[논문 리뷰] Many-Shot In-Context Learning
본 논문은 대형 언어 모델이 컨텍스트 내 예시의 규모에 따라 어떻게 확장되는지 조사하고, 인간 시연에 대한 의존성을 줄이기 위해 Reinforced ICL과 Unsupervised ICL을 도입하며, 많은-샷 ICL이 사전 학습 편향을 극복하고 비자연어 작업까지 다룰 수 있음을 보여준다.
Large language models (LLMs) excel at few-shot in-context learning (ICL) -- learning from a few examples provided in context at inference, without any weight updates. Newly expanded context windows allow us to investigate ICL with hundreds or thousands of examples -- the many-shot regime. Going from few-shot to many-shot, we observe significant performance gains across a wide variety of generative and discriminative tasks. While promising, many-shot ICL can be bottlenecked by the available amount of human-generated examples. To mitigate this limitation, we explore two new settings: Reinforced and Unsupervised ICL. Reinforced ICL uses model-generated chain-of-thought rationales in place of human examples. Unsupervised ICL removes rationales from the prompt altogether, and prompts the model only with domain-specific questions. We find that both Reinforced and Unsupervised ICL can be quite effective in the many-shot regime, particularly on complex reasoning tasks. Finally, we demonstrate that, unlike few-shot learning, many-shot learning is effective at overriding pretraining biases, can learn high-dimensional functions with numerical inputs, and performs comparably to fine-tuning. We also find that inference cost increases linearly in the many-shot regime, and frontier LLMs benefit from many-shot ICL to varying degrees. Our analysis also reveals the limitations of next-token prediction loss as an indicator of downstream ICL performance.
연구 동기 및 목표
- 다양한 작업에서 컨텍스트 내 예시(샷) 수의 증가가 LLM 성능에 어떤 영향을 미치는지 평가한다.
- many-shot ICL에서 인간이 생성한 합리화에 대한 의존도를 줄이는 방법을 개발한다.
- 편향 재현, 비자연어 작업 및 프롬프트 순서 효과를 포함한 ICL의 학습 동역학을 분석한다.
제안 방법
- Gemini 1.5 Pro를 사용해 최대 8192 샷까지 다양한 작업에서 컨텍스트 예시를 체계적으로 확장한다.
- MT, 요약, 계획, 코드 검증 등의 작업에서 few-shot와 many-shot ICL을 비교한다.
- 답변 정답 여부로 필터링된 모델 생성 합리화를 사용해 Reinforced ICL을 도입한다.
- 합리화 없이 문제만으로 프롬프트하는 Unsupervised ICL을 도입한다.
- 편향 극복, 고차원 수치 과제, NLL과 ICL 성능 간의 관계 등 ICL 동향을 분석한다.
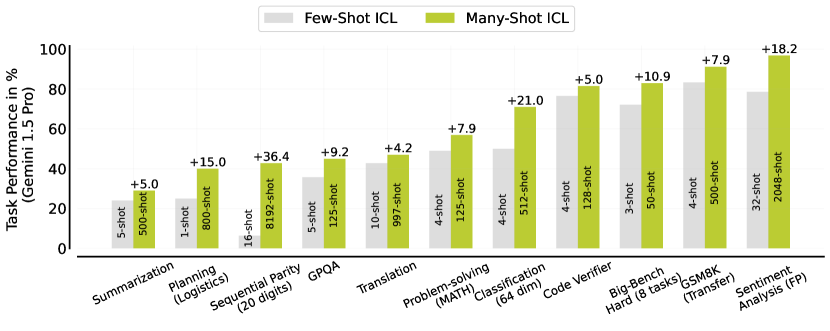
실험 결과
연구 질문
- RQ1다양한 작업 세트에서 many-shot ICL 성능이 few-shot ICL에 비해 어떻게 확장되는가?
- RQ2모델 생성 합리화(Reinforced ICL) 또는 문제만 프롬프트(Unsupervised ICL)가 많은-shot 설정에서 인간 시연과 일치하거나 이를 능가할 수 있는가?
- RQ3많은-shot ICL이 사전 학습 편향을 극복하고 비자연어 또는 수치적 작업 학습을 가능하게 하는가?
- RQ4다음 토큰 예측 손실을 ICL 성공의 예측자로 삼는 데 어떤 한계가 있는가?
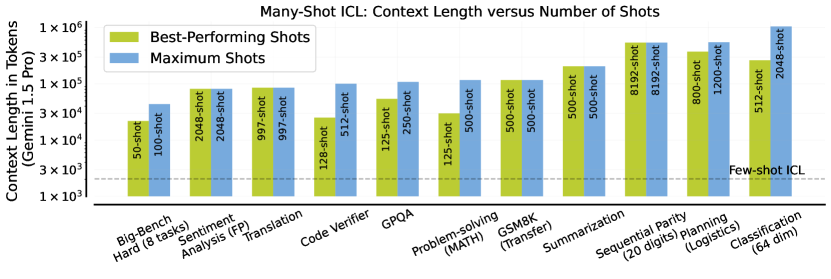
- RQ5many-shot ICL은 예시 순서와 맥락 길이에 얼마나 민감한가?
주요 결과
- Many-shot ICL은 다양한 작업에서 상당한 성능 향상을 제공하며, 샷이 수백에서 수천 토큰에 이를 때 성능이 정점에 도달하는 경우가 많다.
- Reinforced ICL과 Unsupervised ICL은 많은 설정에서 인간이 작성한 합리화를 능가하거나 일치할 수 있으며, 특히 복잡한 추론 작업에서 그렇다.
- Many-shot ICL은 사전 학습 편향을 극복하고 연속 패리티 및 선형 분류와 같은 고차원 수치 작업을 학습할 수 있다.
- 컨텍스트 예시의 순서는 many-shot ICL에서도 성능에 상당한 영향을 미친다.
- 다음 토큰 예측 손실은 문제 해결 및 추론 작업에서 다운스트림 ICL 성능을 신뢰성 있게 예측하지 못할 수 있다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.