[논문 리뷰] Noise2Music: Text-conditioned Music Generation with Diffusion Models
Noise2Music은 24 kHz로 텍스트 조건 음악을 생성하기 위해 계단식 디퓨전 모델을 훈련하며, 중간 표현으로 스펙트로그램 또는 저충실도 파형을 사용하고, 의미 일치를 위한 대형 언어 모델 바인딩을 활용합니다.
We introduce Noise2Music, where a series of diffusion models is trained to generate high-quality 30-second music clips from text prompts. Two types of diffusion models, a generator model, which generates an intermediate representation conditioned on text, and a cascader model, which generates high-fidelity audio conditioned on the intermediate representation and possibly the text, are trained and utilized in succession to generate high-fidelity music. We explore two options for the intermediate representation, one using a spectrogram and the other using audio with lower fidelity. We find that the generated audio is not only able to faithfully reflect key elements of the text prompt such as genre, tempo, instruments, mood, and era, but goes beyond to ground fine-grained semantics of the prompt. Pretrained large language models play a key role in this story -- they are used to generate paired text for the audio of the training set and to extract embeddings of the text prompts ingested by the diffusion models. Generated examples: https://google-research.github.io/noise2music
연구 동기 및 목표
- 대규모의 고품질 텍스트 조건 음악 생성을 위한 동기 부여 및 가능성 확보.
- 자유 형식 텍스트 프롬프트로 조건화된 30초 음악을 생성하는 디퓨전 기반 파이프라인 개발.
- 오디오의 세밀한 의미 속성을 근거 짓기 위해 대형 언어 모델과 음악-텍스트 임베딩을 활용하여 정교한 의미 속성 매핑.
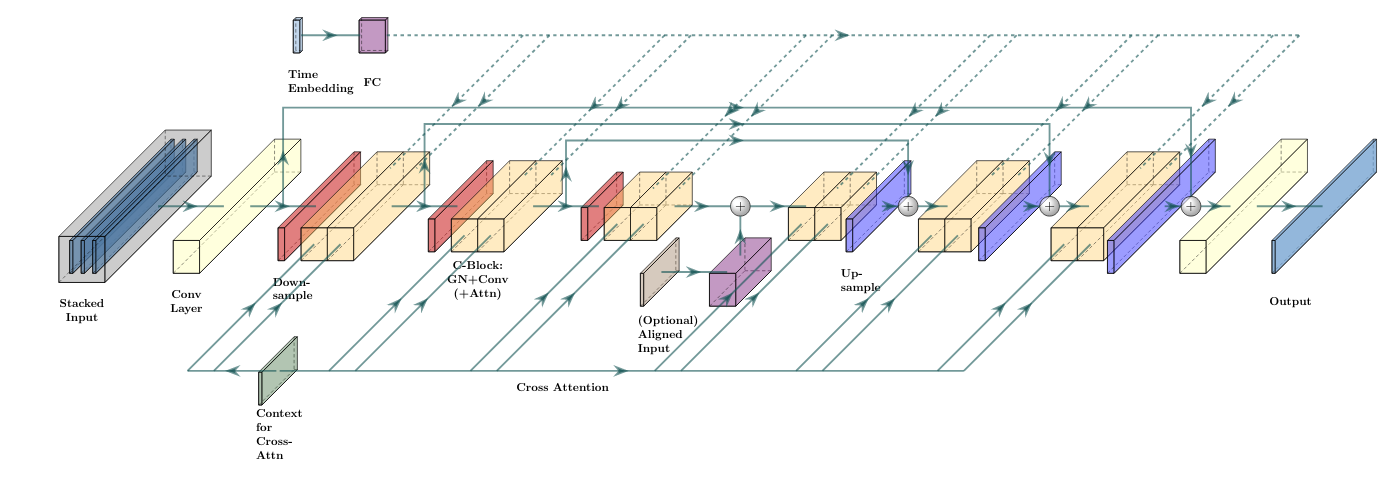
제안 방법
- 생성기(중간 표현을 출력)와 계단식 정제기를 포함하는 디퓨전 모델의 캐스케이드를 훈련하고, 이를 통해 고충실도 오디오를 산출합니다.
- 두 가지 중간 표현을 탐색합니다: (i) 로그-멜 스펙트로그램 및 (ii) 3.2 kHz 파형.
- 교차 주의(attention)로 텍스트를 사전 학습된 언어 모델 인코더(T5)와 연결하여 디퓨전 모델을 텍스트로 조건화합니다.
