[논문 리뷰] Learning to Tokenize for Generative Retrieval
GenRet은 이산 자동인코딩을 통해 의미적 문서 식별자(docids)를 학습하여 엔드투엔드 생성 검색을 가능하게 하고, NQ320K에서 최첨단 성과를 달성하며 MS MARCO 및 BEIR에서 강력한 결과를 보인다.
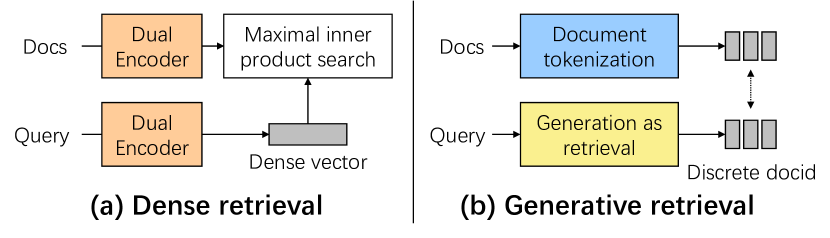
Conventional document retrieval techniques are mainly based on the index-retrieve paradigm. It is challenging to optimize pipelines based on this paradigm in an end-to-end manner. As an alternative, generative retrieval represents documents as identifiers (docid) and retrieves documents by generating docids, enabling end-to-end modeling of document retrieval tasks. However, it is an open question how one should define the document identifiers. Current approaches to the task of defining document identifiers rely on fixed rule-based docids, such as the title of a document or the result of clustering BERT embeddings, which often fail to capture the complete semantic information of a document. We propose GenRet, a document tokenization learning method to address the challenge of defining document identifiers for generative retrieval. GenRet learns to tokenize documents into short discrete representations (i.e., docids) via a discrete auto-encoding approach. Three components are included in GenRet: (i) a tokenization model that produces docids for documents; (ii) a reconstruction model that learns to reconstruct a document based on a docid; and (iii) a sequence-to-sequence retrieval model that generates relevant document identifiers directly for a designated query. By using an auto-encoding framework, GenRet learns semantic docids in a fully end-to-end manner. We also develop a progressive training scheme to capture the autoregressive nature of docids and to stabilize training. We conduct experiments on the NQ320K, MS MARCO, and BEIR datasets to assess the effectiveness of GenRet. GenRet establishes the new state-of-the-art on the NQ320K dataset. Especially, compared to generative retrieval baselines, GenRet can achieve significant improvements on the unseen documents. GenRet also outperforms comparable baselines on MS MARCO and BEIR, demonstrating the method's generalizability.
연구 동기 및 목표
- 전통적인 인덱스-검색 파이프라인을 넘어서는 엔드투엔드 문서 검색의 동기를 부여한다.
- 고정된 규칙 기반 토크나이저를 넘어서는 생성적 검색을 위한 문서 식별자 정의의 도전을 다룬다.
- 문서의 의미를 보존하는 이산 자동 인코딩 토크나이제이션 프레임워크를 제안한다.
- 토큰화, 재구성, 검색 구성요소의 엔드투엔드 최적화를 가능하게 한다.
- NQ320K, MS MARCO, BEIR를 포함한 다양한 데이터셋에서 일반화 가능성을 입증한다.
제안 방법
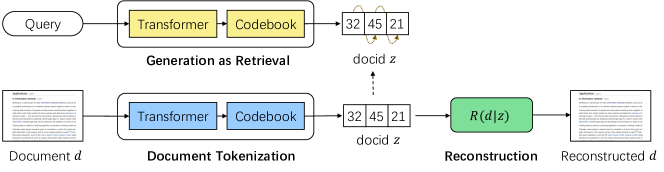
- 세 가지 구성요소를 가진 GenRet를 도입한다: 문서를 docids로 매핑하는 토크나이제이션 모델 Q, docids에서 원문서를 재생성하는 재구성 모델 R, 쿼리에서 docids를 생성하는 검색 모델 P.
- 토크나이제이션과 검색에 대해 T5 기반의 공유 아키텍처를 사용하고 시간 단계마다 크기 K인 이산 잠재 코드북(K=512)을 도입한다.
- 재구성 손실, 약속 손실, 검색 손실로 구성된 재구성 대 약속 목표를 포함하는 자동 인코딩 objective로 docids를 문서 의미와 쿼리 기반 검색에 맞춘다.
- prior 접두사를 고정하면서 docids를 자기회귀적으로 최적화하는 점진적 학습 스킴을 채택하여 학습의 안정화를 도모한다.
- 코드북 초기화 및 Sinkhorn-Knopp를 통한 docid 재할당과 같은 다양한 클러스터링 기법을 도입하여 docid 다양성과 의미 공간의 균형 있는 분할을 촉진한다.
- 생성된 docids가 말뭉치 내에서 유효하도록 제약된 디코딩을 적용하고 검색을 위해 빔 검색을 사용한다.
실험 결과
연구 질문
- RQ1학습된 이산 토큰화인 문서(docids)가 생성적 검색을 위한 고정 규칙 기반 토큰보다 의미 정보를 더 효과적으로 포착할 수 있는가?
- RQ2토큰화, 재구성, 검색의 엔드투엔드 학습이 특히 보지 못한 문서에서 검색 성능을 개선하는가?
- RQ3자기회귀적 docid 생성을 안정시키고 정확성을 희생하지 않으면서 docid 할당의 다양성을 촉진하려면 어떻게 해야 하는가?
- RQ4GenRet의 학습된 docids가 학습 분포를 넘어 다양한 데이터셋(MS MARCO와 BEIR)으로 일반화되는가?
주요 결과
- GenRet은 NQ320K에서 새로운 최첨단 성과를 달성하며 보지 못한 테스트 데이터에서의 상대적 개선이 커진다(+best generative baselines 대비 R@1에서 +14%).
- GenRet은 MS MARCO와 BEIR에서 기존의 생성적 검색 베이스라인을 능가하며 강한 일반화 능력을 보여준다.
- 자동 인코딩 토크나이제이션 프레임워크는 문서의 의미를 재구성 가능하게 하는 의미론적으로 의미있는 docids를 생성하는 데 도움을 주고, 학습 중 보지 못한 문서의 검색을 개선한다.
- 점진적 학습과 다양한 docid 클러스터링은 학습의 안정성과 docid 다양성을 증가시키며 자기회귀 학습 및 토큰 할당의 문제를 해소한다.
- 규칙 기반 토크나이저와 비교할 때 GenRet은 보지 못한 문서를 더 잘 표현하고 검색하며, 분포 외 데이터에 대한 강건성을 보인다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.