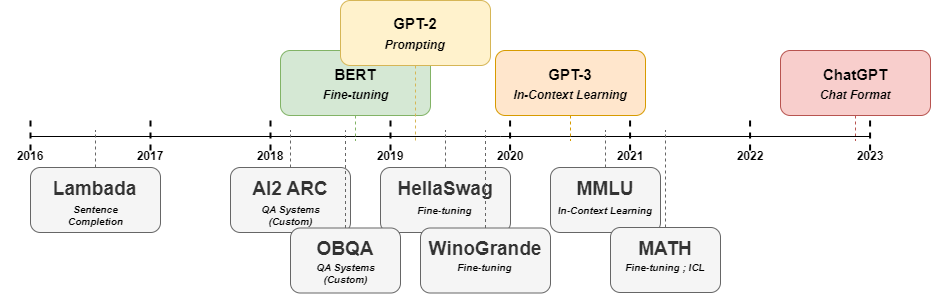
[논문 리뷰] Lessons from the Trenches on Reproducible Evaluation of Language Models
강력하고 재현 가능한 언어 모델 평가를 위한 모범 사례를 제공하고, 언어 모델 평가 허브 lm-eval를 소개하여 작업 및 모델 전반의 평가를 오케스트레이션, 재현, 확장할 수 있게 한다.
Effective evaluation of language models remains an open challenge in NLP. Researchers and engineers face methodological issues such as the sensitivity of models to evaluation setup, difficulty of proper comparisons across methods, and the lack of reproducibility and transparency. In this paper we draw on three years of experience in evaluating large language models to provide guidance and lessons for researchers. First, we provide an overview of common challenges faced in language model evaluation. Second, we delineate best practices for addressing or lessening the impact of these challenges on research. Third, we present the Language Model Evaluation Harness (lm-eval): an open source library for independent, reproducible, and extensible evaluation of language models that seeks to address these issues. We describe the features of the library as well as case studies in which the library has been used to alleviate these methodological concerns.
연구 동기 및 목표
- Identify common challenges in evaluating large language models (accuracy vs. semantic equivalence, benchmark validity, implementation reproducibility).
- Propose best practices to improve rigor and transparency in LM evaluation (prompts, outputs, uncertainty, and qualitative analysis).
- Describe the design and capabilities of the Language Model Evaluation Harness (lm-eval) to enable reproducible, extensible evaluations.
제안 방법
- Outline the Key Problem: semantic equivalence vs. syntactic variation in model outputs and the limits of human vs. automated scoring.
- Discuss best practices for evaluation reporting, including sharing exact prompts, avoiding cross-paper result copying, providing model outputs, qualitative analyses, and uncertainty measurement.
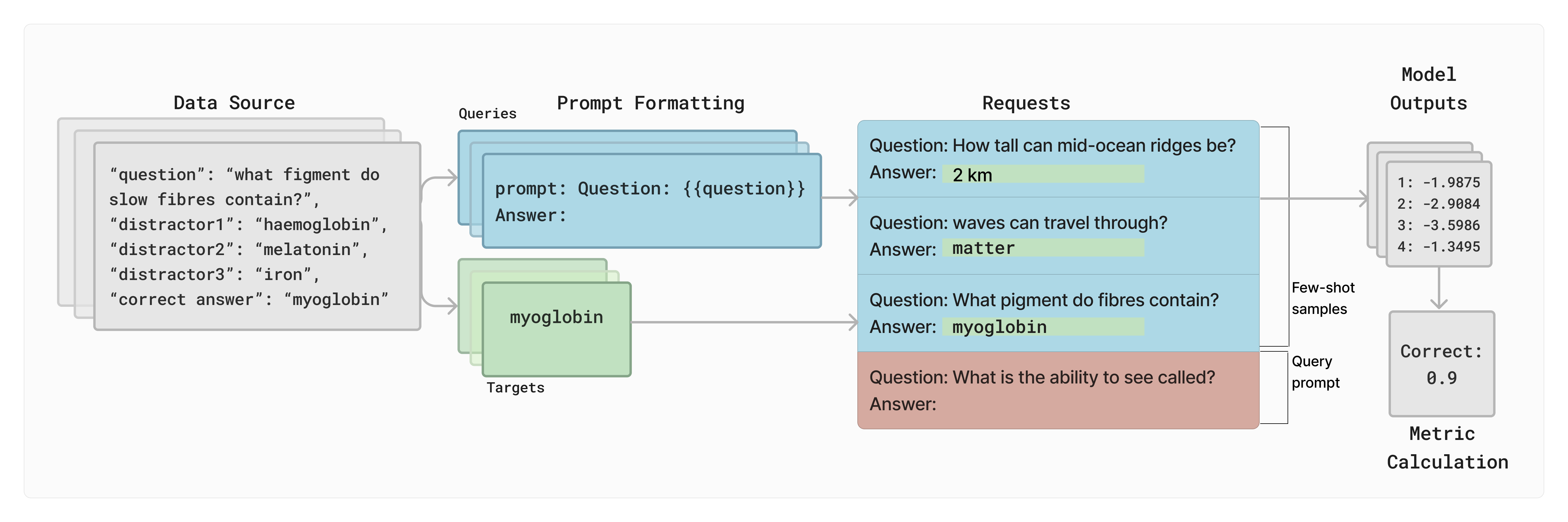
- Present the architecture and interfaces of lm-eval, including Task classes, LM API, and three core Request types (conditional loglikelihoods, perplexities, and generation).
- Explain how lm-eval enforces reproducibility via versioned tasks and standardized evaluation workflows.
- Provide case studies (BigScience prompts distributions; evaluation setup sensitivity) demonstrating lm-eval’s ability to reveal evaluation robustness and prompting effects.
실험 결과
연구 질문
- RQ1How do evaluation setup choices affect language model performance metrics across benchmarks?
- RQ2What best practices can mitigate evaluation biases and improve reproducibility in LM benchmarking?
- RQ3How can an orchestration library like lm-eval streamline fair, extensible, and transparent LM evaluation across models and tasks?
주요 결과
| 모델 | ARC Cloze (0-shot) | ARC MMLU-style (0-shot) | MMLU-style (0-shot) | Hybrid (MMLU-style prompts with answer strings) |
|---|---|---|---|---|
| GPT-NeoX-20B | 38.0±2.78% | 26.6±2.53% | 24.5±0.71% | 27.6±0.74% |
| Llama-2-7B | 43.5±2.84% | 42.8±2.83% | 41.3±0.80% | 39.8±0.79% |
| Falcon-7B | 40.2±2.81% | 25.9±2.51% | 25.4±0.72% | 29.1±0.75% |
| Mistral-7B | 50.1±2.86% | 72.4±2.56% | 58.6±0.77% | 48.3±0.80% |
| Mixtral-8x7B | 56.7±2.84% | 81.3±2.23% | 67.1±0.72% | 59.7±0.77% |
- Evaluation results are highly sensitive to prompts and evaluation setup, necessitating standardized, reproducible tooling.
- Sharing exact prompts, code, and model outputs significantly improves reproducibility and enables fair comparisons.
- lm-eval provides a modular, extensible framework with task abstractions and a simple LM interface to unify evaluation across benchmarks.
- Promoting qualitative analysis and uncertainty reporting (standard errors, bootstrapping) improves interpretability of scores.
- Case studies show that prompt distributions and evaluation methodology substantially impact reported results, underscoring the need for robust evaluation ecosystems.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.