- 16 kHz 중간 오디오에서 24 kHz 오디오를 생성하기 위한 최종 초해상도 계단식 모듈을 사용합니다.
- MuLan-LM으로 의사 레이블링을 활용하여 대규모 텍스트-오디오 쌍을 만들고 MuLaMCap를 구성하여 학습 데이터 다양성을 확보합니다.
- 다양한 학습 및 증강 스키마 하에 4개의 1D U-Net 디퓨전 모델(파형 생성기, 파형 계단식, 스펙트로그램 생성기, 스펙트로그램 보코더)과 초해상도 계단식 모듈을 훈련합니다.
- 추론은 CFG, 전/후/전-중심 디노이징 스케줄 및 품질과 다양성의 균형을 맞추기 위한 조정된 확률적 요소를 사용합니다.
실험 결과
연구 질문
- RQ1확고한 충실도로 임의의 텍스트 프롬프트로 조건화된 긴(30초) 음악 클립을 디퓨전 기반 아키텍처가 생성할 수 있는가?
- RQ2대형 언어 모델과 음악-텍스트 임베딩으로 바인딩하면 생성 음악의 장르, 템포, 분위기, 시대와 같은 미세한 의미 속성에 대해 근거 있는 제어가 가능해지는가?
- RQ3스펙트로그램 대 파형과 같은 중간 표현이 텍스트 조건 음악 생성의 품질 및 의미 일치에 어떤 영향을 미치는가?
주요 결과
| 데이터셋/모델 | FAD VGG | FAD Trill | FAD MuLan | |
|---|---|---|---|---|
| MusicCaps (Agostinelli et al., 2023) | Riffusion | 13.371 | 0.763 | 0.487 |
| MusicCaps (Agostinelli et al., 2023) | Mubert (MubertAI, 2022) | 9.620 | 0.449 | 0.366 |
| MusicCaps (Agostinelli et al., 2023) | MusicLM (Agostinelli et al., 2023) | 4.0 | 0.44 | - |
| MusicCaps (Agostinelli et al., 2023) | Noise2Music Waveform | 2.134 | 0.405 | 0.110 |
| MusicCaps (Agostinelli et al., 2023) | Noise2Music Spectrogram | 3.840 | 0.474 | 0.180 |
| AudioSet-Music-Eval | Noise2Music Waveform | 2.240 | 0.252 | 0.193 |
| AudioSet-Music-Eval | Noise2Music Spectrogram | 3.498 | 0.323 | 0.276 |
| MagnaTagATune | Noise2Music Waveform | 3.554 | 0.352 | 0.235 |
| MagnaTagATune | Noise2Music Spectrogram | 5.553 | 0.419 | 0.346 |
- Noise2Music 모델은 장르, 템포, 악기, 분위기, 시대와 같은 상위 수준 및 미세한 프롬프트 속성을 반영하는 30초 오디오를 생산합니다.
- 중간 표현에 대한 생성기와 최종 오디오를 위한 계단식 2단계 디퓨전과 초해상도 단계가 높은 충실도 24 kHz 출력을 달성합니다.
- MuLan 및 LaMDA를 이용한 대규모 의사 레이블링은 표준 메타데이터를 넘어선 미묘한 의미의 바인딩을 가능하게 합니다.
- FAD 점수와 MuLan 유사도는 MusicCaps, AudioSet-Music-Eval, MagnaTagATune 등의 다중 데이터셋에서 Riffusion 및 Mubert와 비교해 경쟁력 있거나 우수한 품질 및 의미 정렬을 보여줍니다.
- 인간 청음 테스트에서 Noise2Music 파형은 MusicCaps 프롬프트에 대한 의미 정렬에서 MusicLM과 경쟁력이 있음을 시사합니다.
- 다중 어휘 의사 레이블 및 텍스트 인코딩(T5)과의 교차 주의로 프롬프트를 바인딩하면 지각적 및 의미적 충실도가 향상됩니다.
![Figure 2: We plot how $\text{FAD}_{\text{VGG}}$ and the MuLan similarity score vary as inference parameters are adjusted. The CFG parameters take values from [1, 2, 5, 10, 15], while “B”ack-heavy, “U”niform and “F”ront-heavy denoising step schedules have been applied.](https://ar5iv.labs.arxiv.org/html/2302.03917/assets/figures/ablations.png)
더 나은 연구,지금 바로 시작하세요
연구 설계부터 논문 작성까지, 연구 시간을 획기적으로 줄여보세요.
카드 등록 없음 · 무료 플랜 제공
이 리뷰는 AI가 만들고, 인간 에디터가 검토했습니다.