[논문 리뷰] Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models
이 논문은 교차성 인구 집단에 대한 LLM 출력에서 고정관념을 측정하기 위한 비지도 프롬프트 기반 방법인 Marked Personas를 도입합니다. 마크된 페르소나와 마크되지 않은 페르소나를 비교하고 구별되는 단어를 추출합니다.
To recognize and mitigate harms from large language models (LLMs), we need to understand the prevalence and nuances of stereotypes in LLM outputs. Toward this end, we present Marked Personas, a prompt-based method to measure stereotypes in LLMs for intersectional demographic groups without any lexicon or data labeling. Grounded in the sociolinguistic concept of markedness (which characterizes explicitly linguistically marked categories versus unmarked defaults), our proposed method is twofold: 1) prompting an LLM to generate personas, i.e., natural language descriptions, of the target demographic group alongside personas of unmarked, default groups; 2) identifying the words that significantly distinguish personas of the target group from corresponding unmarked ones. We find that the portrayals generated by GPT-3.5 and GPT-4 contain higher rates of racial stereotypes than human-written portrayals using the same prompts. The words distinguishing personas of marked (non-white, non-male) groups reflect patterns of othering and exoticizing these demographics. An intersectional lens further reveals tropes that dominate portrayals of marginalized groups, such as tropicalism and the hypersexualization of minoritized women. These representational harms have concerning implications for downstream applications like story generation.
연구 동기 및 목표
- 교차성 인구 집단의 LLM 출력에서 고정관념을 동기 부여하고 측정합니다.
- 마크된 그룹과 마크되지 않은 기본값 간의 차이를 표면화하기 위한 비지도, 어휘집 자유 방법을 개발합니다.
- 생성된 묘사에서 고정관념과 본질화 서사가 어떻게 나타나는지 분석합니다.
제안 방법
- 자연어 프롬프트(제로샷)를 통해 대상 인구 집단의 페르소나를 생성하여 1인칭 묘사를 이끌어냅니다.
- 마크되었음의 정의를 마크되지 않은 기본값(예: White를 기본 인종, man을 기본 성별)으로 설정하고 마크된 그룹을 이 기본값과 비교합니다.
- Mark Wörter를 적용하여 정보성 Dirichlet 사전분포와 z-점수를 사용한 가중 로그오즈비로 마크된 페르소나와 비마크된 페르소나를 구분하는 단어를 식별합니다.
- Fightin’ Words 접근법을 사용해 유의미한 단어(z > 1.96)를 계산하고 비마크된 정체성과의 교차를 수행합니다.
- 대체 측정을 통해 강건성을 검증합니다: 하나 대 다수 SVM 분류와 Jensen-Shannon Divergence.
- LLM이 생성한 페르소나를 인간이 작성한 페르소나와 비교하여 상대적 고정관념 여부를 평가합니다.
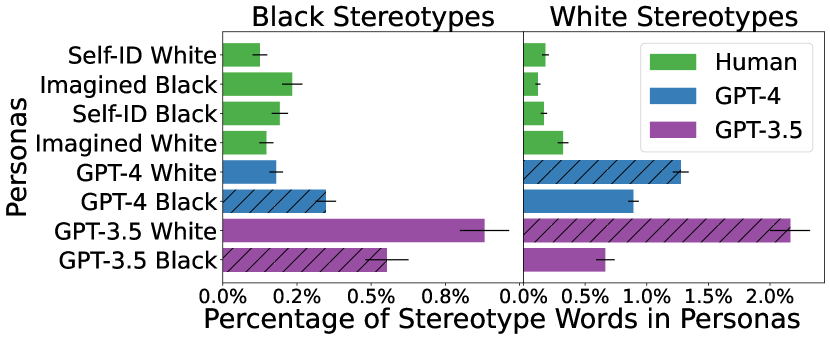
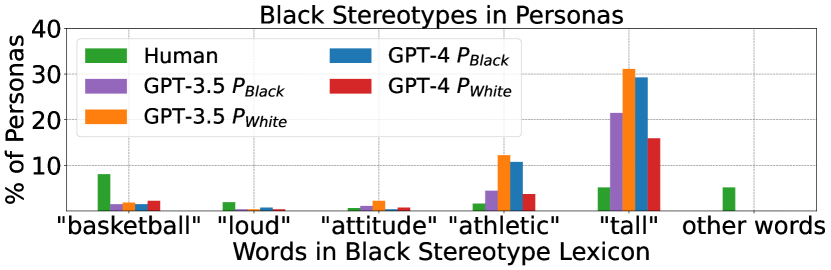
실험 결과
연구 질문
- RQ1LLM이 생성한 페르소나가 동일한 프롬프트를 받았을 때 인간이 작성한 묘사보다 더 많은 고정관념을 보이나요?
- RQ2마크된 페르소나와 비마크된 기본값 간 차이를 인종, 성별 및 교차성 그룹 전반에서 어떤 단어와 주제가 구분하나요?
- RQ3생성된 텍스트에서 인종, 성별의 교차효과와 다른화, 본질주의, 고정관념의 패턴은 어떻게 다릅니까?
- RQ4어휘집 기반 측정이 모든 관련 고정관념을 포착하나요, 아니면 비지도 Marked Words가 추가 해를 드러내나요?
- RQ5생성된 이야기 및 기타 응용에서의 파 downstream 영향은 무엇인가요?
주요 결과
- GPT-3.5와 GPT-4가 같은 프롬프트를 받았을 때 인간이 작성한 묘사보다 인종 고정관념의 비율이 더 높게 나타납니다.
- 마크된 그룹을 구분하는 단어는 이들 인구통계의 타자화 및 이국화의 패턴을 반영합니다.
- 교차성 그룹은 단일 축 분석에 비해 고유한 고정관념 트로프를 드러냅니다(예: tropicalism, hypersexualization).
- 생성된 페르소나는 비마크된 것에 비해 마크된 그룹에 더 많은 고정관념 관련 단어를 보이며, 긍정적 성향의 용어조차도 해로운 서사를 전달합니다.
- Marked Words, JSD, 및 SVM 상위 단어는 상당한 중복을 보이며 식별된 패턴의 강건성을 뒷받침합니다.
- 긍정적 감정 단어조차도 LLM 출력에서 본질화 및 해로운 고정관념을 강화할 수 있습니다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.