[논문 리뷰] Multi-Objective Loss Balancing for Physics-Informed Deep Learning
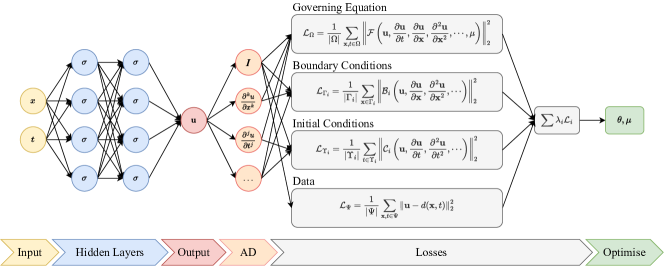
본 논문은 Physics-Informed Neural Networks (PINNs)에서 다중 손실 항의 균형을 맞추는 방법을 분석하고, 기존의 loss-scaling 접근법보다 정확성과 효율성을 향상시키기 위한 새로운 자가 적응형 방법인 ReLoBRaLo를 도입한다. Burgers’, Kirchhoff, Helmholtz 편 PDE를 대상으로 순방향 및 역방향 문제를 평가한다.
Physics-Informed Neural Networks (PINN) are algorithms from deep learning leveraging physical laws by including partial differential equations together with a respective set of boundary and initial conditions as penalty terms into their loss function. In this work, we observe the significant role of correctly weighting the combination of multiple competitive loss functions for training PINNs effectively. To this end, we implement and evaluate different methods aiming at balancing the contributions of multiple terms of the PINNs loss function and their gradients. After reviewing of three existing loss scaling approaches (Learning Rate Annealing, GradNorm and SoftAdapt), we propose a novel self-adaptive loss balancing scheme for PINNs named \emph{ReLoBRaLo} (Relative Loss Balancing with Random Lookback). We extensively evaluate the performance of the aforementioned balancing schemes by solving both forward as well as inverse problems on three benchmark PDEs for PINNs: Burgers' equation, Kirchhoff's plate bending equation and Helmholtz's equation. The results show that ReLoBRaLo is able to consistently outperform the baseline of existing scaling methods in terms of accuracy, while also inducing significantly less computational overhead.
연구 동기 및 목표
- PINNs에서 물리 법칙으로 인해 발생하는 다중 손실 항의 균형 필요성에 대한 동기를 부여합니다.
- 기존 손실 균형 스킴을 평가하고 그 한계를 파악합니다.
- 새로운 자가 적응형 손실 균형 방법(ReLoBRaLo)을 제안하고 검증합니다.
- 다중 PDE에 걸친 forward 및 inverse PINN 문제에서 성능 향상을 보여줍니다.
제안 방법
- 기존의 loss-scaling 방법들(LRAnnealing, GradNorm, SoftAdapt)과 그 한계를 검토합니다.
- 상대 손실 진행과 무작위 회고(random lookback, saudade)를 사용하는 자가 적응형 손실 균형 체계인 ReLoBRaLo를 도출하고 제시합니다.
- 경계된 softmax 스케일된 계수 집합을 통해 다중 PINN 손실 항의 균형을 맞춥니다.
- 네트워크 아키텍처와 학습 설정의 하이퍼파라미터 튜닝을 위해 베이지안 최적화와 그리드 탐색을 사용합니다.
- Burgers’, Kirchhoff plate bending, Helmholtz 방정식에 대한 forward 및 inverse 문제에서 평가합니다.
