[논문 리뷰] MixFormerV2: Efficient Fully Transformer Tracking
MixFormerV2는 예측 토큰과 distillation 기반의 모델 축소를 사용한 완전 트랜스포머 추적 프레임워크를 도입하여 GPU 및 CPU에서 실시간 속도로 높은 정확도를 달성합니다.
Transformer-based trackers have achieved strong accuracy on the standard benchmarks. However, their efficiency remains an obstacle to practical deployment on both GPU and CPU platforms. In this paper, to overcome this issue, we propose a fully transformer tracking framework, coined as \emph{MixFormerV2}, without any dense convolutional operation and complex score prediction module. Our key design is to introduce four special prediction tokens and concatenate them with the tokens from target template and search areas. Then, we apply the unified transformer backbone on these mixed token sequence. These prediction tokens are able to capture the complex correlation between target template and search area via mixed attentions. Based on them, we can easily predict the tracking box and estimate its confidence score through simple MLP heads. To further improve the efficiency of MixFormerV2, we present a new distillation-based model reduction paradigm, including dense-to-sparse distillation and deep-to-shallow distillation. The former one aims to transfer knowledge from the dense-head based MixViT to our fully transformer tracker, while the latter one is used to prune some layers of the backbone. We instantiate two types of MixForemrV2, where the MixFormerV2-B achieves an AUC of 70.6\% on LaSOT and an AUC of 57.4\% on TNL2k with a high GPU speed of 165 FPS, and the MixFormerV2-S surpasses FEAR-L by 2.7\% AUC on LaSOT with a real-time CPU speed.
연구 동기 및 목표
- 실시간 배포에 적합한 트랜스포머 기반 방법으로 효율적인 시각 객체 추적의 필요성을 제시한다.
- Dense convolution이나 복잡한 스코어 헤드 없이 완전한 트랜스포머 추적 프레임워크를 제안한다.
- 타깃-템플릿과 검색 영역 간의 상관관계를 포착하기 위해 예측 토큰을 도입한다.
- 효율성을 높이기 위한 distillation 기반 모델 축소(dense-to-sparse 및 deep-to-shallow)를 개발한다.
- 표준 추적 벤치마크에서 강력한 정확도-속도 트레이드오프를 입증한다.
제안 방법
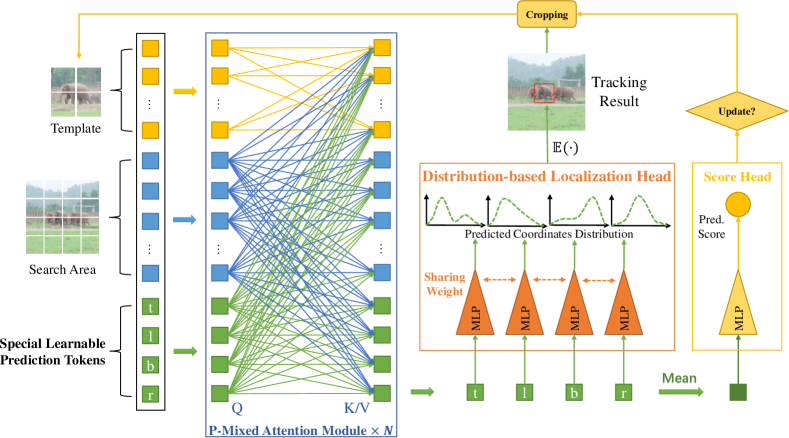
- 템플릿 토큰과 검색 토큰을 연결하여 혼합 토큰 시퀀스를 형성하기 위해 네 개의 학습 가능한 예측 토큰을 사용한다.
- 타깃-검색 상관관계를 인코딩하기 위해 예측 토큰이 포함된 혼합 어텐션(P-MAM)을 적용한다.
- 예측 토큰에 공유된 MLP 헤드를 통해 네 개의 박스 좌표를 직접 회귀한다(분포 기반 회귀).
