사에서 이미 천장에 근접(약 80%)했고 사후 검사 이득과 유의하게 다르지 않았다; 대조군은 두 과목에서 사전 검사와 여전히 차이가 있었다.
- ChatGPT 힌트의 품질 문제로 30%의 거부율이 나타났다(정답 혹은 풀이 단계가 잘못됨).
- 소요 시간은 조건 간 비슷했으나, 품질 필터링된 응답으로 인해 ChatGPT는 힌트가 적게 필요했다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.