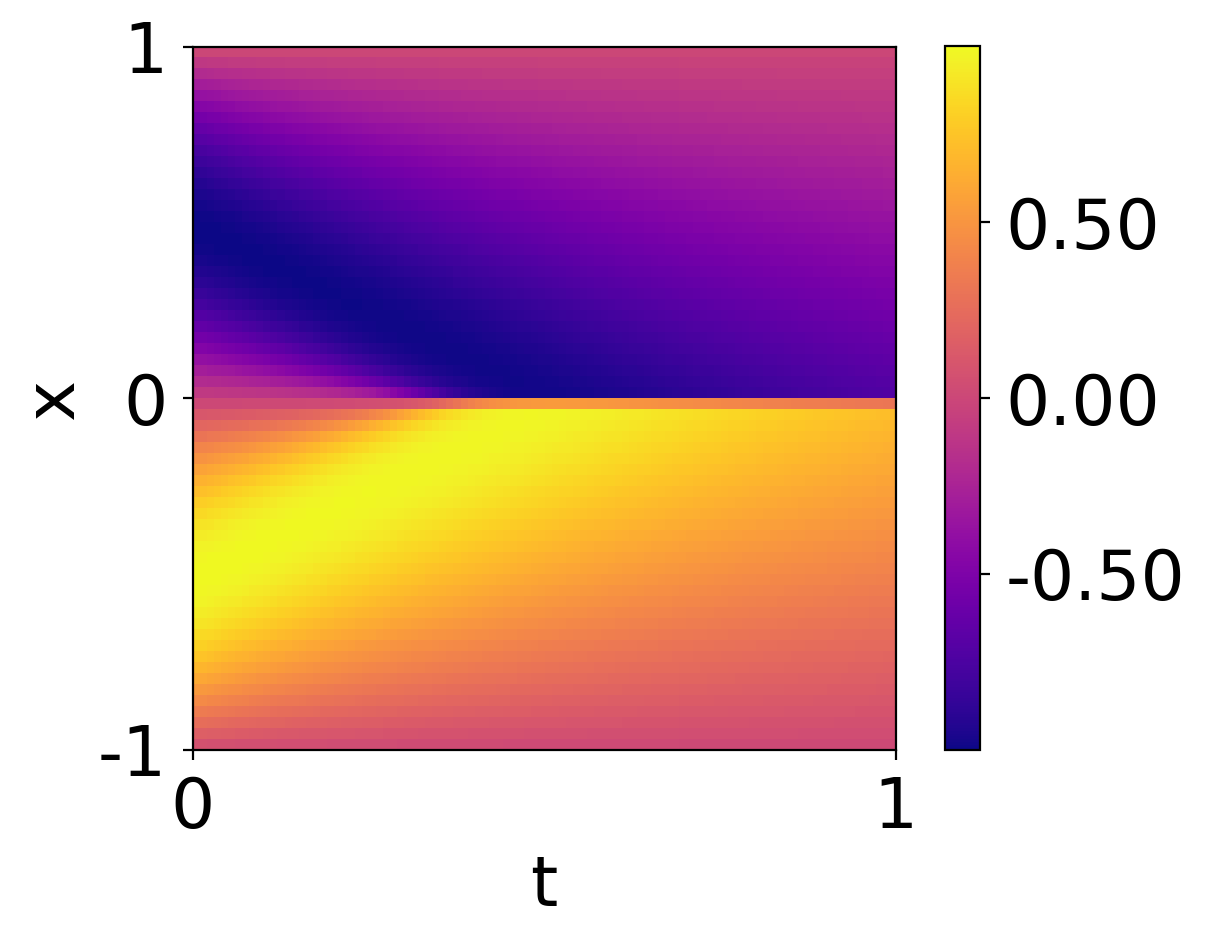
실험 결과
연구 질문
- RQ1다양한 손실 균형 스킴이 forward 및 inverse 문제에서 PINN 학습의 안정성과 정확도에 어떤 영향을 미치는가?
- RQ2다중 항 손실이 있는 PINN에서 자가 적응형 손실 균형 방법이 기존 접근법보다 우수한 성능을 보일 수 있는가?
- RQ3손실 항 스케일링이 Burgers’, Kirchhoff, Helmholtz PDE들의 계산 효율성과 수렴성에 미치는 영향은 무엇인가?
- RQ4PINNs에서 적응형 손실 균형의 성능을 극대화하기 위해 하이퍼파라미터를 어떻게 튜닝해야 하는가?
주요 결과
- ReLoBRaLo는 정확도 면에서 일관되게 기본 손실 스케일링 방법들을 상회한다.
- ReLoBRaLo는 일부 기존 방법에 비해 계산 오버헤드를 상당히 줄인다.
- 해당 방법은 경계된 softmax, 상대 손실 진행, 그리고 무작위 회고를 사용하여 학습 안정화를 도모한다.
- 실험은 Burgers’, Kirchhoff plate bending, Helmholtz 방정식에 대한 forward 및 inverse PINN 문제를 다룬다.
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.