- 예측 토큰을 평균화하여 간단한 MLP 헤드로 타깃 품질 점수를 예측한다.
- dense-head MixViT에서 MixFormerV2로의 dense-to-sparse 증류를 수행하여 로케이션 지식을 전달한다.
- 진보된 깊이 가지치기와 중간 교사를 활용한 deep-to-shallow distillation으로 백본을 가지치하되 전달 가능성을 보존한다.
- CPU/GPU 지연 시간을 줄이기 위한 MLP 차원 축소(MLP-r)를 포함한다.
- 박스 회귀, CIoU, 로짓 증류, 특징 모방을 결합한 distillation 손실로 학습한다.
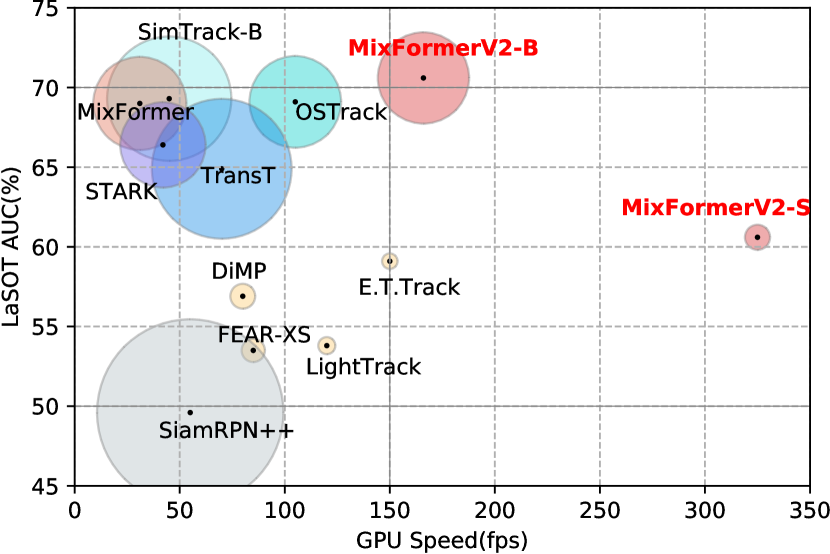
실험 결과
연구 질문
- RQ1Dense convolution 없이도 완전 트랜스포머 추적 모델이 경쟁력 있는 정확도와 더 높은 효율성을 달성할 수 있을까?
- RQ2예측 토큰과 토큰 기반 회귀가 로컬라이제이션 정확도와 추론 속도에 어떤 영향을 미치는가?
- RQ3지식 증류(dense-to-sparse 및 deep-to-shallow)가 더 가벼운 MixFormerV2의 성능을 향상시킬 수 있는가?
- RQ4중간 교사와 MLP 감소가 CPU 실시간 성능에 미치는 영향은 무엇인가?
주요 결과
- MixFormerV2-B는 LaSOT에서 70.6% AUC를 달성하고 GPU에서 165 FPS를 기록했다.
- MixFormerV2-S는 CPU 실시간 속도를 달성하면서도 LaSOT에서 경쟁력 있는 성능을 유지한다.
- 네 개 토큰으로 구성된 예측 토큰 기반 분포 회귀는 직접 단일 토큰 회귀를 능가하고 속도-정확도 트레이드오프에서 밀집한 코너 헤드와 동일하거나 더 우수하다.
- MixViT의 dense-to-sparse 증류는 교사에 따라 MixFormerV2 정확도를 약 1.4–2.2% AUC만큼 향상시킨다.
- 진보적 깊이 가지치기가 포함된 deep-to-shallow 증류는 백본 깊이를 줄이면서도 대부분의 정확도를 보존한다(예: 12-layer에서 8-layer, 4-layer 워크플로우로).
- 중간 교사는 매우 얕은 모델(예: 4-layer)의 증류에 도움이 되어 추가 이점을 제공한다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.